
一、泊松分布 日常生活中,大量事件是有固定频率的。 某医院平均每小时出生3个婴儿 某公司平均每10分钟接到1个电话 某超市平均每天销售4包xx牌奶粉 某网站平均每分钟有2次访问 它们的特点就是,我们可以预估这些事件的总数,但是没法知道具体的发生时间。已知平均每小时出生3个婴儿,请问下一个小时,会出生几个? 有可能一下子出生6个,也有可能一个都不出生。这是我们没法知道的。 泊松分布就是描述某段时间内,事件具体的发生概率。 [Formula] 上面就是泊松分布的公式。等号的左边, P 表示概率, N 表示某种函数关系, t 表示时间, n 表示数量,1小时内出生3个婴儿的概率,就表示为 P(N(1...
Reinforcement Learning
2026-01-11

引言 时序差分(TemporalDifference,TD)方法是强化学习中的一类核心算法,它结合了动态规划与蒙特卡洛方法的优点。TD方法是无模型(modelfree)学习方法,不需要环境模型即可学习价值函数和最优策略。 TD方法的核心特点是通过比较不同时间步骤的估计值之间的差异来更新价值函数,这种差异被称为"时序差分误差"(TD error)。TD方法可以被视为解决贝尔曼方程或贝尔曼最优方程的特殊随机逼近算法。 基础TD算法:状态值函数学习 给定策略 [Math] ,基础TD算法用于估计状态值函数 [Math] 。假设我们有一些按照策略 [Math] 生成的经验样本 (s_0, r_1, s_1, ..., s_t, r_{t+1}, s_{t+1}, ...) ,TD算法的更新规则为: ...
Large Model
2026-01-11

概述 MTP(Multitoken Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1token的生成,转变成multitoken的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个...
NLP
2026-01-11
概述 HiPPO(Highorder Polynomial Projection Operators)是目前大热的structured state space model (S4)及其后续工作的backbone. State space mode主要是控制学科里的内容,最近被引入深度学习领域来解决长距离依赖问题。长距离依赖建模的核心问题是如何通过有限的memory来尽可能记住之前所有的历史信息。当前的主流序列建模模型(即Transformer和RNN) 存在着普遍的遗忘问题 fixedsize context windows: Transformer的window size通常是有限的,一般来说quadratic的attention最多建模到大约10k的token就到计算极限了 vanish...
Large Model
2026-01-11

简介 🔖 https://bagelai.org/ BAGEL 模型原生支持统一的多模态理解和生成,是一个 decoderonly 的模型,BAGEL 在包含文本、图像、视频和网络数据的大量多模态数据上进行了预训练,包括数万亿 tokens。尽管有一些研究尝试扩展其统一模型,但它们主要仍然依赖于标准图像生成和理解任务中的图像文本配对数据进行训练。 然而,最近的研究发现,学术模型与 GPT4o 和 Gemini 2.0 等专有系统在统一多模态理解和生成方面存在显著差距,而这些专有系统的底层技术并未公开。作者认为,弥合这一差距的关键在于使用精心构建的多模态交错数据进行规模化训练。这种多模态交错数据整合了文本、图像、视频和网络来源。通过使用这种多样化的多模态交错数据进行扩展时,模型展现出复杂的、新...
Large Model
2026-01-11

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地...
Reinforcement Learning
2026-01-11
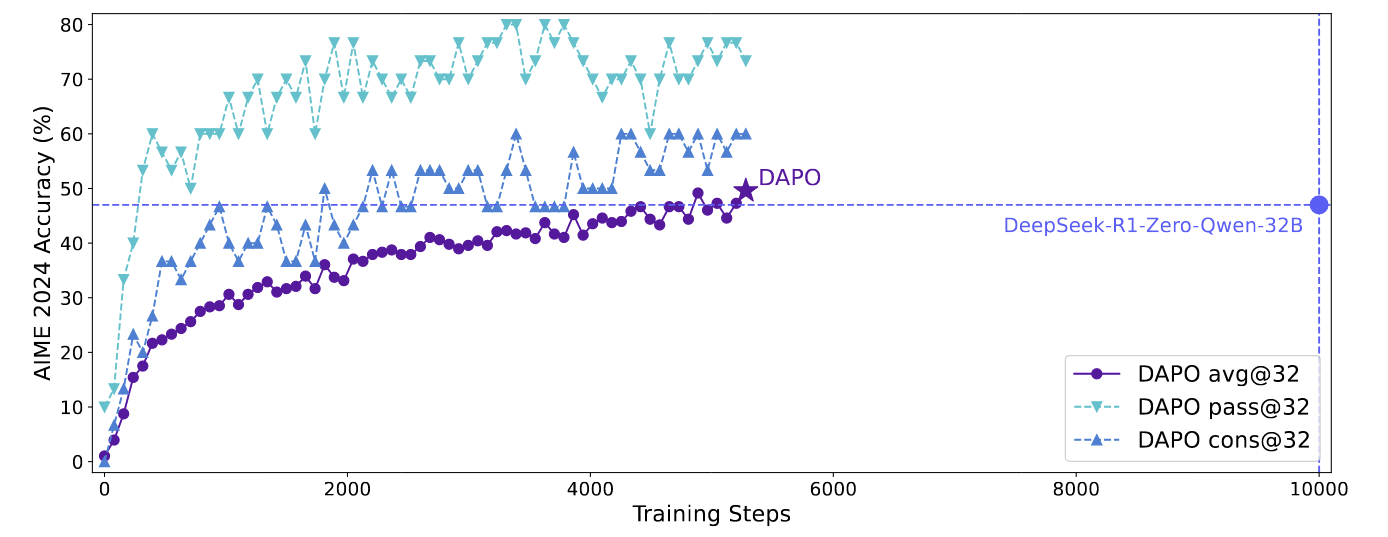
回顾 PPO [公式] 其中 (q, a) 是 数据集 [Math] 中采样的 questionanswer pair, [Math] 是重要性采样比的clip范围, [Math] 是时间步 t 的优势估计量. 给定 value function V 和 reward function R , [Math] 使用广义优势估计 (GAE) 来计算: [公式] 其中, [公式] GRPO 相比于 PPO, GRPO 去掉了value function 并以分组的方式估计优势。对于特定的问答对 (q, a), behavior policy [Math] 生成了一组 G 个 response \{o...