DFS
Generative Model
2026-01-11

💡 Flowbased Models Normalizing Flow Normalizing Flow 是一种基于变换对概率分布进行建模的模型,其通过一系列离散且可逆的变换实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow 训练完成后,就可以直接从高斯分布中进行采样,并通过逆变换得到原始分布中的样本,实现生成的过程。(有关 Normalizing Flow 的详细理论) 从这个角度看,Normalizing Flow 和 Diffusion Model 是有一些相通的,其做法的对比如下表所示。从表中可以看到,两者大致的过程是非常类似的,尽管依然有些地方不一样,但这两者应该可以通过一定的方法得到一个比较统一的表示。 Continuous Norma...
Generative Model
2026-01-11
技术分析 从方法上来看,条件控制生成的方式分两种:事后修改(ClassifierGuidance)和事前训练(ClassifierFree)。 对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以就想着直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现控制生成,这就是事后修改的ClassifierGuidance方案;而对于“财大气粗”的Google、OpenAI等公司来说,它们不缺数据和算力,所以更倾向于往扩散模型的训练过程中就加入条件信号,达到更好的生成效果,这就是事前训练的ClassifierFree方案。 ClassifierGuidance方案最早出自《Diffusion Models Beat GANs...
Generative Model
2026-01-11

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION5B也是开源的。SD在开源90天github仓库就收获了33K的stars,可见这个模型是多受欢迎。 SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 ...
计算几何(Computational Geometry),是一系列使用计算机解决几何问题的算法。与解析几何相比,计算几何更适合计算机运算,精度较高,运算速度较快,并且易于编写。 浮点误差 程序设计中,考虑到浮点数 double 有精度误差,在比较时,通常允许一定的误差,即对于两个数 a 、 b ,如果 [Math] ,则认为 a=b 。一般根据题目要求, d (代码中命名为 EPS)取一个较小值,如 10^{8} 。 [代码] 向量 向量(vector)是一个有大小和方向的量,在几何中,它被表示为带箭头的线段。向量可以用起点和终点的坐标来表示 —— 从点 A到点B 的向量表示为 [Math] 。 向量的书写,两个大写字母上加一个箭头(表示方向) [Math] 向量没有位置,即向量可以在平面内...
Generative Model
2026-01-11

ControlNet应该算是2023年文生图领域最重要的工作,它让文生图模型Stable Diffusion实现了文本之外的可控生成,让AI绘画实现了质的飞跃。这篇文章我们将简单总结一下ControlNet技术细节。 模型设计 ControlNet的模型结构如下所示,这里是直接复制一份SD的上半部分:Encoder和中间的Middle Block。 ControlNet的输入和原始的SD一样,包括noisy latents、time embedding以及text embedding。除此之外,ControlNet还需要引入额外的condition,这个condition是和原图一样大小的图像,比如canny边界图或者人体骨架图。这里并没有像SD那样采用VAE对condition进行编码,而...
Computer Vision
2026-01-11

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是Endtoend。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他...
Generative Model
2026-01-11

💡 随机微分 在DDPM中,扩散过程被划分为了固定的T步,还是用DDPM中的类比来说,就是“拆楼”和“建楼”都被事先划分为了T步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。 为此,我们用下述SDE描述前向过程(“拆楼”): [公式] 相信很多读者都对SDE很陌生,笔者也只是在硕士阶段刚好接触过一段时间,略懂皮毛。不过不懂不要紧,我们只需要将它看成是下述离散形式在 [Math] 时的极限: [公式] 再直白一点,如果假设拆楼需要1天,那么拆楼就是 [Math] 从 t=0 到 t=1 的变化过程,每一...
Generative Model
2026-01-11

🔖 https://stability.ai/news/stablediffusion3researchpaper 概述 SD3 模型与训练策略改进细节 SD3除了将去噪网络从 UNet 改成 DiT 外,SD3 还在模型结构与训练策略上做了很多小改进: 改变训练时噪声采样方法 将一维位置编码改成二维位置编码 提升 VAE 隐空间通道数 对注意力 QK 做归一化以确保高分辨率下训练稳定 本文会简单介绍这些改进。 论文阅读 核心贡献 介绍 Stable Diffusion 3 (SD3) 的文章标题为 Scaling Rectified Flow Transformers for HighResolution Image Synthesis。与其说它是一篇技术报告,更不如说它是一篇论文,因为它...
Computer Vision
2026-01-11

一、IOU(Intersection over Union) 1. 特性(优点) IoU就是我们所说的交并比,是目标检测中最常用的指标,在anchorbased的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和groundtruth的距离。 1. 可以说它可以反映预测检测框与真实检测框的检测效果。 1. 还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性) [代码] 2. 作为损失函数会出现的问题(缺点) 1. 如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重...
Computer Vision
2026-01-11

Introduction 目标检测中NMS需要依据候选检测目标的排序来进行筛选框,如果分类得分较低,但是定位框准确会导致在NMS中将该bbox框被排除掉,因此这个排序的可靠性就非常重要。之前的工作主要采用IOU分支(IOUNet)与Centerness得分(FCOS)来作为大量候选检测的排序依据。 然而,本文认为这些方法可以有效缓解分类得分和物体定位精度之间的不对齐问题。 但是,它们是次优解的,因为将两个不完善的预测相乘可能会导致排名依旧变差,作者经过试验表明,通过这种方法实现的性能上限非常有限。 此外,增加一个额外的网络分支来预测定位分数并不是一个很好的解决方案,并且会带来额外的计算负担。 基于上述分析,作者提出:不采用预测一个额外的定位精确度得分(IOUaware Centerness)...
Computer Vision
2026-01-11
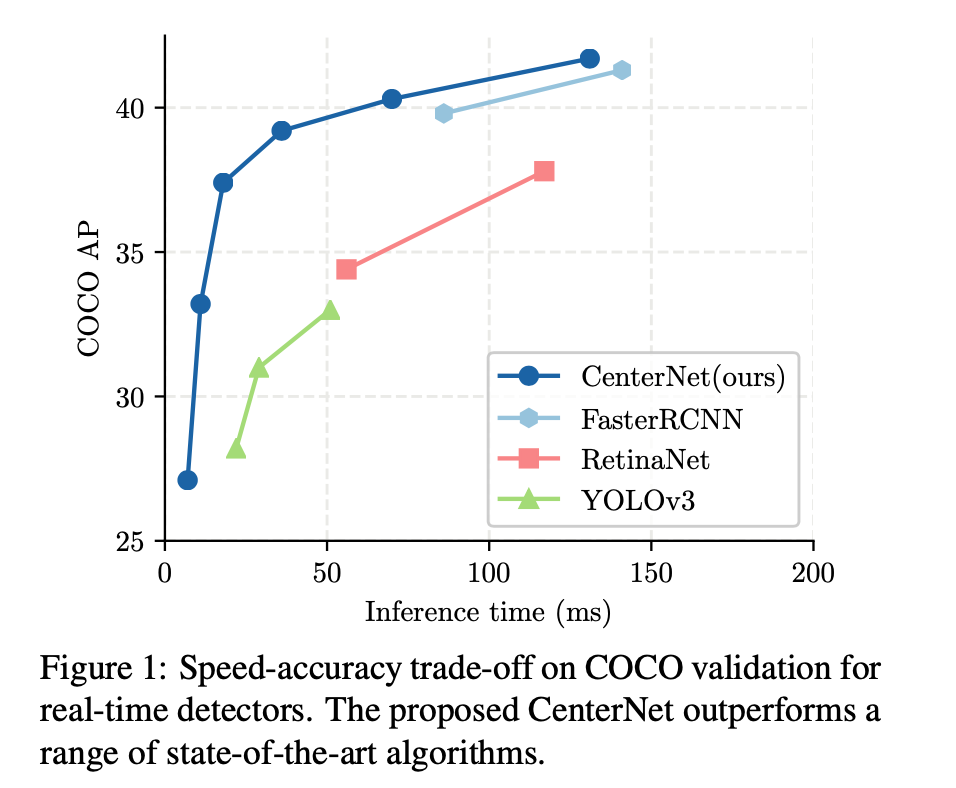
前言 anchorfree目标检测属于anchorfree系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于onestage和twostage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet的精度比YOLOv3提高了4个左右的点。 CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如肢体识别或者3D目标检测等等。 那CenterNet相比于之前的onestage和twostage的目标检测有什么特点? CenterNet的“anchor”仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是...