Large Model
2026-01-26
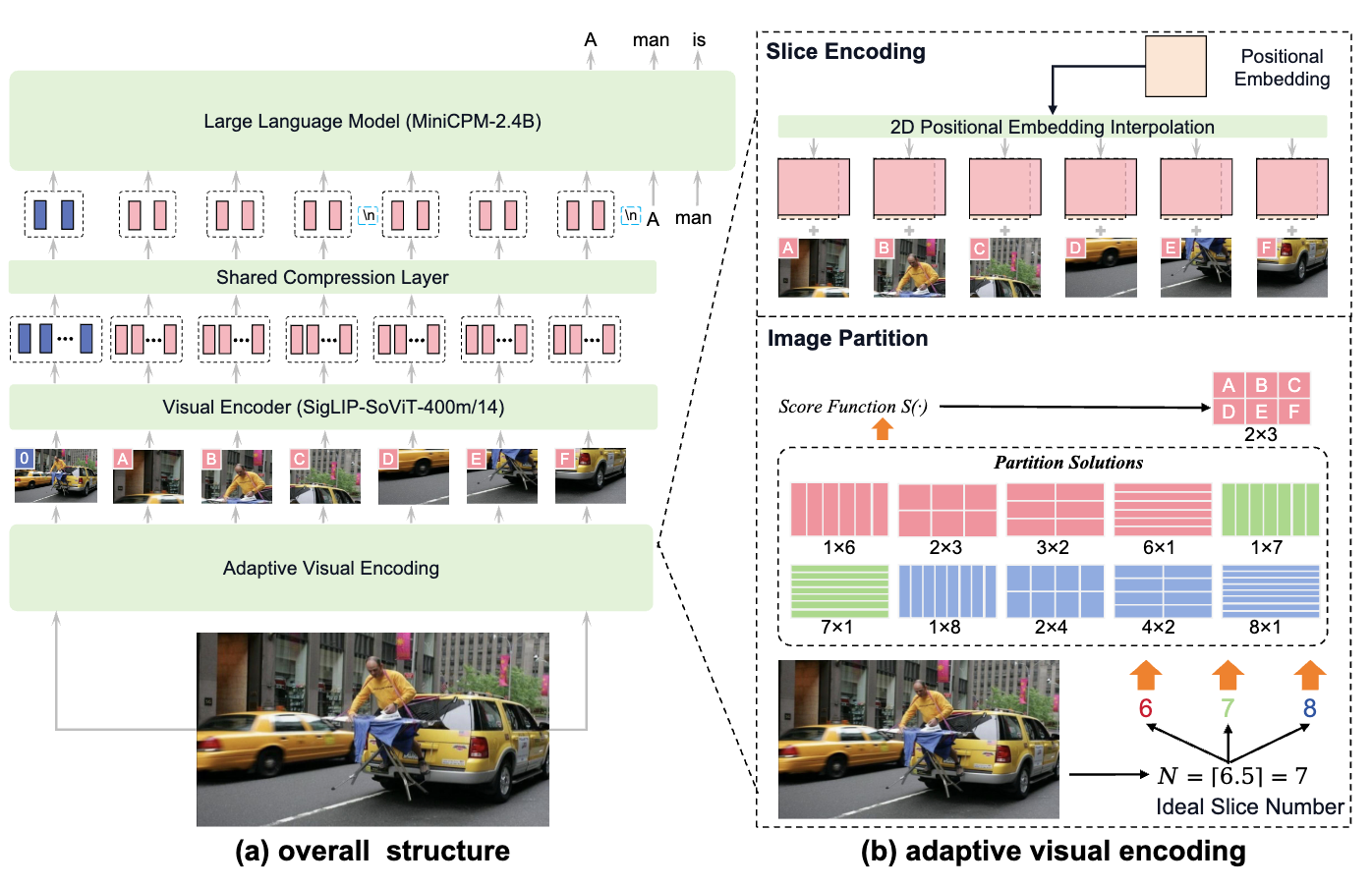
MiniCPM-V系列是面壁智能推出的小参数量的开源多模态大模型,没有超过9B的版本。主打小而强。 MiniCPM-Llama3-V 2.5 这版有论文了,详细写。应该也是2.6的基础。 这一版在 OpenCompass 评估中优于强大的 GPT-4V-1106、Gemini Pro 和 Claude 3。 能力 支持最高1.8M像素的高分辨率图像输入(例如1344*1344),支持任意长宽比图像 强大的OCR,OCRBench 上优于 GPT-4V、Gemini Pro 和 Qwen-VL-Max,支持table-to-markdown 可信,基于RLAIF-V技术做了对齐,减少幻觉,更符合人类喜好 多语言,基于VisCPM技术,支持30多种语言 系统地集成了一套端侧部署优化技术 模型架构 基本架构 三部分:visual encoder, 压缩层, LLM visual encoder:SigLIP SoViT-400m/14 压缩层:单层交叉注意力 LLM:每一代都不同 Adaptive Visual Encoding...