
论文地址: 🔖 https://arxiv.org/pdf/2107.11291 代码地址: 前言 一般来说,我们可以把姿态估计任务分成两个流派:Heatmapbased和Regressionbased。 其主要区别在于监督信息的不同,Heatmapbased方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或softargmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression...
3D Model
2026-01-11
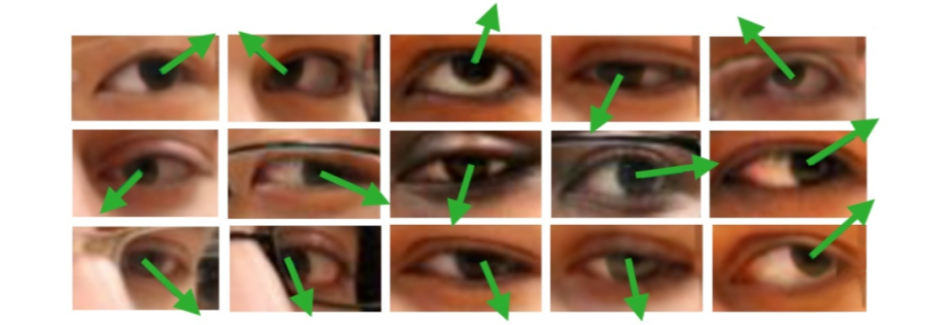
概述 问题定义 广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。 gaze角度的表示一般使用一个3d向量作为表示,也可以转换为pitch 和yaw角度,具体可参考 Model Gaze模型一般使用回归模型,所以这里基本只介绍一些在gaze model中使用的小技巧 Rle Loss 实际问题
Computer Vision
2026-01-11

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zeroshot 和 fewshot能力,结合prompt engineering和fine ...
Computer Vision
2026-01-11
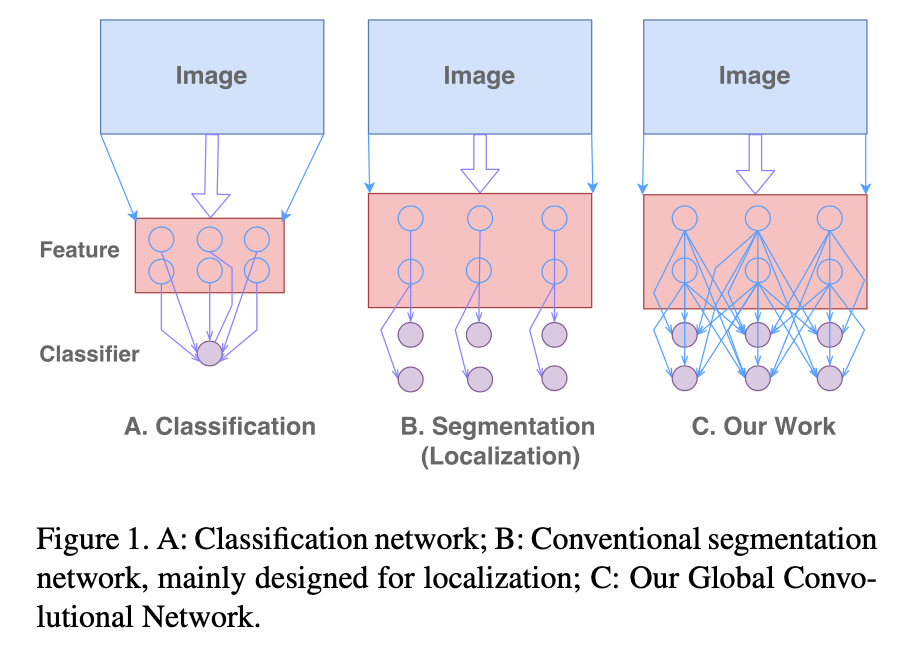
CVPR2017 算法 Global Convolutional Network(GCN),江湖人送外号“Large Kernel”。 Motivation GCN 主要将 Semantic Segmentation分解为:Classification 和 Localization两个问题。但是,这两个任务本质对特征的需求是矛盾的,Classification需要特征对多种Transformation具有不变性,而 Localization需要对 Transformation比较敏感。但是,普通的 Segmentation Model大多针对 Localization Issue设计,正如图(b)所示,而这不利于 Classification。 所以,为了兼顾这两个 Task,本文提出了两个...