Large Model
2026-03-09

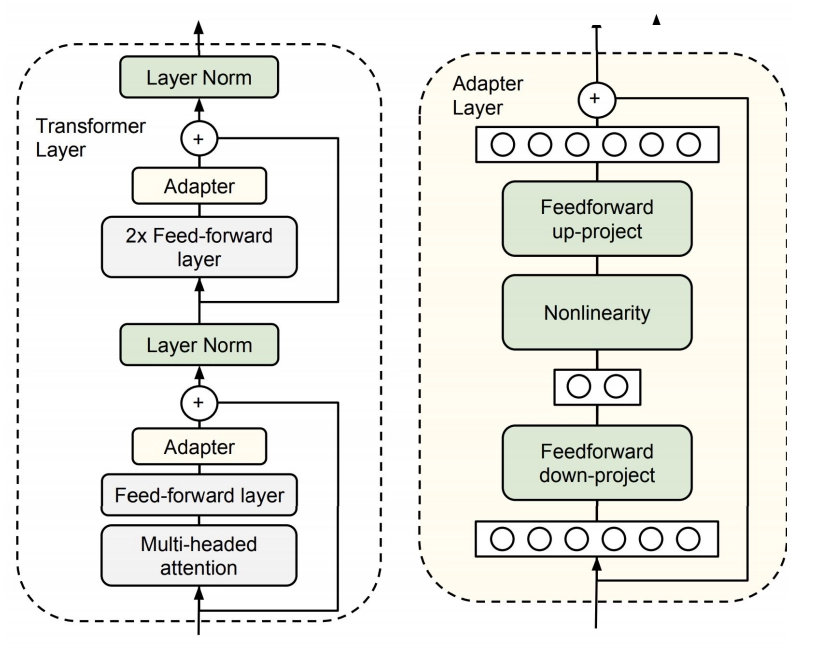
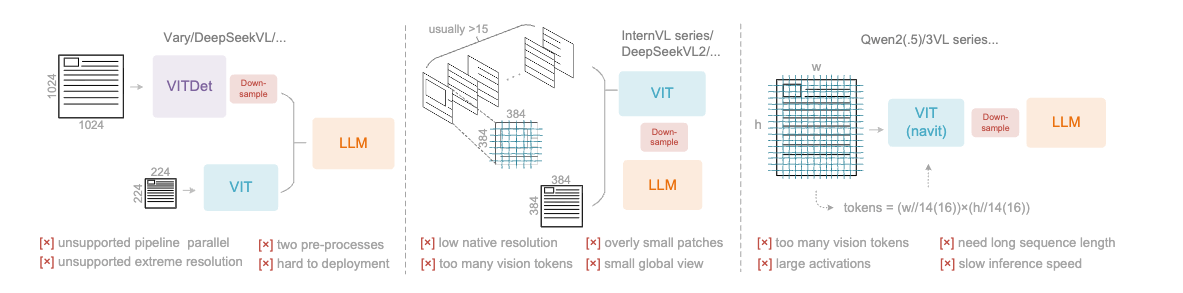
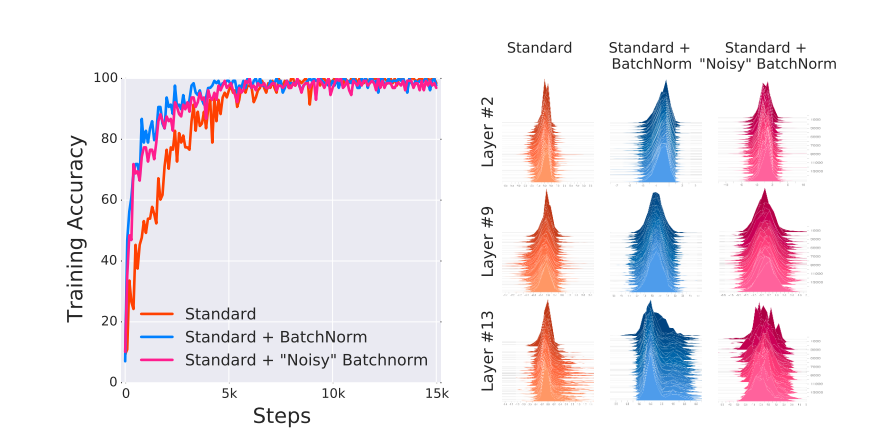
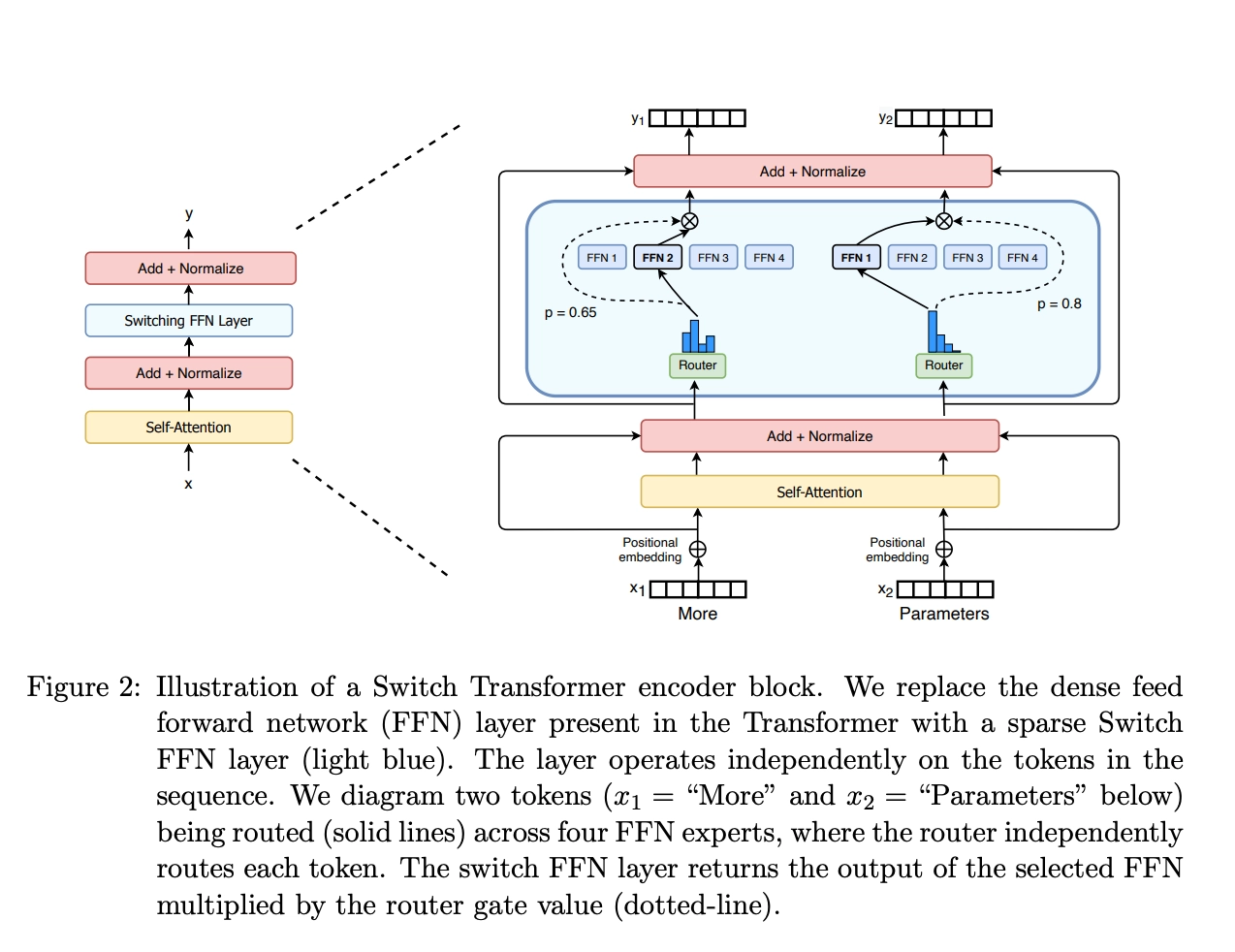
Stanford Alpaca 结合英文语料通过Self Instruct方式微调LLaMA 7B Stanford Alpaca简介 2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B), 具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT-3.5(text-davinci-003) ,这便是指令调优LLaMA的意义所在 论文《Alpaca: A Strong Open-Source Instruction-Following Model》 GitHub地址: https://github.com/tatsu-lab/stanford_alpaca 数据地址 (即斯坦福团队微调LLaMA 7B所用的52K英文指令数据): raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json...