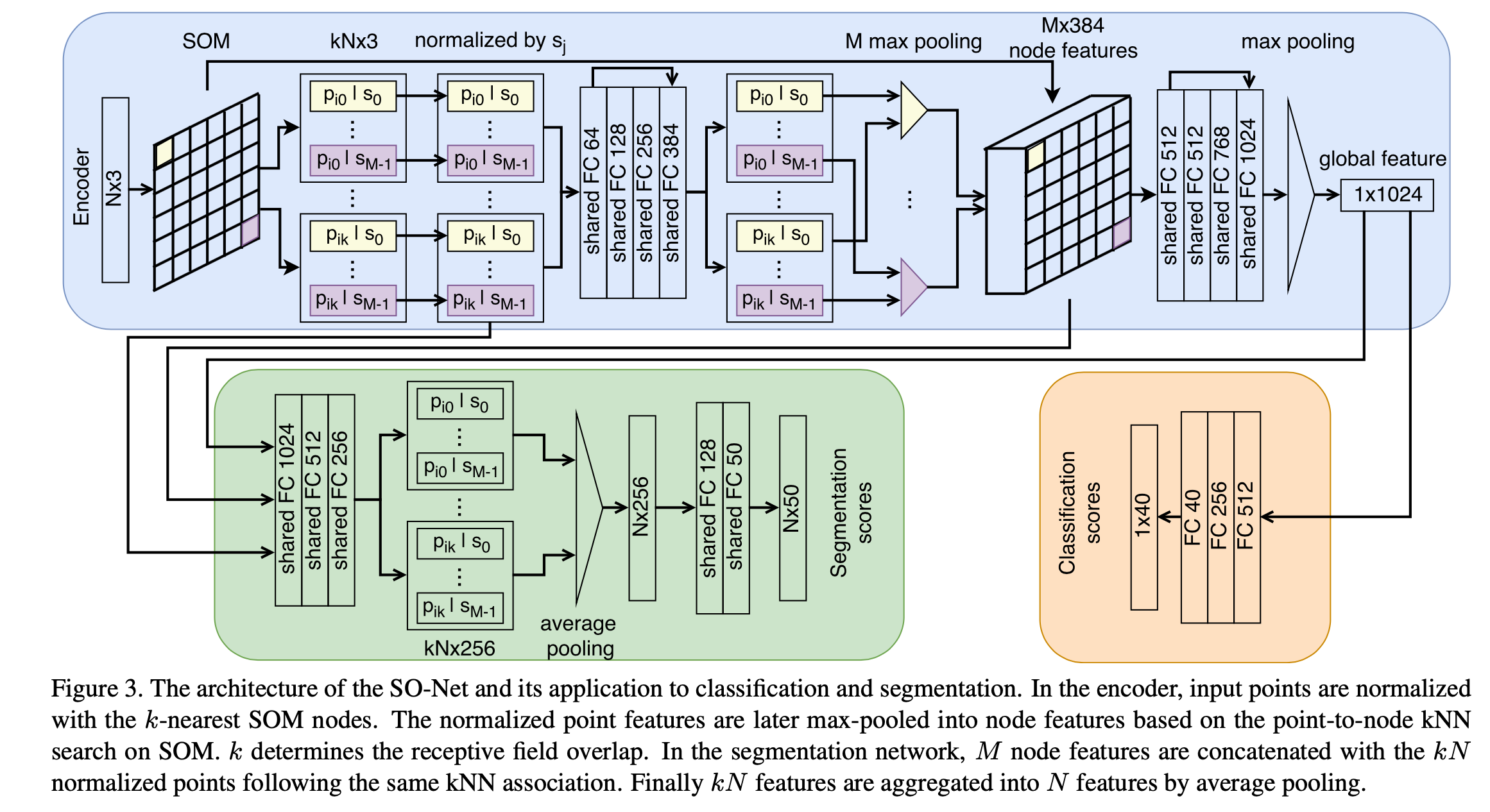
概括 针对一些网络在处理point cloud时的缺点,如:不能对点的空间分布进行建模(例如PointNet++,只是能获取局部信息不能得到局部区域之间的空间关系),提出了SONet。SO的含义是利用Selforganizing map的Net。 结果:它具有能够对点的空间分布进行建模、层次化特征提取、可调节的感受野范围的优点,并能够用于多种任务如重建、分类、分割等等。取得了相似或超过SOTA的性能,因为可并行化和架构简单使得训练速度很快。 贡献: TODO IDEA:作者发现将CNN直接用于SOM图上性能不升反降,为什么(推测:可能是SOM的2D map并不是保持了原本的空间对应关系,可能nodes之间是乱序的,导致用conv2d时精度反而降低)? 难点 如何对local regions之...
3D Model
2026-01-11
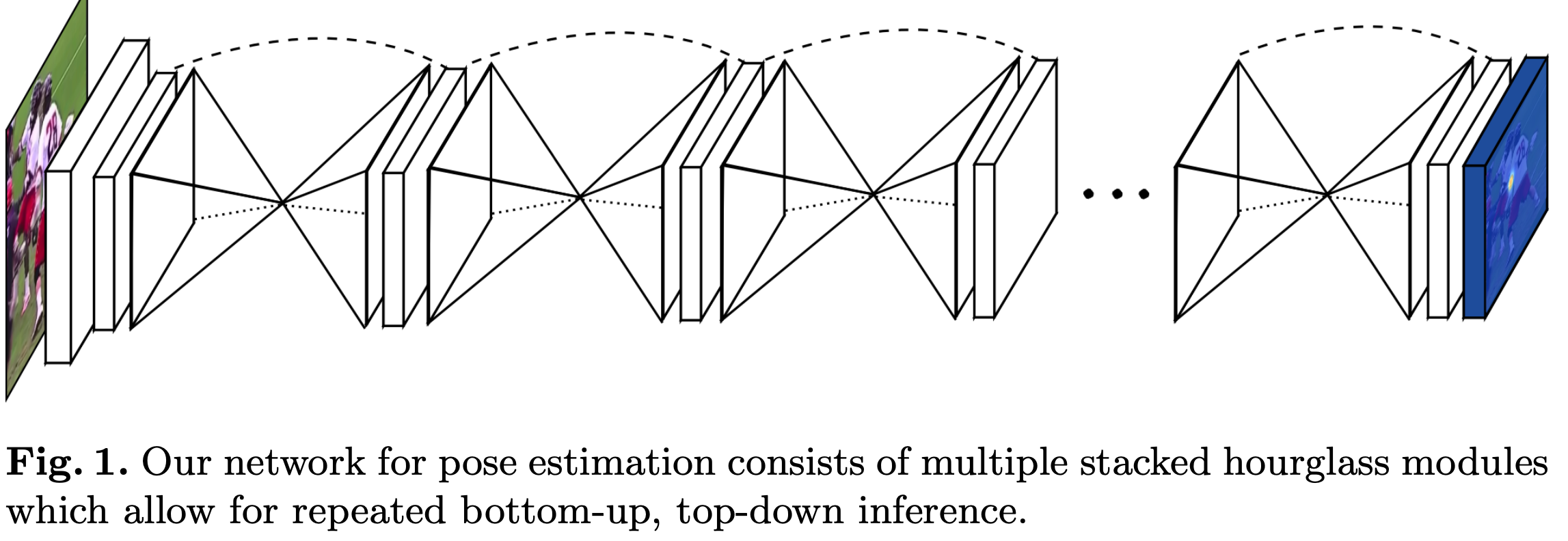
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottomup、topdown过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottomup过程将图片从...
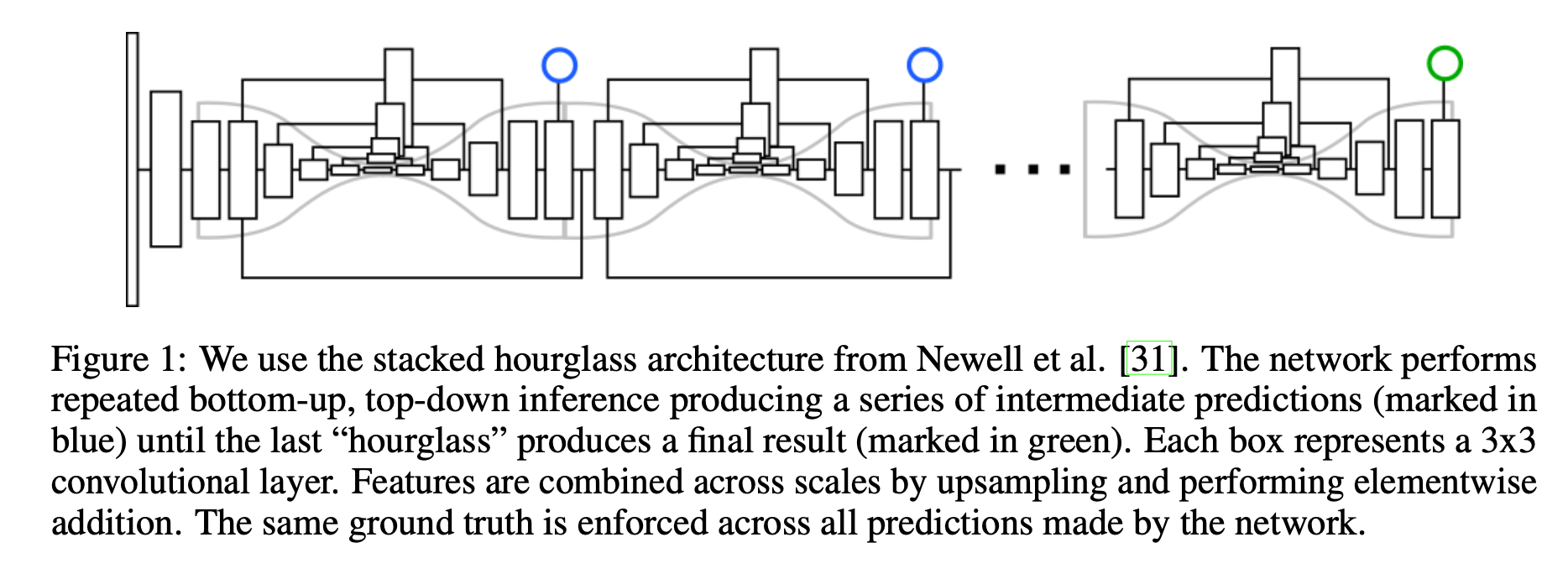
简介 作者认为许多计算机视觉的任务可以看作是检测和分组问题检测一些小的单元,然后将它们组合成更大的单元,例如,多人目标检测可以通过检测人的关节点然后再将它们进行分组(属于同一个人的关节点为一组)解决;实例分割问题可以看作是检测一些相关的像素然后将它们组合成一个目标实例。 Associative Embedding是一种表示关节检测和分组任务的输出的新方法,其基本思想是为每次检测引入一个实数,用作识别对象所属组的“tag”,换句话说,标签将每个检测与同一组中的其他检测相关联。作者使用一个损失函数使得如果相应的检测属于ground truth中的相同组则促使这一对标签具有相似的值。需要注意的是,这里标签具体的值并不重要,重要的是不同标签之间的差异。 这篇其实是源自Stacked Hourglas...
3D Model
2026-01-11

整体流程: [代码] 0. 数据预处理 这个步骤主要是crop四路数据,及生成后续步骤所需要的yaml文件。 1. 四路相机与双路相机标定 内参标定 [代码] 这里主要的函数就是: pts = cv2.findChessboardCorners(img, (board_width, board_height))[1] cv2.cornerSubPix(gray, pts, (12, 12), (1, 1), (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_COUNT, 30, 0.1)) det, intr, dist, _, _ = cv2.calibrateCamera(obj_pts, img_pts, self.imgSize, None, No...

PrefixTuning Paper: 2021.1 Optimizing Continuous Prompts for GenerationGithub:https://github.com/XiangLi1999/PrefixTuningPrompt: Continus Prefix PromptTask & Model:BART(Summarization), GPT2(Table2Text) 最早提出Prompt微调的论文之一,其实是可控文本生成领域的延伸,因此只针对摘要和Table2Text这两个生成任务进行了评估。 PrefixTuning可以理解是CTRL模型的连续化升级版,为了生成不同领域和话题的文本,CTRL是在预训练阶段在输入文本前加入了control code,例如好评...
Large Model
2026-01-11

背景 随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。 例如: 全参微调Qwen1.57BChat预估要2张80GB的A800,160GB显存 全参微调Qwen1.572BChat预估要20张80GB的A800,至少1600GB显存。 而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难 当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数 为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient finetuning, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。 Adapter tuning Adapter ...
Large Model
2026-01-11
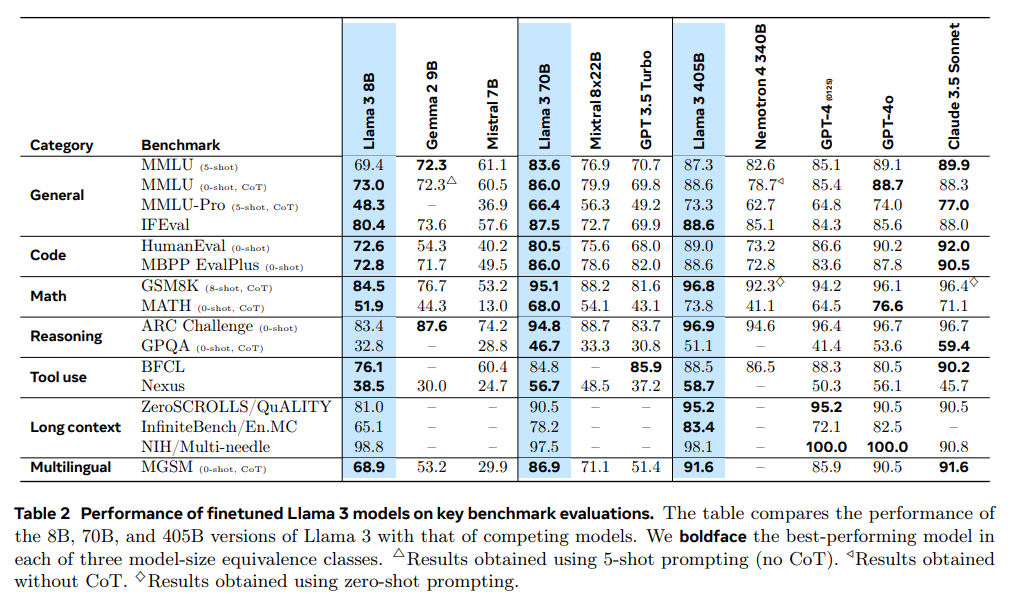
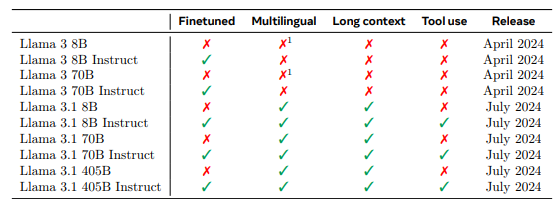
🔖 https://ai.meta.com/research/publications/thellama3herdofmodels/ 简介 本文归纳llm的训练分为两个主要阶段: 预训练阶段 pretraining,模型通过使用简单的任务如预测下一个词或caption进行大规模训练 后训练阶段 posttraining,模型经过调整以遵循指令、与人类偏好保持一致,并提高特定能力, 例如编码和推理。 Llama 3.1 发布,在 15.6T 多语言 tokens 上训练,支持多语言,编程,推理和工具使用。新模型支持 128K tokens 长度的上下文。最大的旗舰模型参数量为 405B,效果达到了闭源模型的 SOTA。 模型结构 Llama 3.1 的模型和 Llama 3 是一样的,只是做了...
Large Model
2026-01-11
LLaMA 一直致力于LLM模型研究的国外TOP 3大厂除了OpenAI、Google,便是Meta(原来的Facebook) Meta曾第一个发布了基于LLM的聊天机器人——BlenderBot 3,但输出不够安全,很快下线;再后来,Meta发布一个专门为科学研究设计的模型Galactica,但用户期望过高,发布三天后又下线 23年2.24日,Meta通过论文《LLaMA: Open and Efficient Foundation Language Models》发布了自家的大型语言模型LLaMA,有多个参数规模的版本(7B 13B 33B 65B),并于次月3.8日被迫开源 LLaMA只使用公开的数据(总计1.4T即1,400GB的token,其中CommonCrawl的数据占比67%...
Large Model
2026-01-11

概述 在大型语言模型(LLM)中,幻觉(Hallucination)通常指模型生成不实、虚构、不一致或无意义的内容。本文将幻觉问题聚焦于模型输出未被上下文或世界知识所支撑的情况。 幻觉的分类 幻觉主要分为两类: 1. 内在幻觉(Incontext hallucination):模型输出和上下文(prompt+input)不一致。 1. 外在幻觉(Extrinsic hallucination):不符合事实知识。具体来说,模型输出应基于预训练数据集。由于预训练数据规模庞大,验证成本高昂,因此需要确保模型输出: 后文重点关注外在幻觉问题。 幻觉产生的原因 预训练数据问题 预训练数据量巨大,通常从公开互联网爬取,数据中存在过时、缺失或错误的信息,模型通过最大化对数似然进行记忆,可能错误地学习这些信...
Large Model
2026-01-11
DeepSeekV2的发布引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA(Multihead Latent Attention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。 接下来,本文将跟大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。 MHA MHA(MultiHead Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种Attention...
背景 RLHF 通常包括三个阶段: 有监督微调(SFT) 奖励建模阶段 (Reward Model) RL微调阶段 直接偏好优化(DPO) 传统的RLHF方法分两步走: 1. 先训练一个奖励模型来判断哪个回答更好 1. 然后用强化学习让语言模型去最大化这个奖励 这个过程很复杂,就像绕了一大圈:先学习"什么是好的",再学习"如何做好"。 DPO发现了一个数学上的捷径: 1. 关键发现:对于任何奖励函数,都存在一个对应的最优策略(语言模型);反过来说,任何语言模型也隐含着一个它认为最优的奖励函数 1. 直接优化:与其先训练奖励模型再训练语言模型,不如直接训练语言模型,让它自己内化"什么是好的" 1. 数学转换:DPO将"学习判断好坏"和"学习生成好内容"这两个任务合二为一,通过一个简单的数学变换...
Large Model
2026-01-11

Stanford Alpaca 结合英文语料通过Self Instruct方式微调LLaMA 7B Stanford Alpaca简介 2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B),具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT3.5(textdavinci003),这便是指令调优LLaMA的意义所在 论文《Alpaca: A Strong OpenSource InstructionFollowing Model》 GitHub地址:https://github.c...