
论文地址: 🔖 https://arxiv.org/pdf/2107.11291 代码地址: 前言 一般来说,我们可以把姿态估计任务分成两个流派:Heatmapbased和Regressionbased。 其主要区别在于监督信息的不同,Heatmapbased方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或softargmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression...
Reinforcement Learning
2026-01-11

引言与背景 价值函数方法是强化学习中的核心技术,它解决了传统表格方法在处理大型状态或动作空间时的效率问题。本文探讨了从表格表示向函数表示的转变,这是强化学习算法发展的重要里程碑。 在强化学习的发展路径中,价值函数方法位于从基于模型到无模型、从表格表示到函数表示的演进过程中。它结合了时序差分学习的思想,并通过函数近似技术来处理复杂环境。 价值表示:从表格到函数 表格与函数表示的对比 传统的表格方法将状态值存储在一个表格中: 而函数近似方法则使用参数化函数来表示这些值,例如: [公式] 其中 [Math] 称作是状态 s 的特征向量, w 是参数向量。 两种不同的表现形式的区别主要体现在以下几个方面: 值的检索方式 值的更新方式 函数复杂度与近似能力 函数的复杂度决定了其近似的能力: 一阶线性函...
最优策略(Optimal Policy ) 之前在 贝尔曼方程中说过,状态值可以用来评估一个策略是好是坏,这里给出正式的概念: [公式] 那么此时 [Math] 比 [Math] ”更好“ 最优状态值(Optimal State Value): 最优策略(Optimal Policy): 性质: 为了说明上述性质, 我们研究贝尔曼最优方程 Bellman optimality equation(BOE) 贝尔曼最优方程(BOE) 定义 分析最优策略和最优状态值的工具是贝尔曼最优方程(BOE)。通过求解此方程,我们可以获得最优策略和最优状态值。 对于每个 s∈S ,BOE 的elementwise表达式为: [公式] 其中, v(s) 和 [Math] 是待求解的未知变量, π(s) 表示状态...
Reinforcement Learning
2026-01-11

概述与理论背景 ActorCritic方法是强化学习中的一类重要算法,它巧妙地结合了基于策略(policybased)和基于价值(valuebased)的方法。在这种结构中,"Actor"指策略更新步骤,负责根据策略执行动作;而"Critic"指价值更新步骤,负责评估Actor的表现。从另一个角度看,ActorCritic方法本质上仍是策略梯度算法,可以通过扩展策略梯度算法获得。 ActorCritic方法在强化学习中的位置非常重要,它既保留了策略梯度方法直接优化策略的优势,又利用了值函数方法的效率。这种结合使得ActorCritic方法成为解决复杂强化学习问题的强大工具。 最简单的ActorCritic算法(QAC) QAC算法通过扩展策略梯度方法得到。策略梯度方法的核心思想是通过最大化标...
Reinforcement Learning
2026-01-11
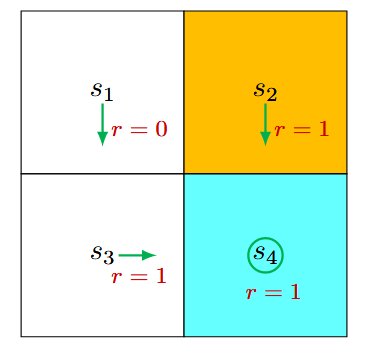
状态价值(State values) 定义 状态价值是强化学习中的核心概念,用于衡量Agent从某个状态出发、遵循特定策略后所能获得的期望回报。 数学表达为: [公式] 其中: [Math] :状态 s 的状态价值函数(statevalue function) 或者简称为 状态价值(state value); [Math] :智能体遵循的策略; [Math] :从当前时间步 t 开始的折扣回报; [Math] :折扣因子,用于平衡即时奖励和未来奖励。 状态价值的特点 依赖于状态 s :状态价值是条件期望,条件是智能体从状态 s 开始。 依赖于策略 [Math] :不同策略会生成不同的轨迹,从而影响状态价值。 与时间步无关:状态价值是一个固定值,与当前时间步 t 无关。 代表一个状态的价值。如...
Large Model
2026-01-11

概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 D = \{(x_i, y^_i)\}_{i=1}^n ,其中包含问题 x_i 和对应的真实答案 y^_i ,目标是训练一个策略模型 [Math] 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 z = (z_1, z_2, ..., z_m) 来连接问题 x 和答案 y ,每个 z_i 是解决问题的重要中间步骤。 当解决问题 x 时,思维 [Math] 被自回归采样,最终答案 [Math] 。 强化学习目标 基于真实答案 y^ ,分配一个值 [Math] , Ki...

💡 引言 Trust Region Policy Optimization (TRPO) 是2015年的ICML会议上提出的一种强大的基于策略的强化学习算法。TRPO 解决了传统策略梯度方法中的一些关键问题,特别是训练不稳定和步长选择困难的问题。与传统策略梯度算法相比,TRPO 具有更高的稳健性和样本效率,能够在复杂环境中取得更好的性能。 优化基础 在深入了解 TRPO 之前,我们需要先简单回顾一些优化方法的基础知识。 梯度上升法 梯度上升法是一种迭代优化算法,用于寻找函数的局部最大值。 目标:找到使目标函数 [Math] 最大化的参数 [Math] : [公式] 梯度上升迭代过程: 1. 在当前参数 [Math] 处计算梯度: [Math] 1. 更新参数: 梯度上升法的主要问题是学习率的...
3D Model
2026-01-11
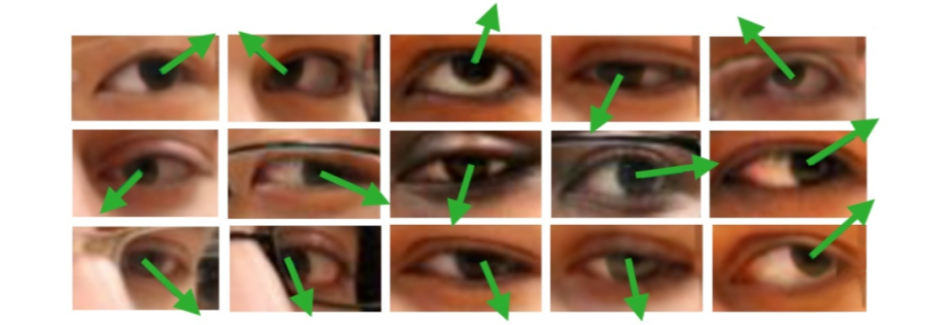
概述 问题定义 广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。 gaze角度的表示一般使用一个3d向量作为表示,也可以转换为pitch 和yaw角度,具体可参考 Model Gaze模型一般使用回归模型,所以这里基本只介绍一些在gaze model中使用的小技巧 Rle Loss 实际问题
Reinforcement Learning
2026-01-11

引言 时序差分(TemporalDifference,TD)方法是强化学习中的一类核心算法,它结合了动态规划与蒙特卡洛方法的优点。TD方法是无模型(modelfree)学习方法,不需要环境模型即可学习价值函数和最优策略。 TD方法的核心特点是通过比较不同时间步骤的估计值之间的差异来更新价值函数,这种差异被称为"时序差分误差"(TD error)。TD方法可以被视为解决贝尔曼方程或贝尔曼最优方程的特殊随机逼近算法。 基础TD算法:状态值函数学习 给定策略 [Math] ,基础TD算法用于估计状态值函数 [Math] 。假设我们有一些按照策略 [Math] 生成的经验样本 (s_0, r_1, s_1, ..., s_t, r_{t+1}, s_{t+1}, ...) ,TD算法的更新规则为: ...
Reinforcement Learning
2026-01-11

引言 强化学习中,找到最优策略是核心目标。本文详细介绍三种能够找到最优策略的基础算法:价值迭代、策略迭代和截断策略迭代。这些算法属于动态规划范畴,需要系统模型,是后续无模型强化学习算法的重要基础。 在强化学习的发展路线中,这些算法处于"基础工具"到"算法/方法"的过渡阶段,是从"有模型"到"无模型"学习的重要桥梁。 价值迭代(Value iteration) 价值迭代算法基于收缩映射定理求解贝尔曼最优方程。其核心迭代公式为: [公式] 根据收缩映射定理,当 [Math] 时, v_k 和 [Math] 分别收敛到最优状态值和最优策略。 每次迭代包含两个步骤: 1. 策略更新步骤 (policy update step):找到能解决以下优化问题的策略 1. 价值更新步骤(value updat...