
概括 这篇文章将卷积比较自然地拓展到点云的情形,思路很赞! 文章的主要创新点:“weight function”和“density function”,并能实现translationinvariance和permutationinvariance,可以实现层级化特征提取,而且能自然推广到其deconvolution的情形实现分割,在二维CIFAR10图像分类任务中精度堪比CNN(表明能够充分近似卷积网络),达到了SOTA的性能。 缺点:每个kernel都需要由“kernel function”生成,而“kernel function”实质上是一个CNN网络,计算量比较大。 思想 察觉到:二维卷积中pixel的相对centroid位置与kernel vector的生成方式有关。 以二维卷积为例...

Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用(r, θ)两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的(r, θ),在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数(r, θ)就在每条曲线中都存在,所以看起来就像是多条曲线相交在(r,θ)。可以用多条曲线投票的方式来看,其他点都是很少的票数,而(r,θ)则票数很多,所以直线的参数就是(r,θ)。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数...
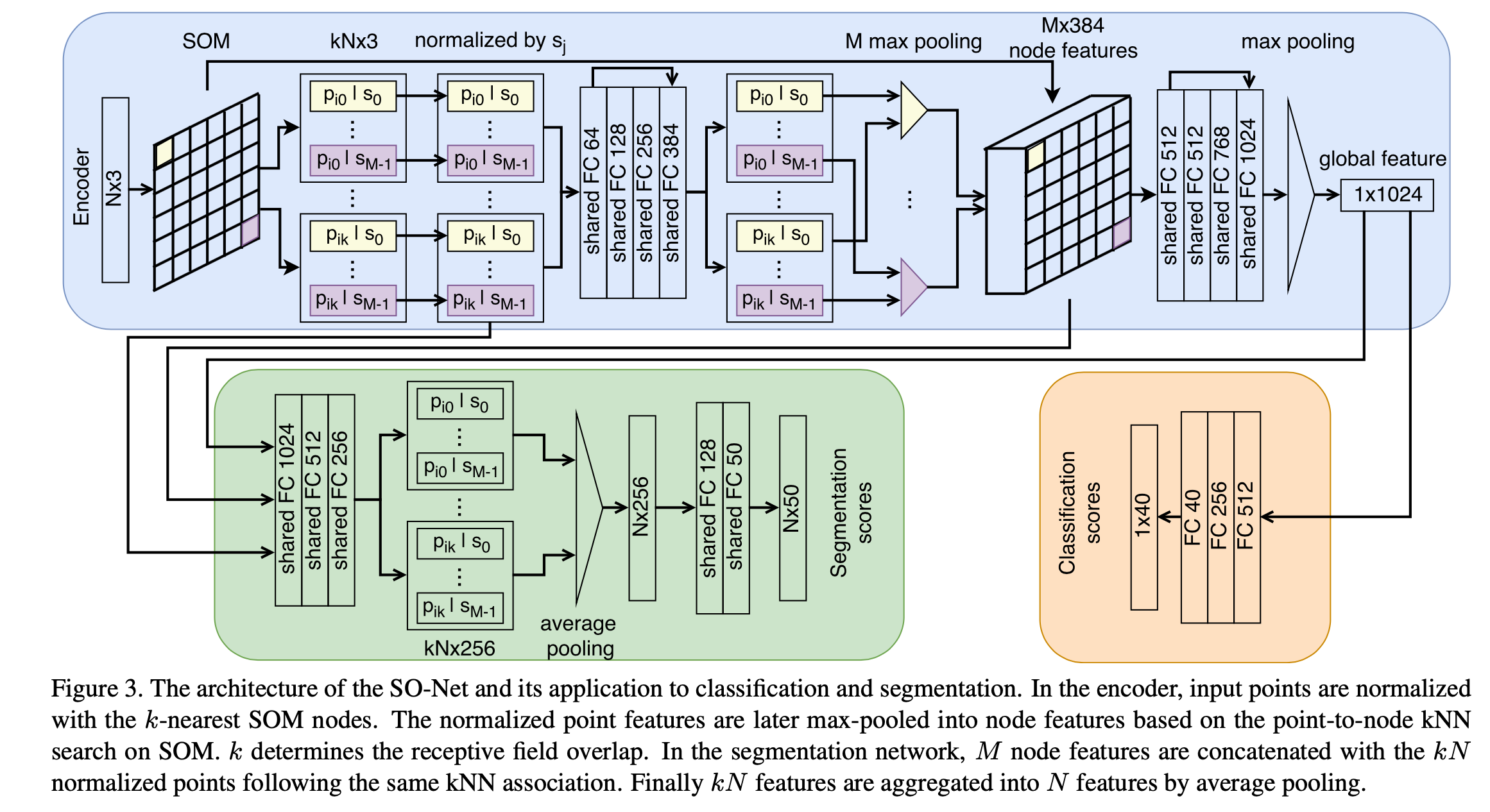
概括 针对一些网络在处理point cloud时的缺点,如:不能对点的空间分布进行建模(例如PointNet++,只是能获取局部信息不能得到局部区域之间的空间关系),提出了SONet。SO的含义是利用Selforganizing map的Net。 结果:它具有能够对点的空间分布进行建模、层次化特征提取、可调节的感受野范围的优点,并能够用于多种任务如重建、分类、分割等等。取得了相似或超过SOTA的性能,因为可并行化和架构简单使得训练速度很快。 贡献: TODO IDEA:作者发现将CNN直接用于SOM图上性能不升反降,为什么(推测:可能是SOM的2D map并不是保持了原本的空间对应关系,可能nodes之间是乱序的,导致用conv2d时精度反而降低)? 难点 如何对local regions之...
3D Model
2026-01-11
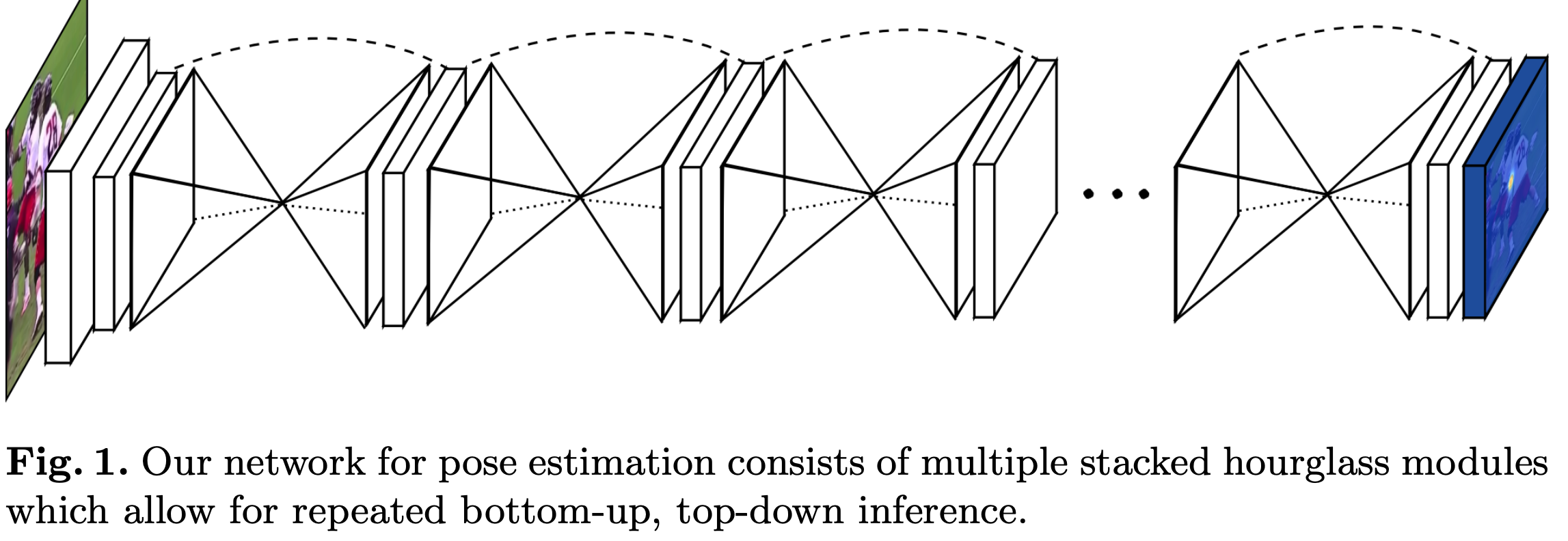
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottomup、topdown过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottomup过程将图片从...
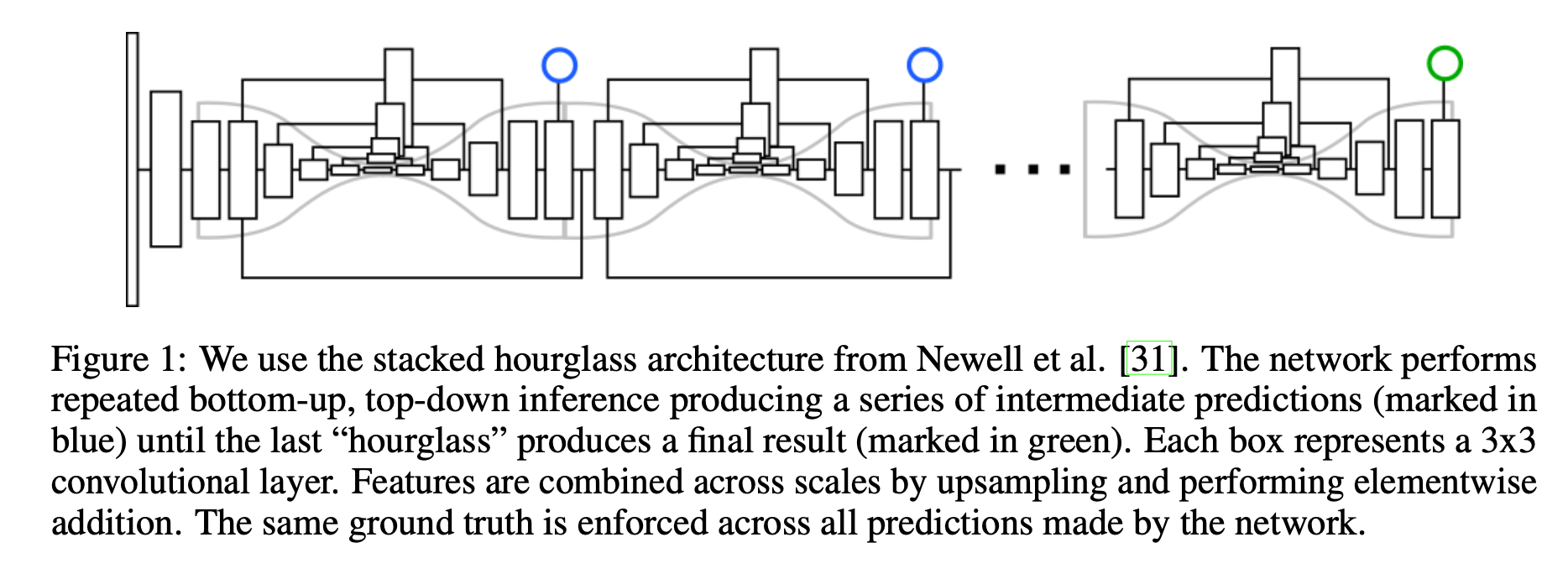
简介 作者认为许多计算机视觉的任务可以看作是检测和分组问题检测一些小的单元,然后将它们组合成更大的单元,例如,多人目标检测可以通过检测人的关节点然后再将它们进行分组(属于同一个人的关节点为一组)解决;实例分割问题可以看作是检测一些相关的像素然后将它们组合成一个目标实例。 Associative Embedding是一种表示关节检测和分组任务的输出的新方法,其基本思想是为每次检测引入一个实数,用作识别对象所属组的“tag”,换句话说,标签将每个检测与同一组中的其他检测相关联。作者使用一个损失函数使得如果相应的检测属于ground truth中的相同组则促使这一对标签具有相似的值。需要注意的是,这里标签具体的值并不重要,重要的是不同标签之间的差异。 这篇其实是源自Stacked Hourglas...
3D Model
2026-01-11

整体流程: [代码] 0. 数据预处理 这个步骤主要是crop四路数据,及生成后续步骤所需要的yaml文件。 1. 四路相机与双路相机标定 内参标定 [代码] 这里主要的函数就是: pts = cv2.findChessboardCorners(img, (board_width, board_height))[1] cv2.cornerSubPix(gray, pts, (12, 12), (1, 1), (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_COUNT, 30, 0.1)) det, intr, dist, _, _ = cv2.calibrateCamera(obj_pts, img_pts, self.imgSize, None, No...
Deep Learning
2026-01-11

最近,似乎现在每个大型语言模型(LLM)和新闻中提到的复杂神经网络架构都使用略有不同的激活函数,而就在几年前,最常见的做法只是在神经网络的内部层中使用 ReLU。 曾经优秀的 ReLUs 怎么了,以及是什么促使最新的大型语言模型(LLMs)的创造者们开始使用不同的(更高级的)激活函数? Threshold activation (Perceptron) 1957 年,罗森布拉特建造了“感知机” 最古老的激活函数是基本感知器。它由芝加哥大学精神病学系的爱德华·麦克洛奇和沃尔特·皮茨构思,后来由弗兰克·罗森布拉特在 1957 年于康奈尔航空实验室为美国海军在硬件上更著名地实现了。该算法非常简单,其基本规则是:如果某个值超过某个阈值,则返回 1,否则返回 0。有些变体会返回 1 或1。 由于其二元...
Computer Vision
2026-01-11
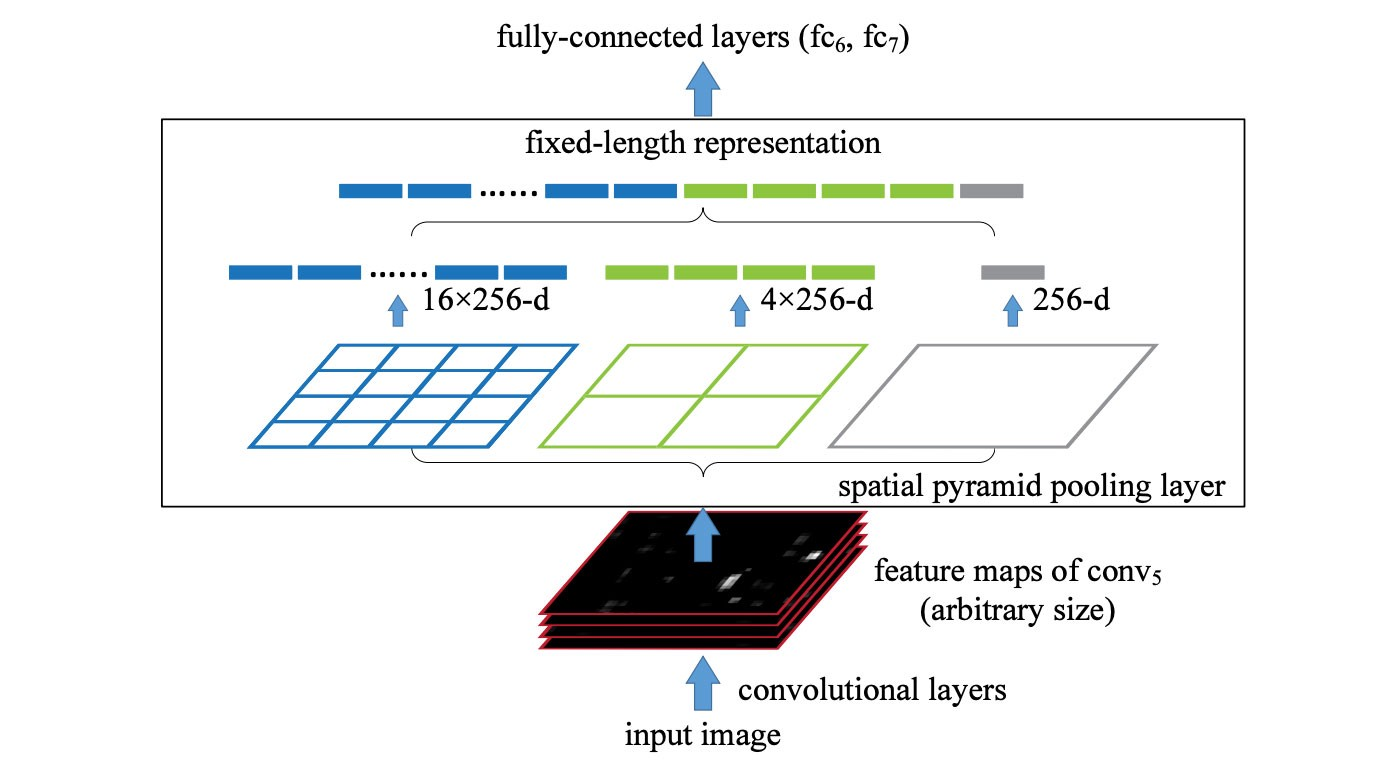
SPP (spatial pyramid pooling layer) SPP applies a slightly different strategy in detecting objects of different scales. It replaces the last pooling layer (after the last convolutional layer) with a spatial pyramid pooling layer. The feature maps are spatially divided into m×m bins with m, say, equals 1, 2, and 4 respectively. Then a maximum pool i...
Deep Learning
2026-01-11

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 X ,其取值来自有限集合 [Math] 。我们的目标是估计 E[X] 。假设我们有一个独立同分布的样本序列 \{x_i\}_{i=1}^n ,那么 X 的期望值可以近似为: [公式] 非增量方法与增量方法 非增量方法:先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法:定义 [公式] 可以推导出递归公式: [公式] 这个算法可以增量式地...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...
Computer Vision
2026-01-11

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是Endtoend。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他...
Deep Learning
2026-01-11

AdamW目前是大语言模型训练的默认优化器,而大部分资料对Adam跟AdamW区别的介绍都不是很明确,在此梳理一下Adam与AdamW的计算流程,明确一下二者的区别。 TLDR:AdamW将优化过程中使用的针对网络权重的衰减项(或者叫正则项)从loss中单独拿了出来,不参与Adam中一二阶动量的计算。 下面是二者的详细对比: Adam 首先是Adam,给定在迭代步数 t 时模型的参数 [Math] 与梯度 g_t ,Adam的计算公式如下: [公式] 式(1)用于计算梯度的一阶指数滑动平均 式(2)用于计算梯度的二阶项的指数滑动平均 式(3)与(4)对计算得到的指数滑动平均值进行消偏 式(5)为Adam的更新公式,其可以拆成两部分理解:动量更新与自适应学习率。 AdamW AdamW 相对与...