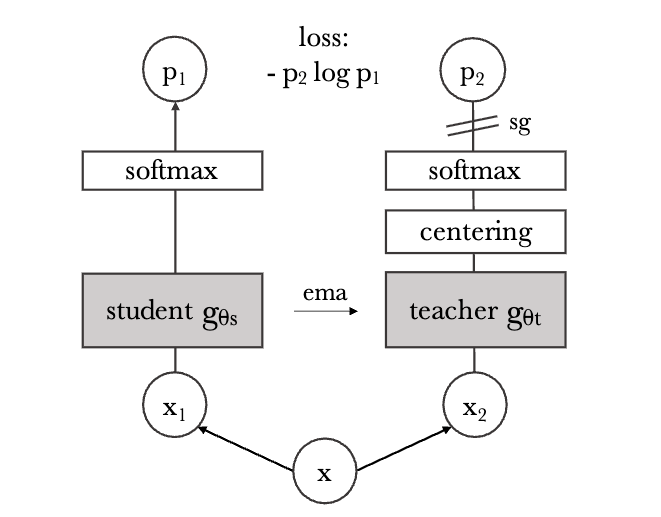
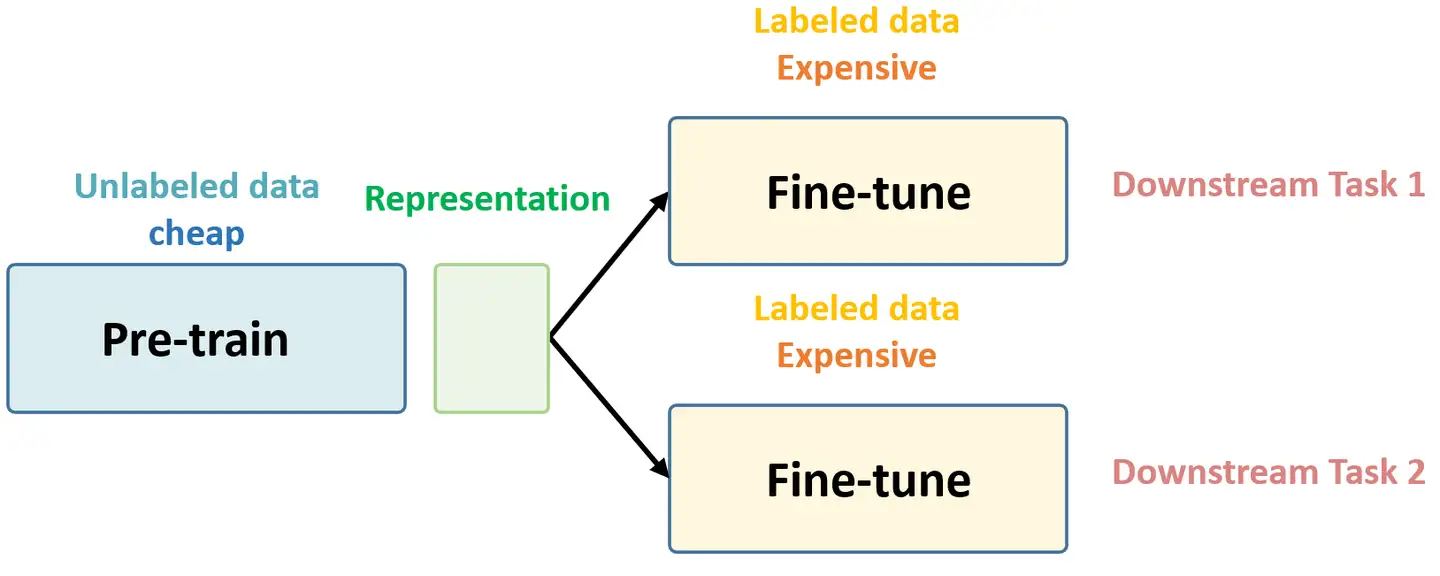
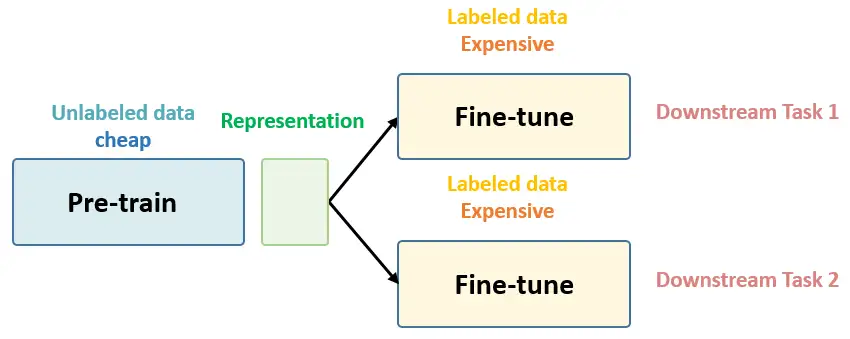
Deep Learning
2026-02-27
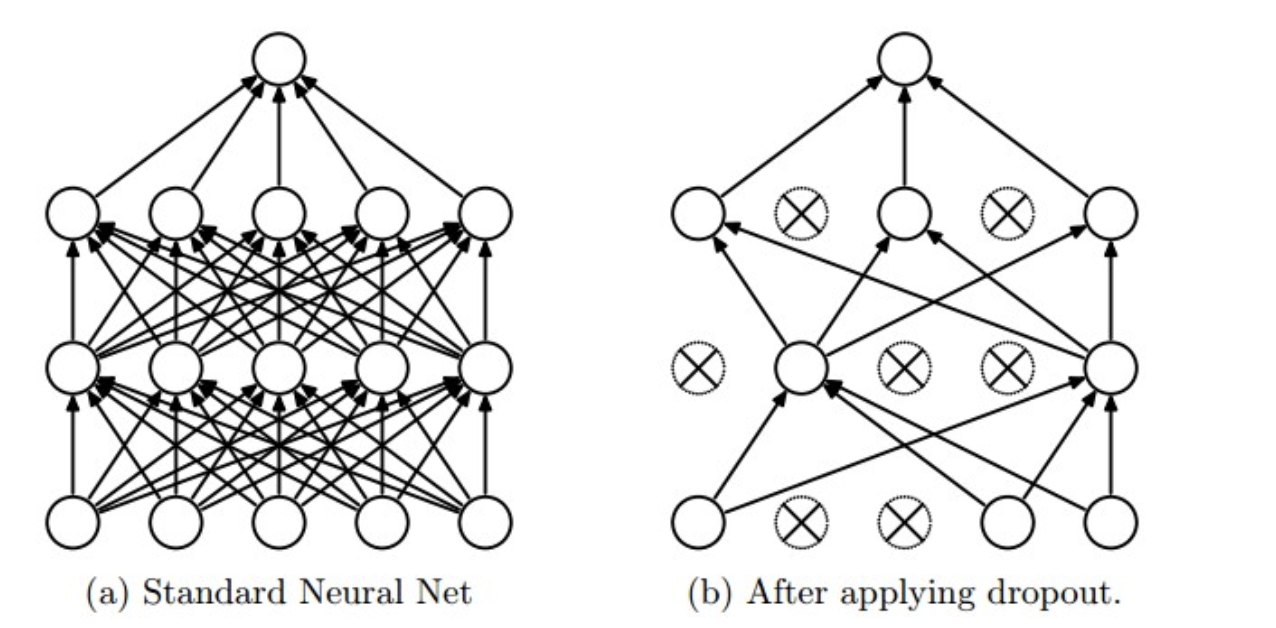
Dropout的运作方式 在神经网络的训练过程中,对于一次迭代中的某一层神经网络,先随机选择中的一些神经元并将其临时隐藏(丢弃),然后再进行本次训练和优化。在下一次迭代中,继续随机隐藏一些神经元,如此直至训练结束。由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。 在训练时,每个神经单元以概率 \(𝑝\) 被保留(Dropout丢弃率为 \(1−𝑝\) );在预测阶段(测试阶段),每个神经单元都是存在的,权重参数 \(𝑤\) 要乘以 \(𝑝\) ,输出是: \(𝑝𝑤\) 。示意图如下: 预测阶段需要乘上 \(p\) 的原因: 前一层隐藏层的一个神经元在dropout之前的输出是 \(x\) ,训练时dropout之后的期望值是 \(E=px+0*(1−p)\) ; 在预测阶段该层神经元总是激活, 为了保持同样的输出期望值并使下一层也得到同样的结果 ,需要调整 \(x\rightarrow px\) . 其中 \(p\) 是Bernoulli分布(0-1分布)中值为1的概率。 Dropout 实现 如前文所述,在训练时随机隐藏部分神经元,在预测时必须要乘上p。代码如下:...