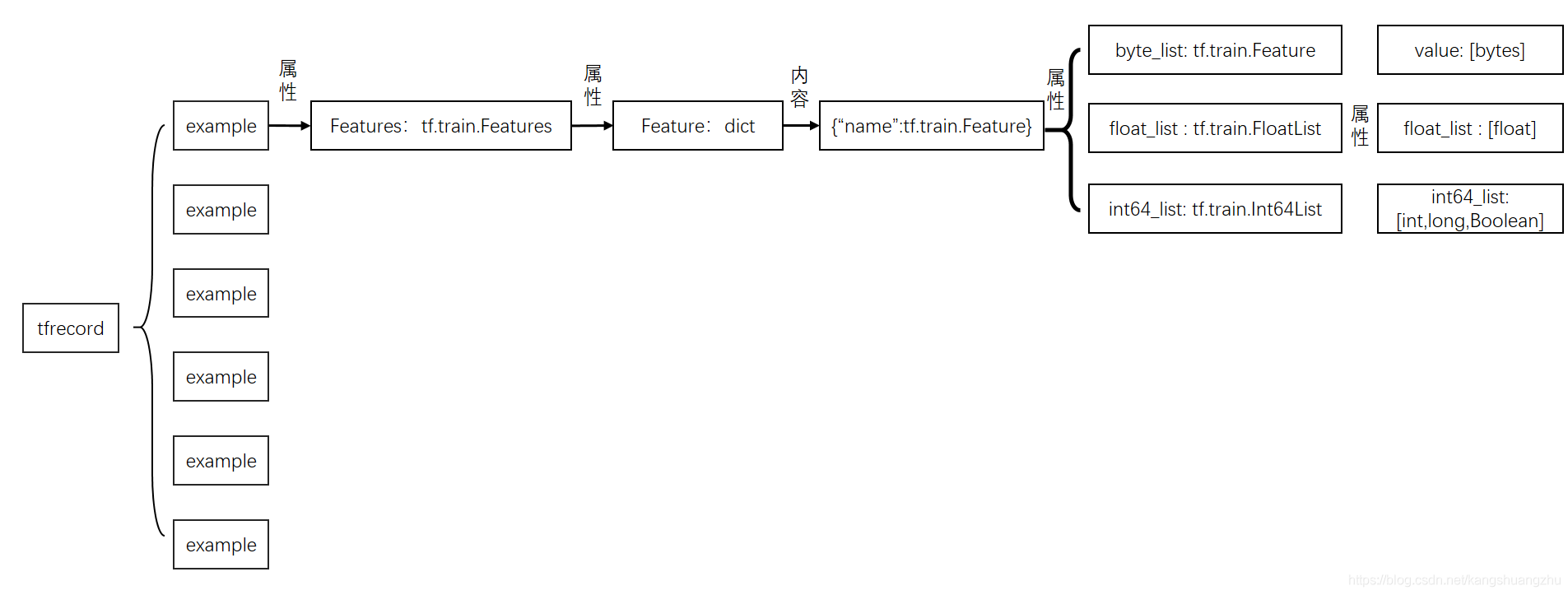
Machine Learning
2026-01-11
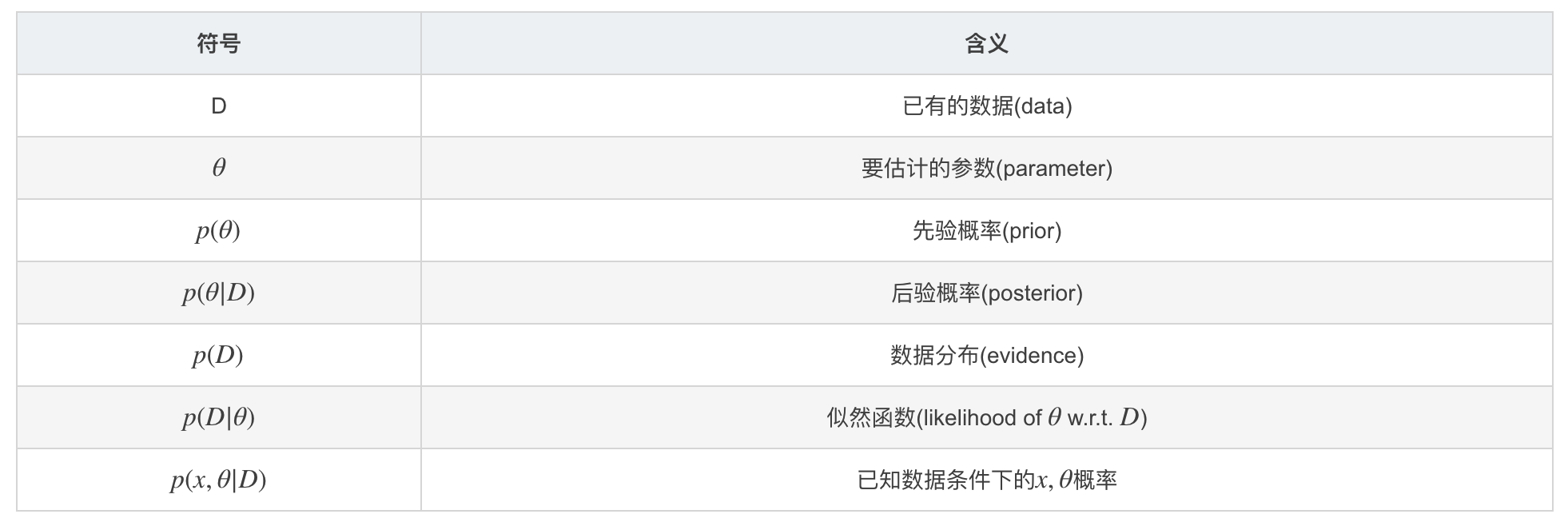
序言 极大似然估计与贝叶斯估计是统计中两种对模型的参数确定的方法,两种参数估计方法使用不同的思想。前者来自于频率派,认为参数是固定的,我们要做的事情就是根据已经掌握的数据来估计这个参数;而后者属于贝叶斯派,认为参数也是服从某种概率分布的,已有的数据只是在这种参数的分布下产生的。所以,直观理解上,极大似然估计就是假设一个参数 θ ,然后根据数据来求出这个 θ . 而贝叶斯估计的难点在于 p(θ) 需要人为设定,之后再考虑结合MAP(maximum a posterior)方法来求一个具体的 θ . 所以极大似然估计与贝叶斯估计最大的不同就在于是否考虑了先验,而两者适用范围也变成了:极大似然估计适用于数据大量,估计的参数能够较好的反映实际情况;而贝叶斯估计则在数据量较少或者比较稀疏的情况下,考虑...