
Pycharm 的图形化界面虽然好用,但是在某些场景中,是无法使用的。而 Python 本身已经给我们提供了一个调试神器 pdb. 准备文件 在调试之前先将这两个文件准备好(做为演示用),并放在同级目录中。 utils.py [代码] pdb_demo.py [代码] 进入调试模式 主要有两种方法 做为脚本调用,方法很简单,就像正常执行python脚本一样,只是多加了m pdb [代码] 使用这个方式进入调试模式,会在脚本的第一行开始单步调试。 对于单文件的脚本并没有什么问题,如果是一个大型的项目,项目里有很多的文件,使用这种方式只能大大降低我们的效率。 一般情况下,都会直接在你需要的地方打一个断点,那如何打呢? 只需在你想要打断点的地方加上这两行。 [代码] 然后执行时,也不需要再指定m ...
Python
2026-01-11
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程。在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现 python2中经典类和新式类的继承方式不同,经典类采用深度优先搜索的继承,新式类采用的是广度优先搜索的继承方式 python3中经典类和新式类的继承方式都采用的是都采用广度优先搜索的继承方式 [代码] [代码] 举个例子来说明:现有4个类,A,B,C,D类,D类继承于B类和C类,B类与C类继承于A类。class D(B,C) 实例化D类 深度优先 现在构造函数的继承情况为: 若D类有构造函数,则重写所有父类的继承 若D类没有构造函数,B类有...
Machine Learning
2026-01-11
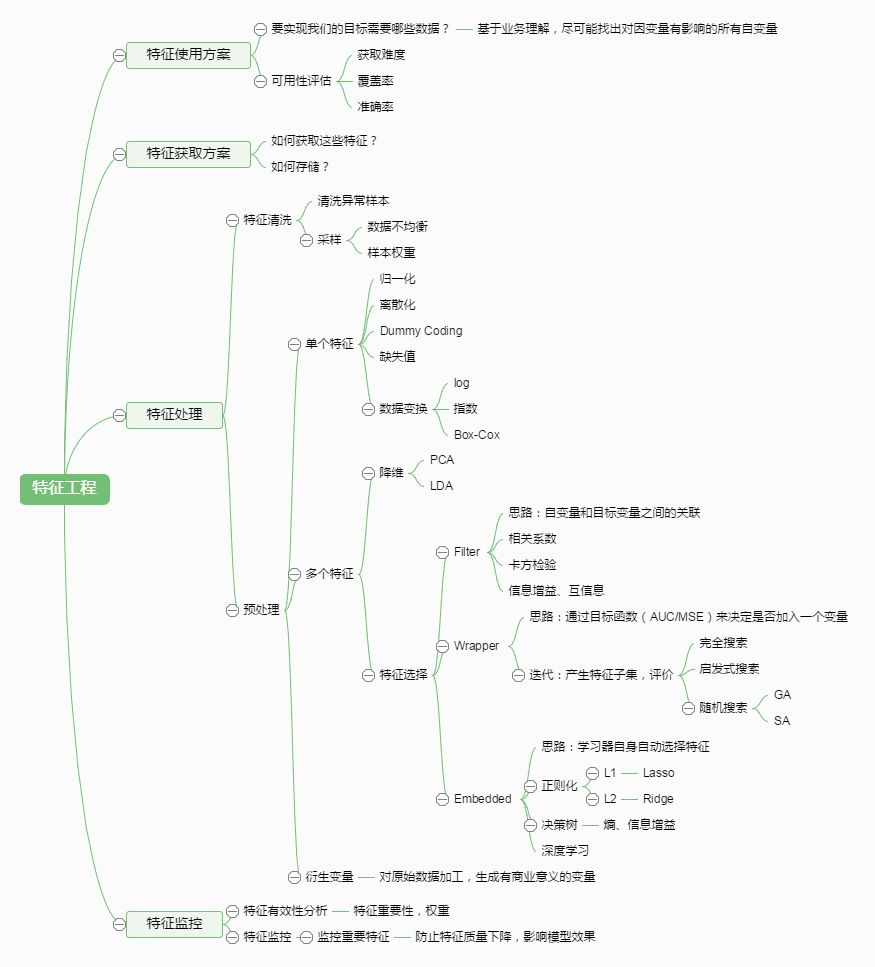
特征工程是什么? 有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程包括以下方面: 特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。首次接触到sklearn,通常会被其丰富且方便的算法模型库吸引,但是这里介绍的特征处理库也十分强大! 本文中使用sklearn中的IRIS(鸢尾花)数据集来对特征处理功能进行说明。IRIS数据集由Fisher在1936年整理,包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Pet...
Python
2026-01-11
Python程序中存储的所有数据都是对象,每一个对象有一个身份,一个类型和一个值。 看变量的实际作用,执行a = 8 这行代码时,就会创建一个值为8的int对象。 变量名是对这个"一个值为8的int对象"的引用。(也可以简称a绑定到8这个对象) 1、可以通过id()来取得对象的身份 这个内置函数,它的参数是a这个变量名,这个函数返回的值 是这个变量a引用的那个"一个值为8的int对象"的内存地址。 [代码] 2、可以通过type()来取得a引用对象的数据类型 [代码] 3、对象的值 当变量出现在表达式中,它会被它引用的对象的值替代。 总结:类型是属于对象,而不是变量。变量只是对对象的一个引用。 对象有可变对象和不可变对象之分。 Python函数传递参数到底是传值还是引用? 传值、引用这个是c...
Machine Learning
2026-01-11
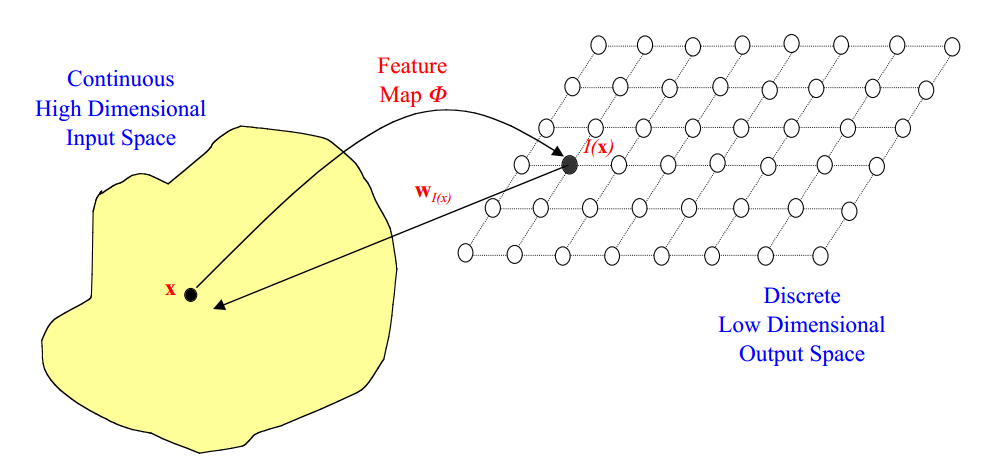
什么是自组织映射? 一个特别有趣的无监督系统是基于竞争性学习,其中输出神经元之间竞争激活,结果是在任意时间只有一个神经元被激活。这个激活的神经元被称为胜者神经元(winnertakesall neuron)。这种竞争可以通过在神经元之间具有横向抑制连接(负反馈路径)来实现。其结果是神经元被迫对自身进行重新组合,这样的网络我们称之为自组织映射(Self Organizing Map,SOM)。 拓扑映射 神经生物学研究表明,不同的感觉输入(运动,视觉,听觉等)以有序的方式映射到大脑皮层的相应区域。 这种映射我们称之为拓扑映射,它具有两个重要特性: 在表示或处理的每个阶段,每一条传入的信息都保存在适当的上下文(相邻节点)中 处理密切相关的信息的神经元之间保持密切,以便它们可以通过短突触连接进行交...
Machine Learning
2026-01-11
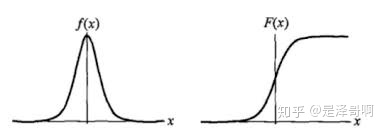
1. 模型介绍 Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。 Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。 1.1 Logistic 分布 Logistic 分布是一种连续型的概率分布,其分布函数和密度函数分别为: [公式] 其中, [Math] 表示位置参数, [Math] 为形状参数。我们可以看下其图像特征: Logistic 分布是由其位置和尺度参数定义的连续分布。Logistic 分布的形状与正态分布的形状相似,但是 Logistic 分布的尾部更长,所以我们可以使用 Logistic 分布来建模比正态分布具...
Machine Learning
2026-01-11
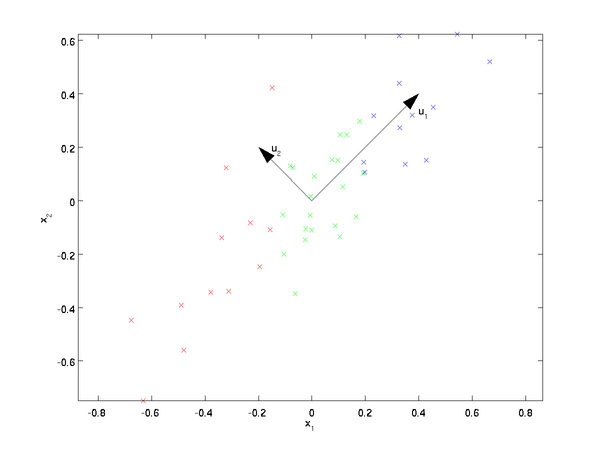
PCA原理总结 PCA的思想 PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。具体的,假如我们的数据集是n维的,共有m个数据 (𝑥(1),𝑥(2),...,𝑥(𝑚)) 。我们希望将这m个数据的维度从n维降到n'维,希望这m个n'维的数据集尽可能的代表原始数据集。我们知道数据从n维降到n'维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这n'维的数据尽可能表示原来的数据呢? 我们先看看最简单的情况,也就是n=2,n'=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向, u_1 和 𝑢_2 ,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出, 𝑢_1 比 𝑢_2 好。 为什么...
Machine Learning
2026-01-11

1. 从GBDT到XGBoost 作为GBDT的高效实现,XGBoost是一个上限特别高的算法,因此在算法竞赛中比较受欢迎。简单来说,对比原算法GBDT,XGBoost主要从下面三个方面做了优化: 一是算法本身的优化:在算法的弱学习器模型选择上,对比GBDT只支持决策树,还可以选择很多其他的弱学习器。在算法的损失函数上,除了本身的损失,还加上了正则化部分。在算法的优化方式上,GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost损失函数对误差部分做二阶泰勒展开,更加准确。算法本身的优化是我们后面讨论的重点。 二是算法运行效率的优化:对每个弱学习器,比如决策树建立的过程做并行选择,找到合适的子树分裂特征和特征值。在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行...
Machine Learning
2026-01-11
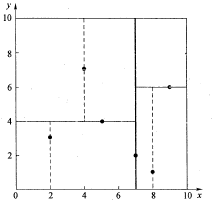
kd树(kdimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。 应用背景 SIFT算法中做特征点匹配的时候就会利用到kd树。而特征点匹配实际上就是一个通过距离函数在高维矢量之间进行相似性检索的问题。针对如何快速而准确地找到查询点的近邻,现在提出了很多高维空间索引结构和近似查询的算法,kd树就是其中一种。 索引结构中相似性查询有两种基本的方式:一种是范围查询(range searches),另一种是K近邻查询(Kneighbor searches)。范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时...
Machine Learning
2026-01-11
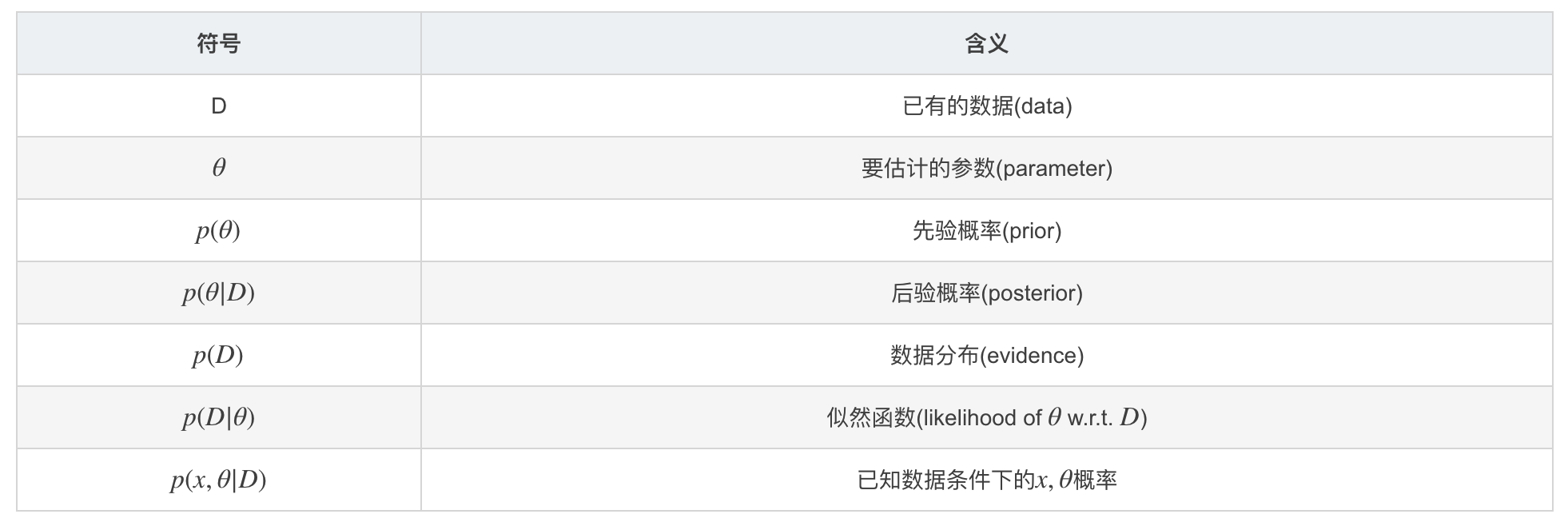
序言 极大似然估计与贝叶斯估计是统计中两种对模型的参数确定的方法,两种参数估计方法使用不同的思想。前者来自于频率派,认为参数是固定的,我们要做的事情就是根据已经掌握的数据来估计这个参数;而后者属于贝叶斯派,认为参数也是服从某种概率分布的,已有的数据只是在这种参数的分布下产生的。所以,直观理解上,极大似然估计就是假设一个参数 θ ,然后根据数据来求出这个 θ . 而贝叶斯估计的难点在于 p(θ) 需要人为设定,之后再考虑结合MAP(maximum a posterior)方法来求一个具体的 θ . 所以极大似然估计与贝叶斯估计最大的不同就在于是否考虑了先验,而两者适用范围也变成了:极大似然估计适用于数据大量,估计的参数能够较好的反映实际情况;而贝叶斯估计则在数据量较少或者比较稀疏的情况下,考虑...
Machine Learning
2026-01-11

这篇博客介绍一下集成学习的几类:Bagging,Boosting以及Stacking。 传统机器学习算法 (例如:决策树,人工神经网络,支持向量机,朴素贝叶斯等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。 Thomas G. Dietterich 指出了集成算法在统计,计算和表示上的有效原因: 统计上的原因 一个学习算法可以理解为在一个假设空间 H 中选找到一个最好的假设。但是,当训练样本的数据量小到不够用来精确的学习到目标假设时,学习算法可以找到很多满足训练样本的分类器。所以,学习算法选择...