Computer Vision
2026-01-11

空洞卷积 Dilated/Atrous Convolution 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyperparameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。 一个简单的例子 一维情况下空洞卷积的公式如下 [Formula] 不过光理解他的工作原理还是...
Computer Vision
2026-01-11
PA Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。 [公式] 图像中共有k+1(包含背景)类, p_{ii} 表示将第i类分成第 i 类的像素数量(正确分类的像素数量), p_{ij} 表示将第 i 类分成第 j 类的像素数量(所有像素数量) 因此该比值表示正确分类的像素数量占总像素数量的比例。 优点:简单 缺点:如果图像中大面积是背景,而目标较小,即使将整个图片预测为背景,也会有很高的PA得分,因此该指标不适用于评价以小目标为主的图像分割效果。 MPA Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。 [公式] MIoU Mean Interse...
Algorithm
2026-01-11

题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出:5 解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root...
Algorithm
2026-01-11
题目 Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array. Note: The number of elements initialized in nums1 and nums2 are m and n respectively. You may assume that nums1 has enough space (size that is equal to m + n) to hold additional elements from nums2. Example: [代码] Constraints: 10^9 <= nums1[i], nums2[i] <...
Computer Vision
2026-01-11
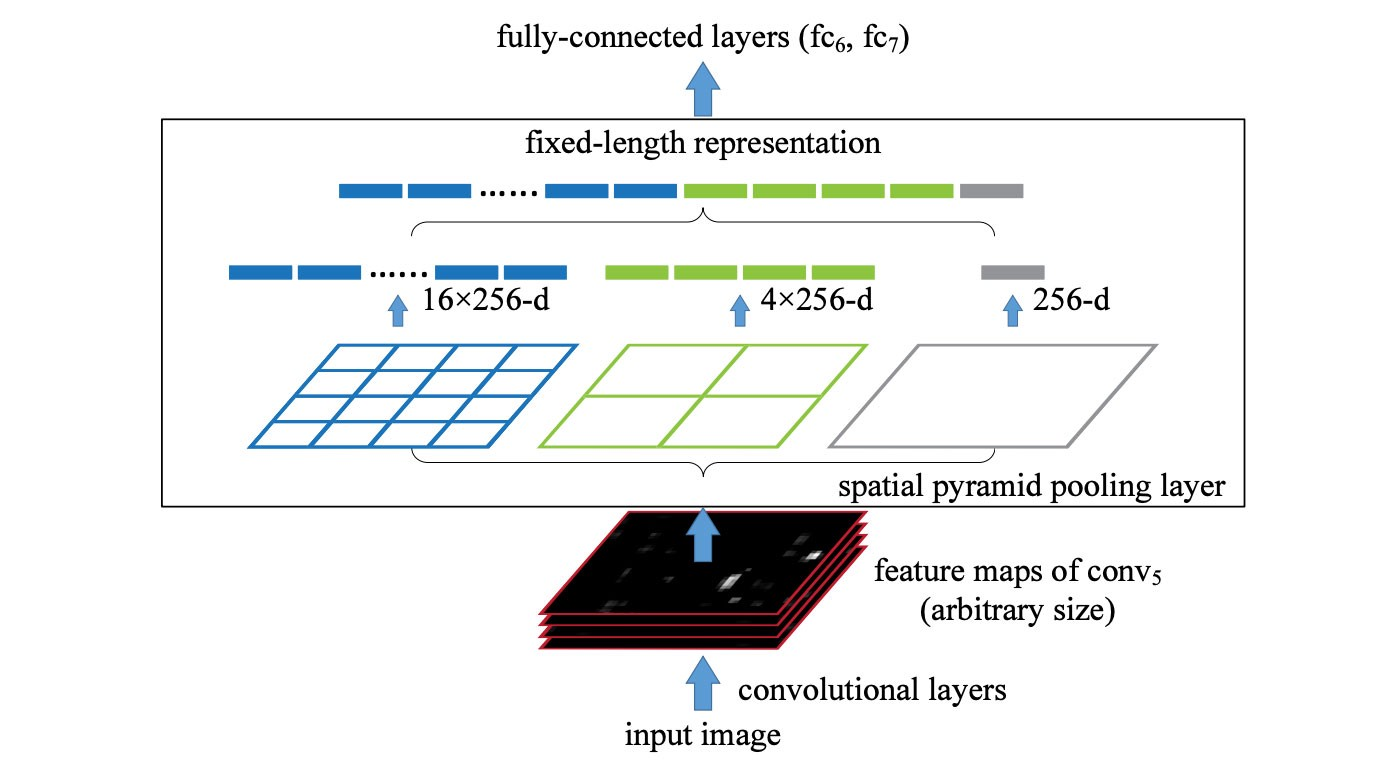
SPP (spatial pyramid pooling layer) SPP applies a slightly different strategy in detecting objects of different scales. It replaces the last pooling layer (after the last convolutional layer) with a spatial pyramid pooling layer. The feature maps are spatially divided into m×m bins with m, say, equals 1, 2, and 4 respectively. Then a maximum pool i...
DFS
Deep Learning
2026-01-11

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 X ,其取值来自有限集合 [Math] 。我们的目标是估计 E[X] 。假设我们有一个独立同分布的样本序列 \{x_i\}_{i=1}^n ,那么 X 的期望值可以近似为: [公式] 非增量方法与增量方法 非增量方法:先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法:定义 [公式] 可以推导出递归公式: [公式] 这个算法可以增量式地...
Reinforcement Learning
2026-01-11

引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为:如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 X 中值的随机变量 X ,我们的任务是计算 X 的均值或期望值: E[...
Reinforcement Learning
2026-01-11

基础概念 GridWord Example 环境描述:网格世界是一个直观的二维环境,包含: 任务目标: 什么是强化学习:依据策略执行动作感知状态得到奖励 所谓强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。 a computational approach to learning whereby an agent tries to maximize the total amount of reward it receives while interacting with a complex and uncertain environment 经典的强化学习模型可以总结为下图的形式(你可以理解...
背景 RLHF 通常包括三个阶段: 有监督微调(SFT) 奖励建模阶段 (Reward Model) RL微调阶段 直接偏好优化(DPO) 传统的RLHF方法分两步走: 1. 先训练一个奖励模型来判断哪个回答更好 1. 然后用强化学习让语言模型去最大化这个奖励 这个过程很复杂,就像绕了一大圈:先学习"什么是好的",再学习"如何做好"。 DPO发现了一个数学上的捷径: 1. 关键发现:对于任何奖励函数,都存在一个对应的最优策略(语言模型);反过来说,任何语言模型也隐含着一个它认为最优的奖励函数 1. 直接优化:与其先训练奖励模型再训练语言模型,不如直接训练语言模型,让它自己内化"什么是好的" 1. 数学转换:DPO将"学习判断好坏"和"学习生成好内容"这两个任务合二为一,通过一个简单的数学变换...