Search&Rec
2026-01-11
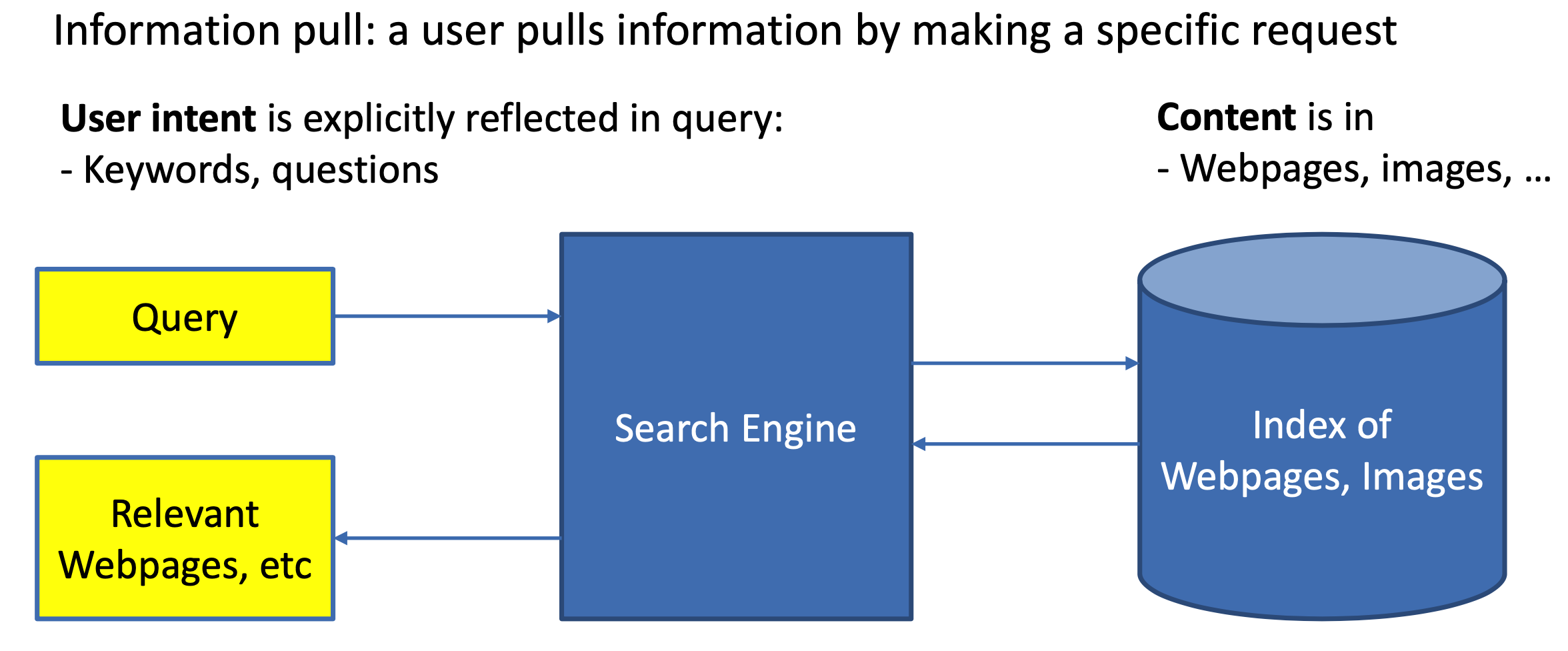
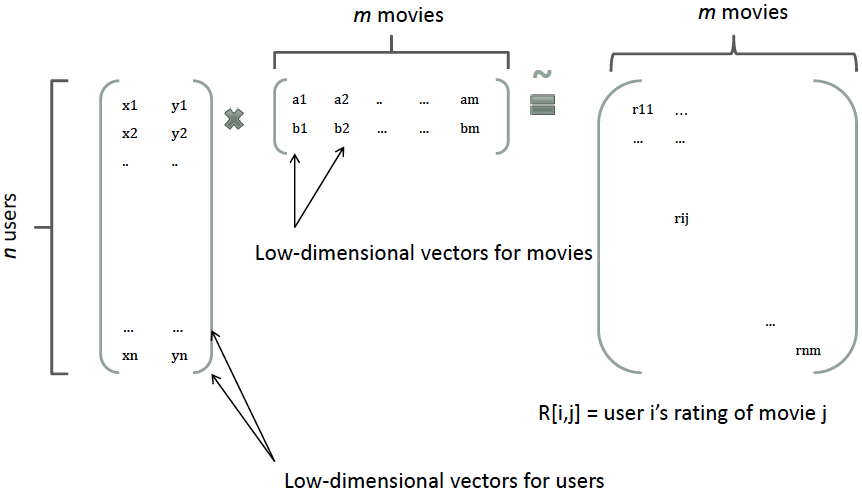
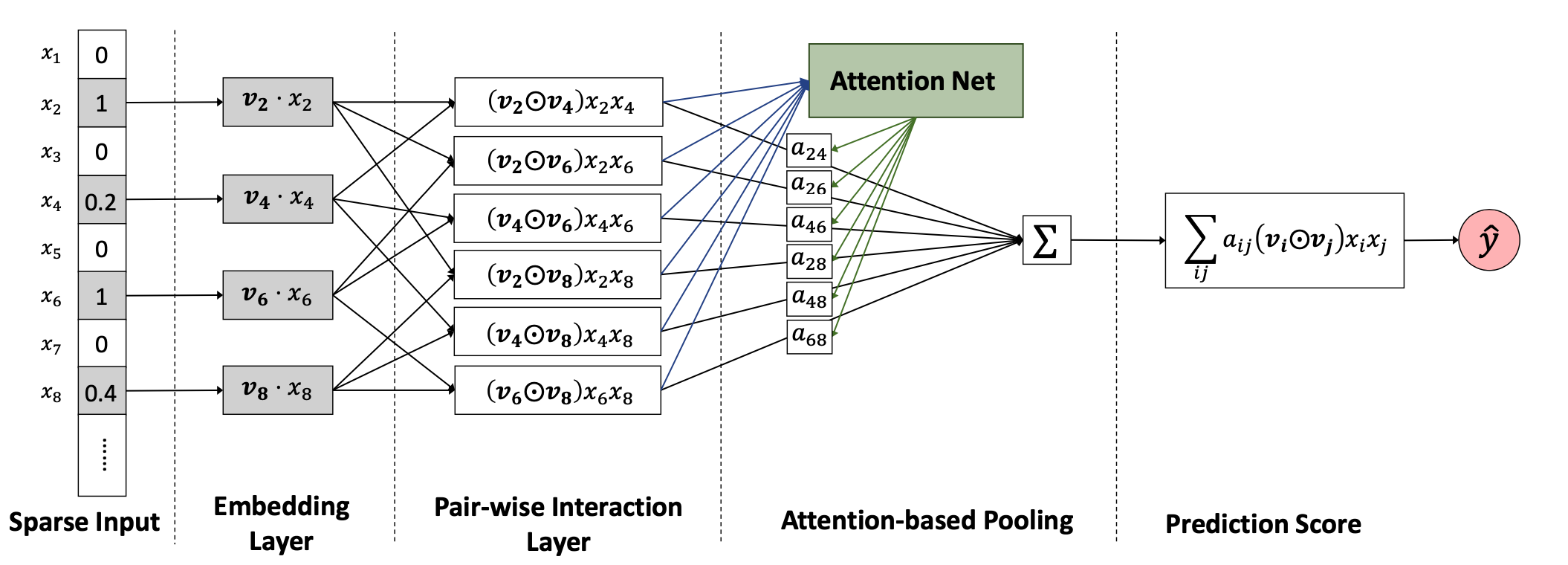
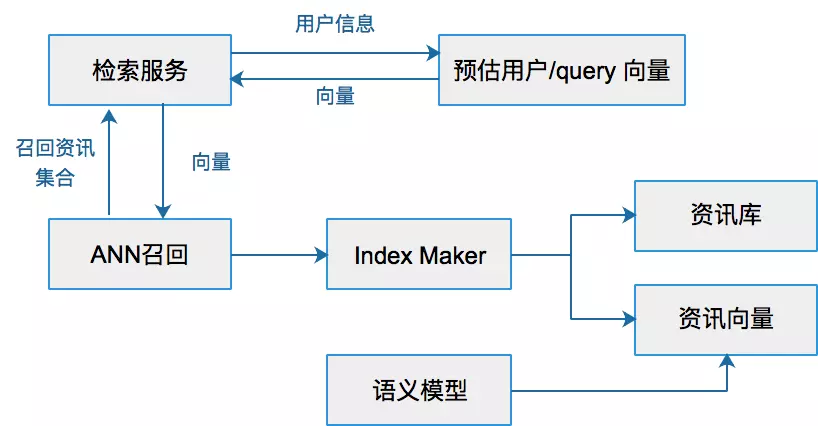
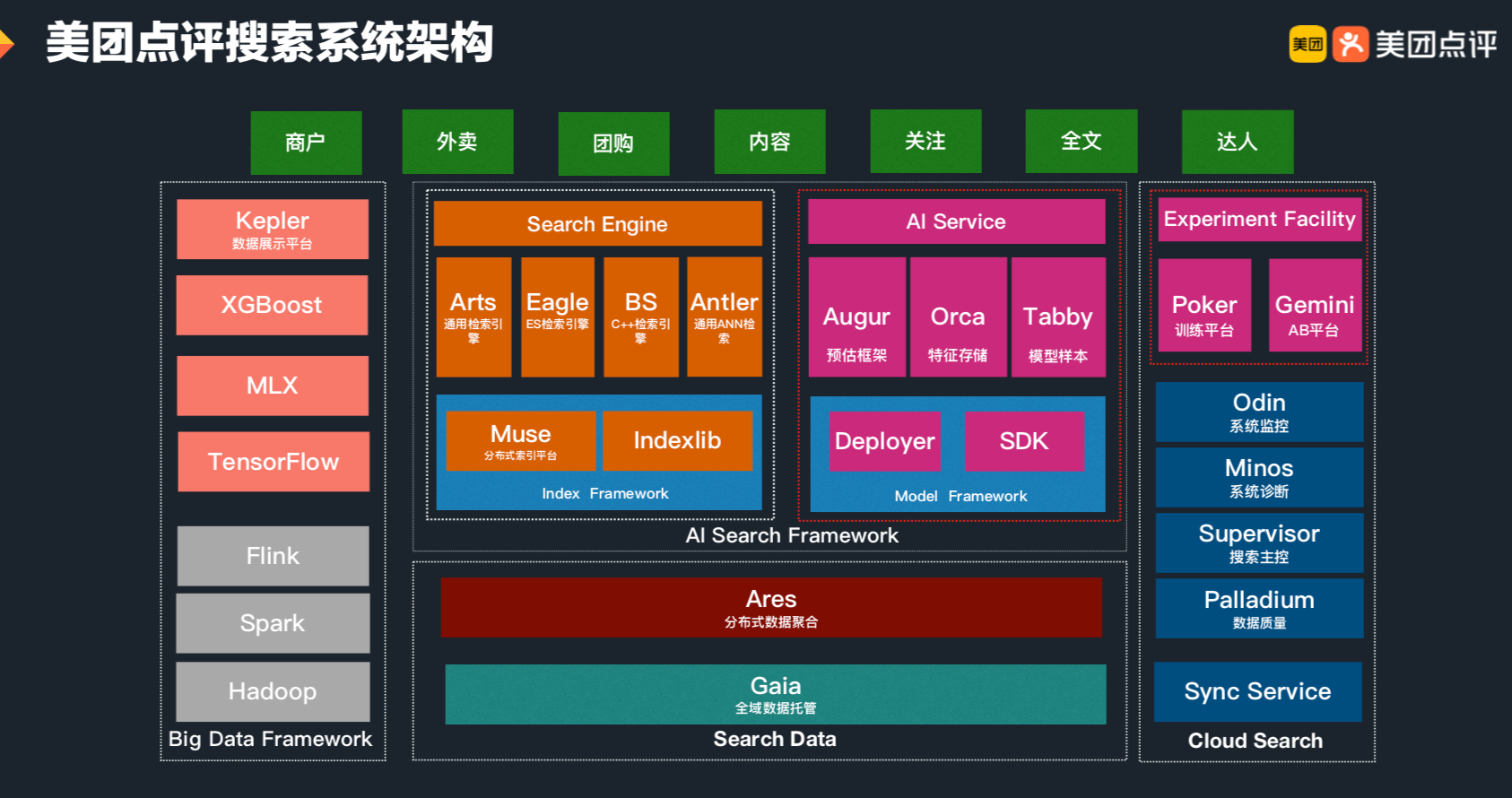
1. 搜索引擎概述 1.1 推荐和搜索比较 推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。 对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过querydoc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。 对于推荐来说,推荐系统就是系统根据用户的属性(如性别、年龄、学历等),用户在系统里过去的行为(例如浏览、点击、搜索、收藏等),以及当前上下文环境(如网络、手机设备等),从而给用户推...