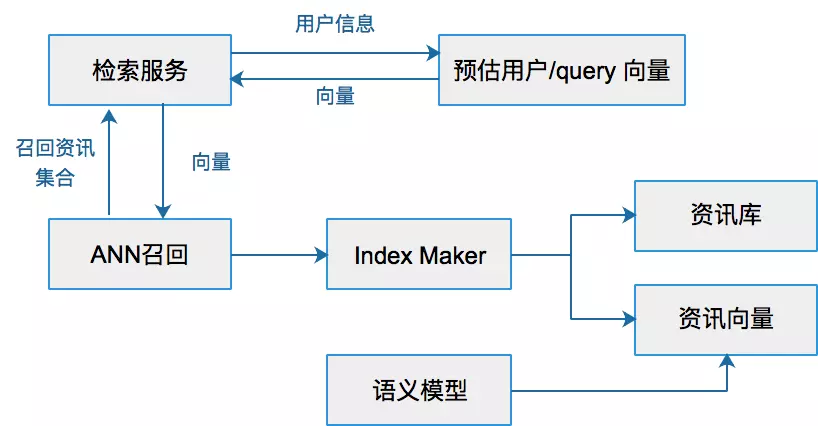
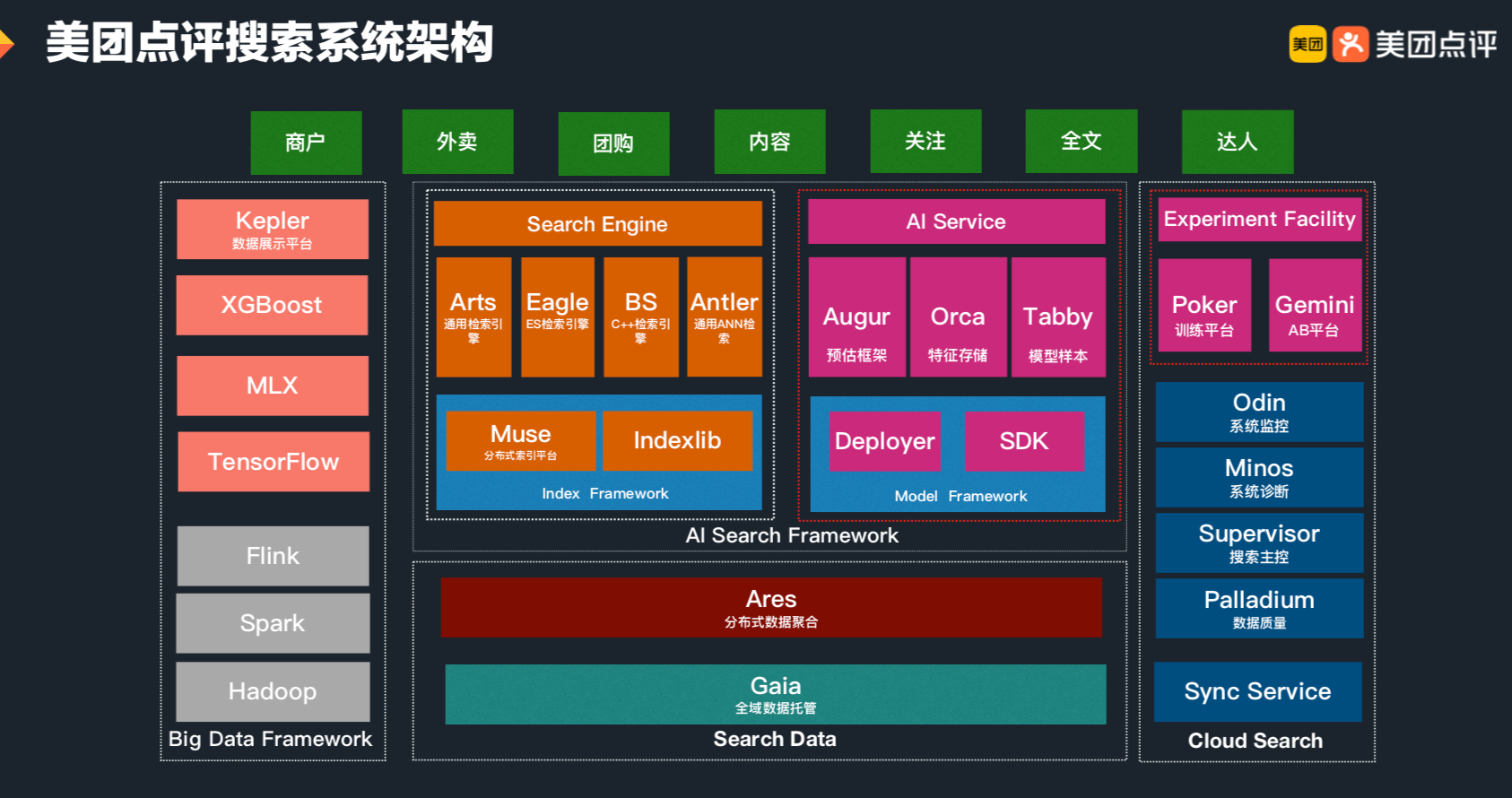
Machine Learning
2026-01-11
随机森林 (Random Forests) 是一种利用CART决策树作为基学习器的 Bagging 集成学习算法。随机森林模型的构建过程如下: 数据采样 作为一种 Bagging 集成算法,随机森林同样采用有放回的采样,对于总体训练集 T ,抽样一个子集 T_{sub} 作为训练样本集。除此之外,假设训练集的特征个数为 d ,每次仅选择 k(k<d) 个构建决策树。因此,随机森林除了能够做到样本扰动外,还添加了特征扰动,对于特征的选择个数,推荐值为 k=log_2d 。 树的构建 每次根据采样得到的数据和特征构建一棵决策树。在构建决策树的过程中,会让决策树生长完全而不进行剪枝。构建出的若干棵决策树则组成了最终的随机森林。 随机森林在众多分类算法中表现十分出众,其主要的优点包括: 1. 由于...