Large Model
2026-01-11
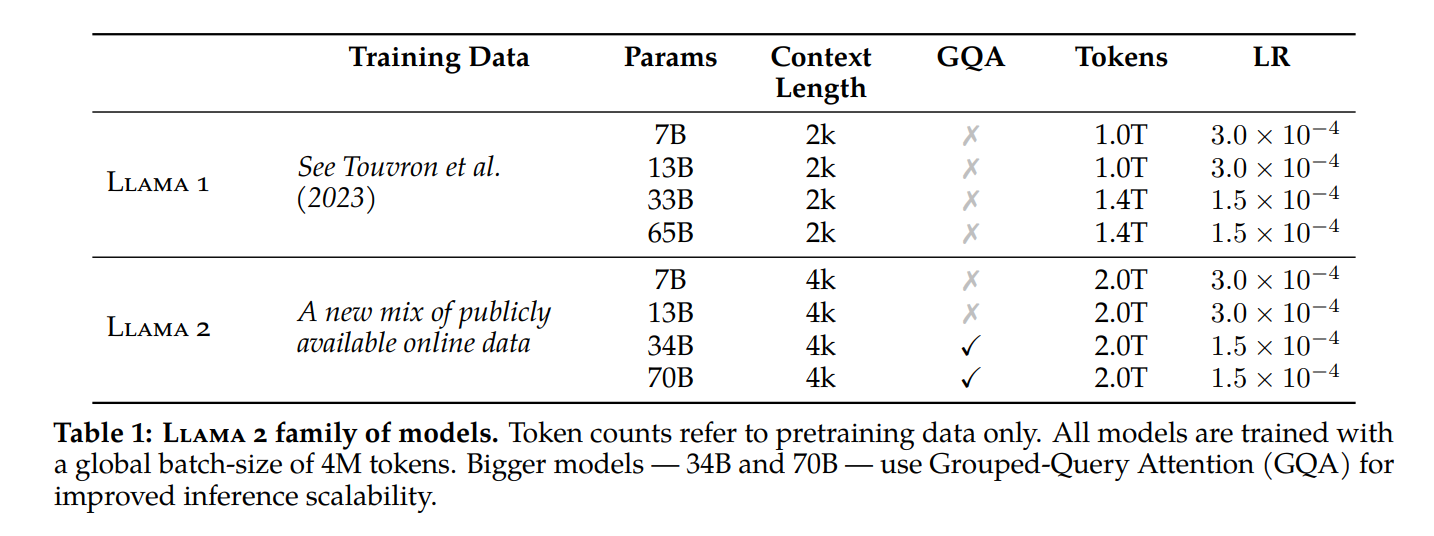
简介 模型结构 32K词表大小 2T训练数据 4K上下文长度 模型种类:7B、13B、70B(用了GQA) LLaMA 2Chat:三个版本——7B 13B 70B 同时 Meta 还发布了 LLaMA 2CHAT,其是基于 LLAMA 2 针对对话场景微调的版本,同样 7B、13B 和 70B 参数三个版本,具体的训练方法与ChatGPT类似 1. 先是监督微调LLaMA2得到SFT版本 (接受了成千上万个人类标注数据的训练,本质是问题答案对 ) 1. 然后使用人类反馈强化学习(RLHF)进行迭代优化 先训练一个奖励模型 然后在奖励模型/优势函数的指引下,通过拒绝抽样(rejection sampling)和近端策略优化(PPO)的方法迭代模型的生成策略 LLAMA 2 的性能表现更加接近...







