Computer Vision
2026-04-15
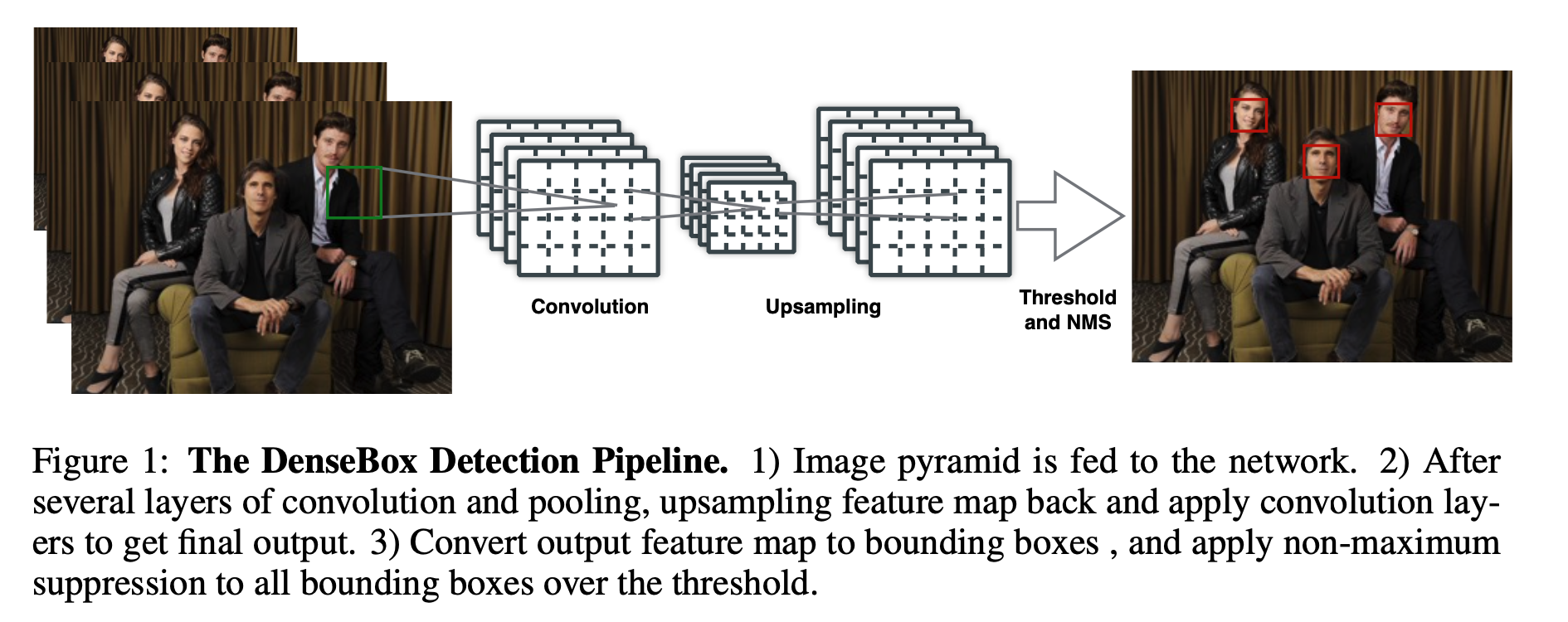
简介 "Anchor-free"(无锚点)是一种目标检测方法,与传统的使用锚框(anchor boxes)的方法(例如Faster R-CNN)不同。在传统方法中,锚框是预先定义的、具有不同尺寸和长宽比的矩形区域,用于捕捉不同尺寸和形状的目标。而在"anchor-free"方法中,不再使用锚框,而是直接预测目标的位置和形状,通常使用网络输出的热图和偏移信息。 以下是对"anchor-free"方法的一些关键理解点: 无需预定义锚框: 在传统目标检测方法中,需要事先定义和生成一组锚框,这可能需要大量的人工工作。而在"anchor-free"方法中,不再需要锚框,模型可以自动学习目标的位置和形状。 直接位置和形状回归: "anchor-free"方法通过输出的热图来表示目标的存在概率,并使用偏移信息来定位目标的中心和形状。这些热图和偏移信息通常通过卷积神经网络预测。 适用于不规则目标: 传统的锚框在捕捉不规则形状的目标时可能会有困难,而"anchor-free"方法可以更好地适应不规则目标的检测。 减少计算复杂性:...