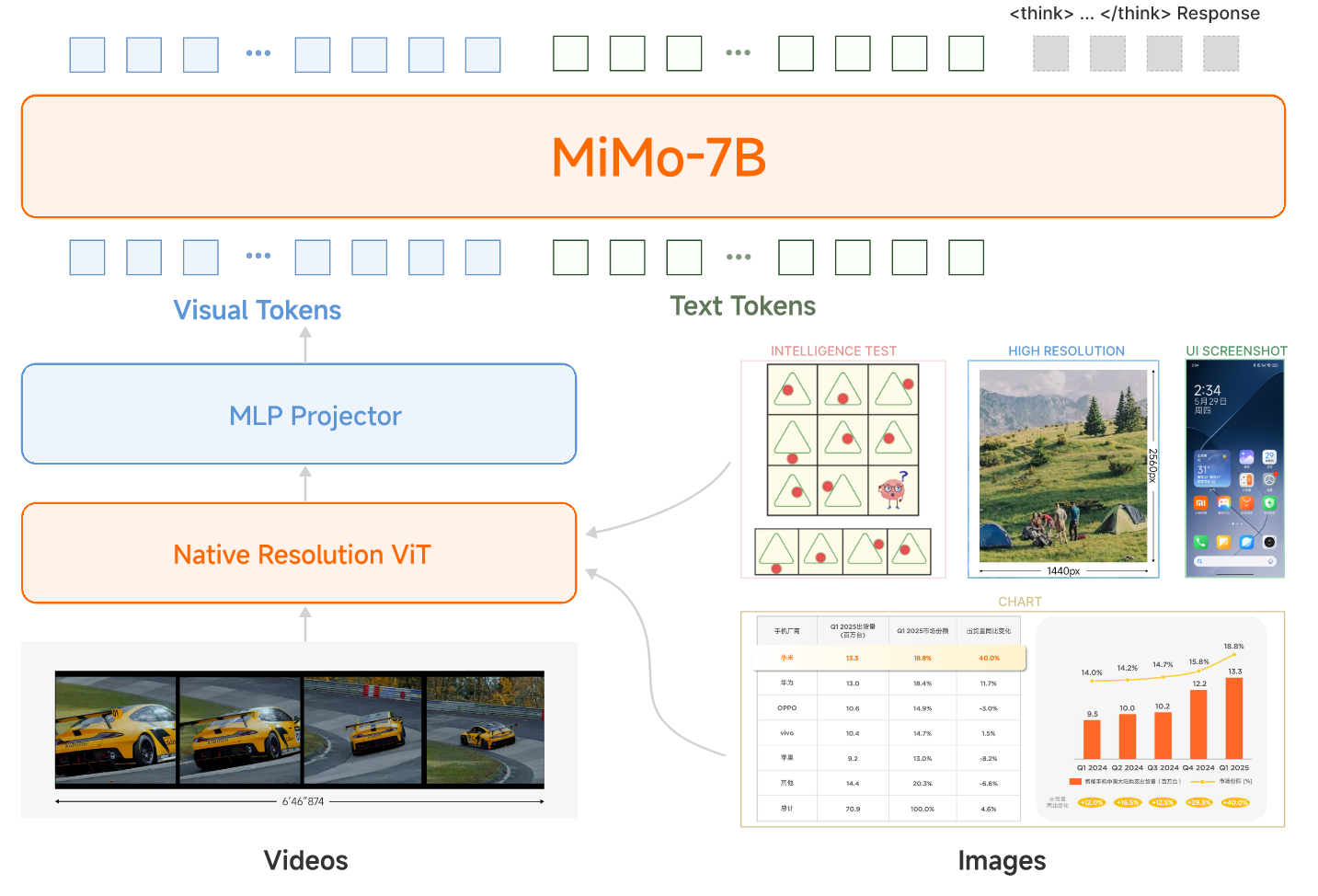
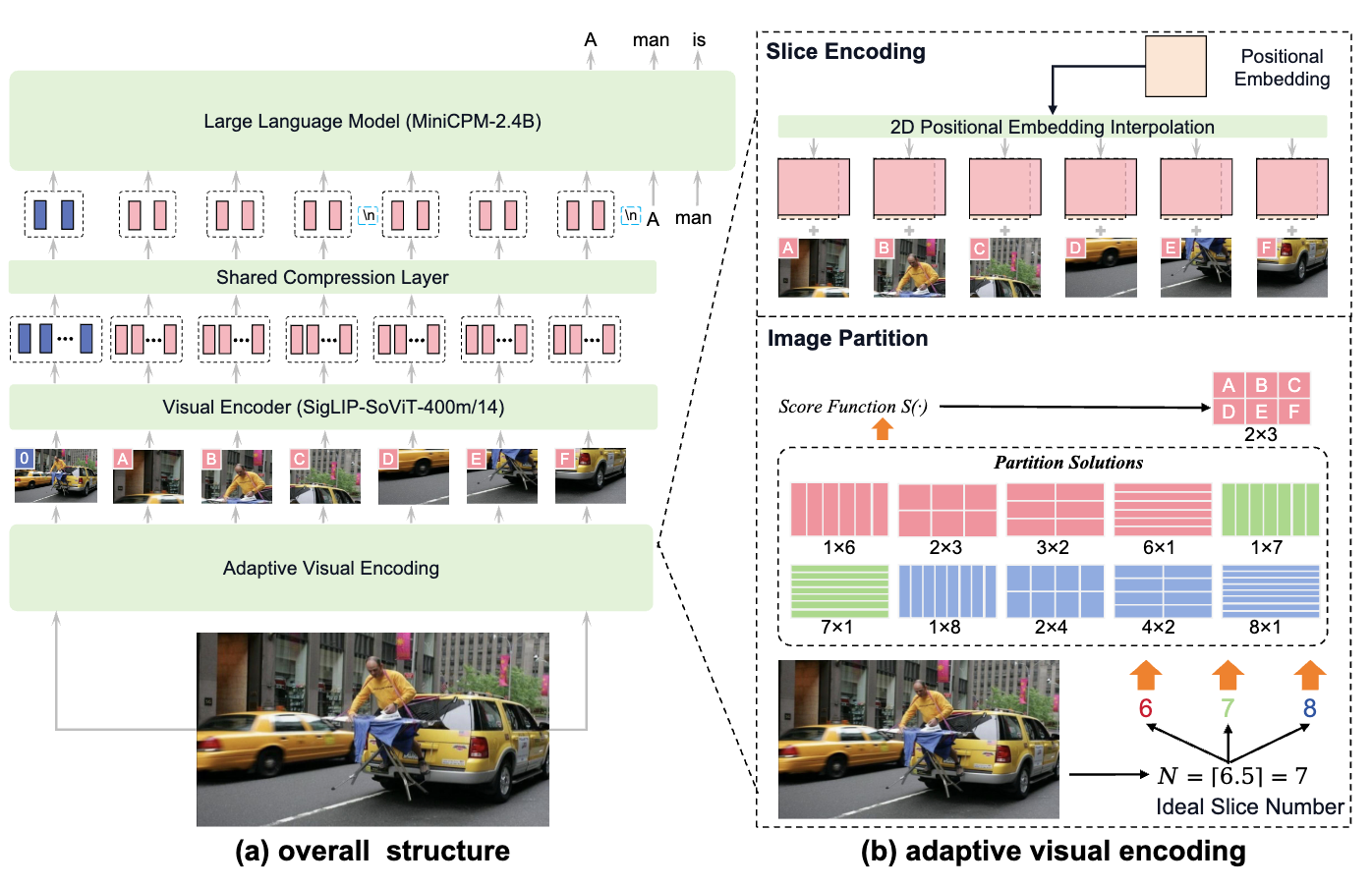
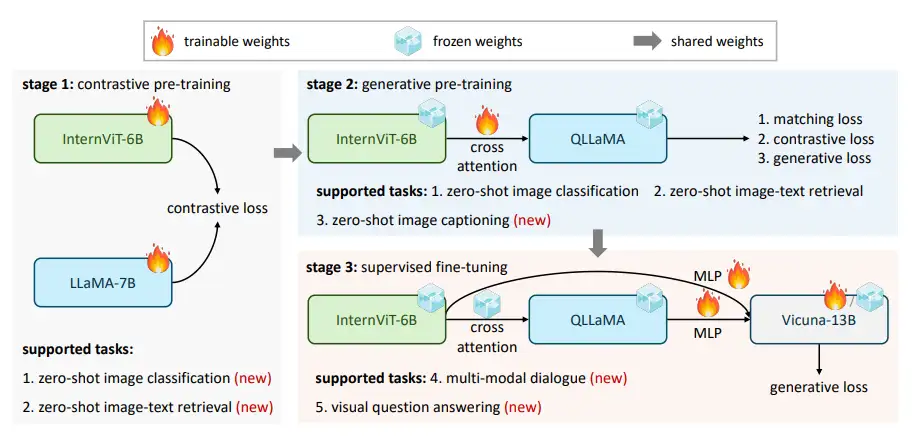
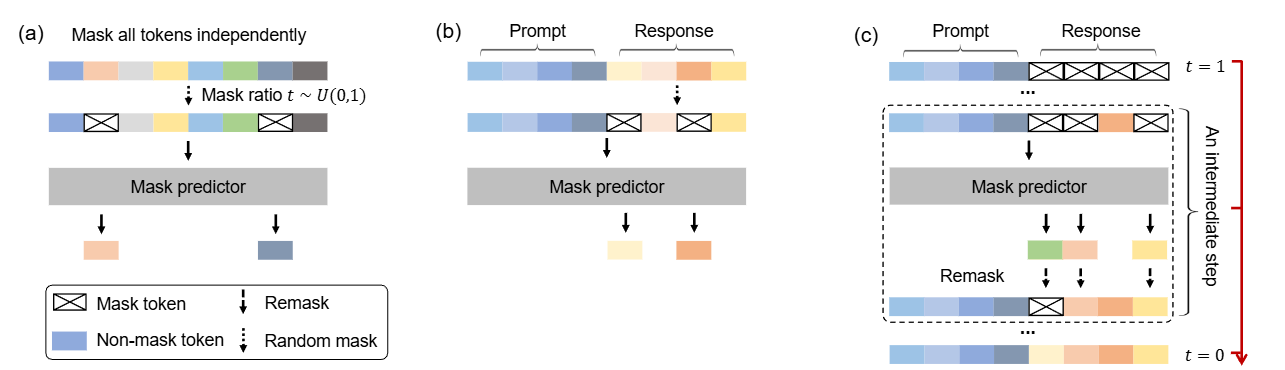
Computer Vision
2026-02-26

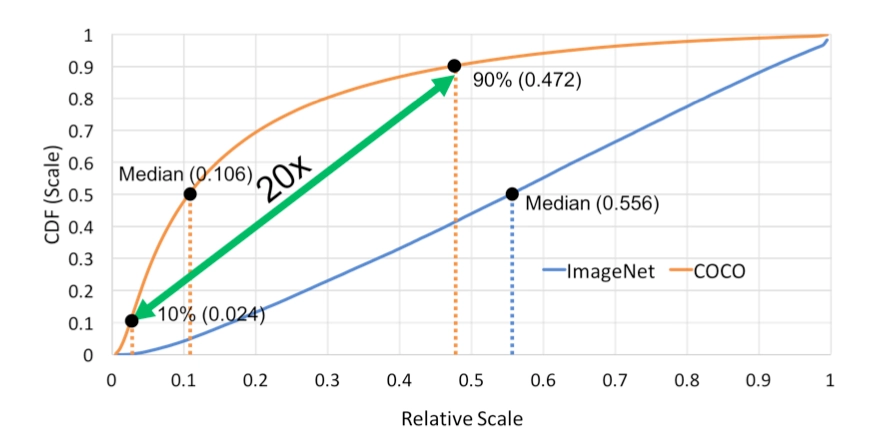
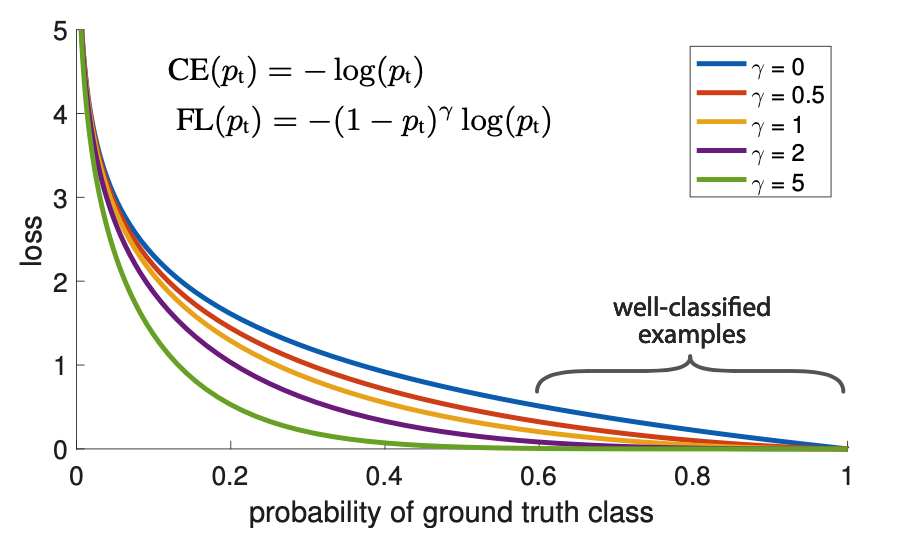
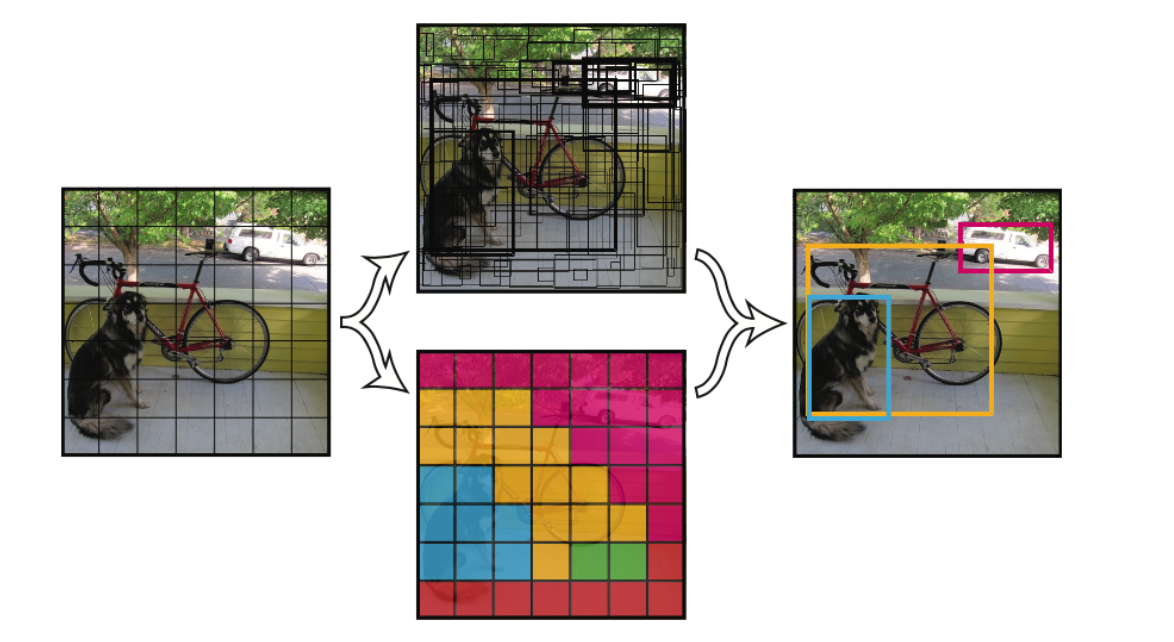
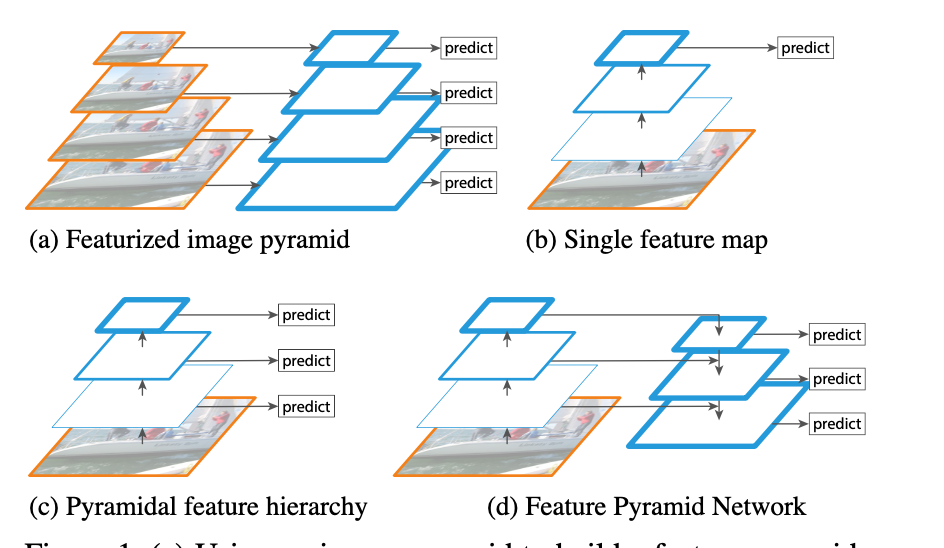
过程: 根据分类概率从小到大排序ABCDEF 从最大概率F开始,F与A~E的IOU是否大于阈值 大于的扔掉,从剩下的当中继续重复2~3 import numpy as np
def nms(bbox, scores, Nt):
if len(bbox) == 0:
return []
bboxes = np.array(bbox)
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
order = np.argsort(scores)
res = []
while order.size > 0:
index = order[-1]
res.append(bboxes[index])
x11 = np.maximum(x1[index], x1[order[:-1]])
...