Machine Learning
2026-01-11
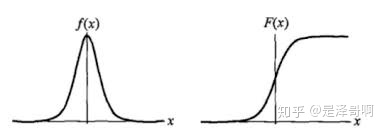
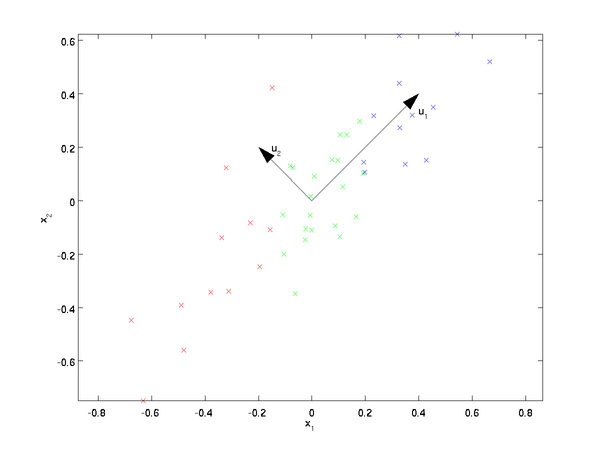
1. 模型介绍 Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。 Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。 1.1 Logistic 分布 Logistic 分布是一种连续型的概率分布,其分布函数和密度函数分别为: [公式] 其中, [Math] 表示位置参数, [Math] 为形状参数。我们可以看下其图像特征: Logistic 分布是由其位置和尺度参数定义的连续分布。Logistic 分布的形状与正态分布的形状相似,但是 Logistic 分布的尾部更长,所以我们可以使用 Logistic 分布来建模比正态分布具...