Computer Vision
2026-01-11
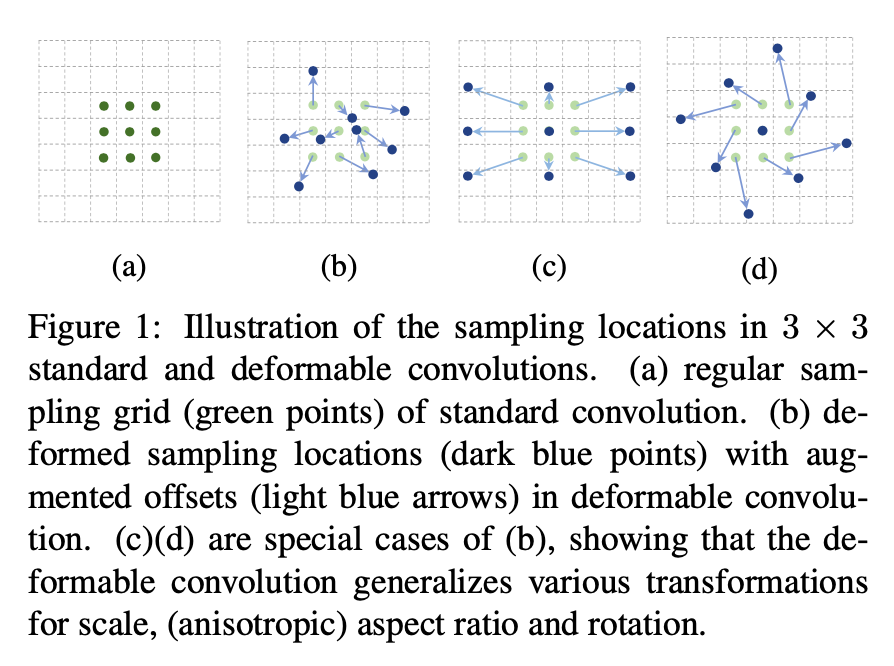
Deformable Conv v1 这篇文章其实比较老了,是 2017 年 5 月出的 1. Motivation 1.1 Task 上的难点 视觉任务中一个难点就是如何 model 物体的几何变换,比如由于物体大小,pose, viewpoint 引起的。一般有两类做法: 在数据集上做文章,让 training dataset 就包含所有可能的集合变换。通过 affine transformation 去做 augmentation 另一种就是设计 transformationinvariant (对那些几何变换不变)的 feature 和算法。比如 SIFT 和 sliding window 的方式。 文章说上述两种方式有问题,几何变换我们是事先知道的,这种不能 generalize ...