Large Model
2026-01-11

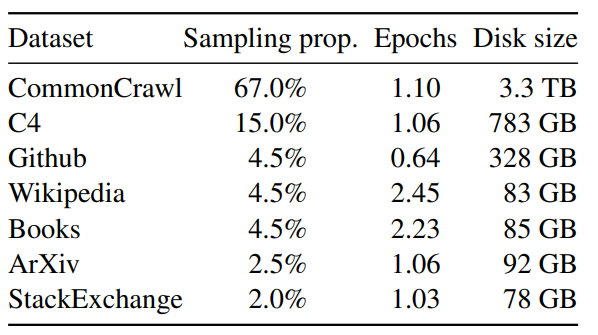
概述 在大型语言模型(LLM)中,幻觉(Hallucination)通常指模型生成不实、虚构、不一致或无意义的内容。本文将幻觉问题聚焦于模型输出未被上下文或世界知识所支撑的情况。 幻觉的分类 幻觉主要分为两类: 1. 内在幻觉(Incontext hallucination):模型输出和上下文(prompt+input)不一致。 1. 外在幻觉(Extrinsic hallucination):不符合事实知识。具体来说,模型输出应基于预训练数据集。由于预训练数据规模庞大,验证成本高昂,因此需要确保模型输出: 后文重点关注外在幻觉问题。 幻觉产生的原因 预训练数据问题 预训练数据量巨大,通常从公开互联网爬取,数据中存在过时、缺失或错误的信息,模型通过最大化对数似然进行记忆,可能错误地学习这些信...