
PrefixTuning Paper: 2021.1 Optimizing Continuous Prompts for GenerationGithub:https://github.com/XiangLi1999/PrefixTuningPrompt: Continus Prefix PromptTask & Model:BART(Summarization), GPT2(Table2Text) 最早提出Prompt微调的论文之一,其实是可控文本生成领域的延伸,因此只针对摘要和Table2Text这两个生成任务进行了评估。 PrefixTuning可以理解是CTRL模型的连续化升级版,为了生成不同领域和话题的文本,CTRL是在预训练阶段在输入文本前加入了control code,例如好评...
Large Model
2026-01-11

背景 随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。 例如: 全参微调Qwen1.57BChat预估要2张80GB的A800,160GB显存 全参微调Qwen1.572BChat预估要20张80GB的A800,至少1600GB显存。 而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难 当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数 为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient finetuning, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。 Adapter tuning Adapter ...
Machine Learning
2026-01-11

1. 从GBDT到XGBoost 作为GBDT的高效实现,XGBoost是一个上限特别高的算法,因此在算法竞赛中比较受欢迎。简单来说,对比原算法GBDT,XGBoost主要从下面三个方面做了优化: 一是算法本身的优化:在算法的弱学习器模型选择上,对比GBDT只支持决策树,还可以选择很多其他的弱学习器。在算法的损失函数上,除了本身的损失,还加上了正则化部分。在算法的优化方式上,GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost损失函数对误差部分做二阶泰勒展开,更加准确。算法本身的优化是我们后面讨论的重点。 二是算法运行效率的优化:对每个弱学习器,比如决策树建立的过程做并行选择,找到合适的子树分裂特征和特征值。在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行...
Machine Learning
2026-01-11

这篇博客介绍一下集成学习的几类:Bagging,Boosting以及Stacking。 传统机器学习算法 (例如:决策树,人工神经网络,支持向量机,朴素贝叶斯等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。 Thomas G. Dietterich 指出了集成算法在统计,计算和表示上的有效原因: 统计上的原因 一个学习算法可以理解为在一个假设空间 H 中选找到一个最好的假设。但是,当训练样本的数据量小到不够用来精确的学习到目标假设时,学习算法可以找到很多满足训练样本的分类器。所以,学习算法选择...
Large Model
2026-01-11

背景 随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。 例如: 全参微调Qwen1.57BChat预估要2张80GB的A800,160GB显存 全参微调Qwen1.572BChat预估要20张80GB的A800,至少1600GB显存。 而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难 当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数 为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient finetuning, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。 LoRA LoRA(LowRank Adapt...
Computer Vision
2026-01-11
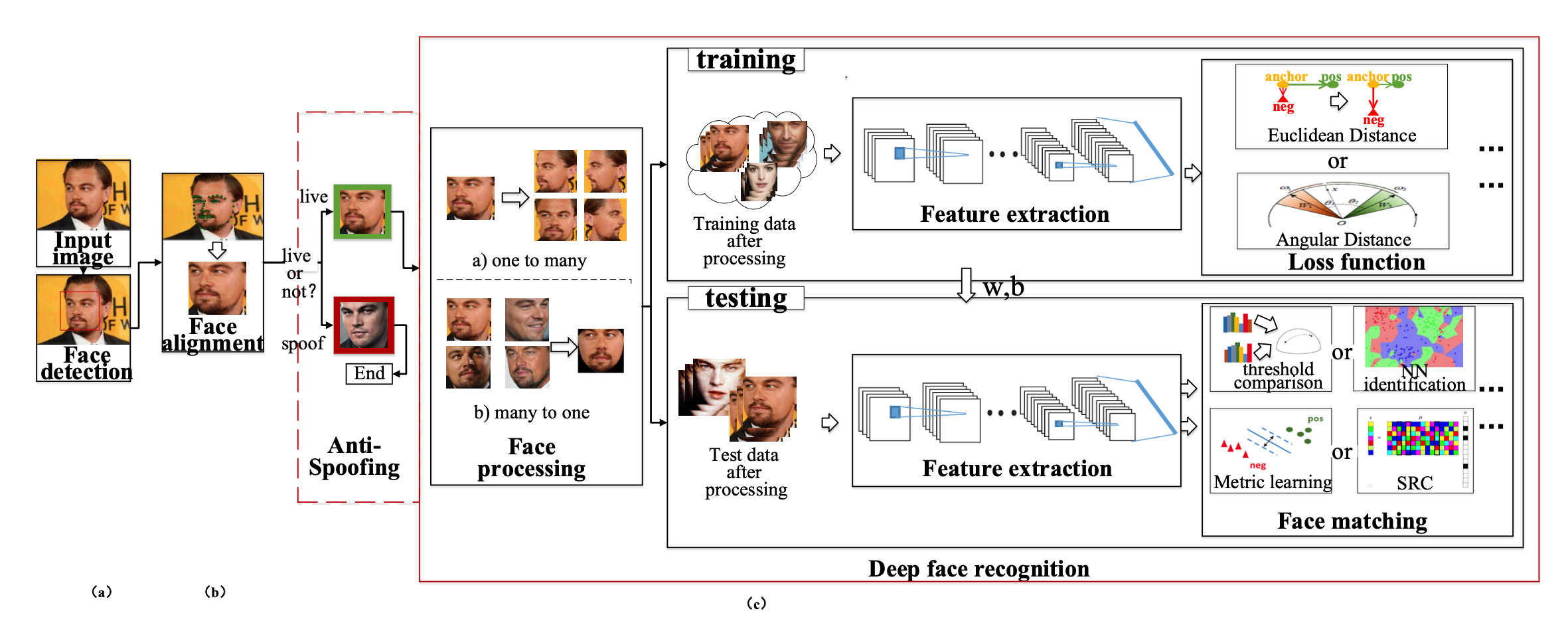
简介 一个完整的人脸识别系统包含以下几个模块 Face Detection: 人脸检测 Face Alignment:基于人脸关键点坐标对齐到正则坐标系下坐标 Face Recognition:基于对齐人脸进行识别 人脸识别的算法流程 人脸的识别流程:面部姿态处理(处理姿态,亮度,表情,遮挡),特征提取,人脸比对。 面部处理 face processing 这部分主要对姿态(主要)、亮度、表情、遮挡进行处理,可提升FR模型性能 主要包含两种处理方式: 1. "Onetomany Augmentation": 从单个图像生成不同姿态的图像,使模型学习到姿态不变性的表示 1. "Manytoone Normalization": 从多个不同姿态的图像中恢复人脸图像的标准视图 特征提取 Backb...
Computer Vision
2026-01-11
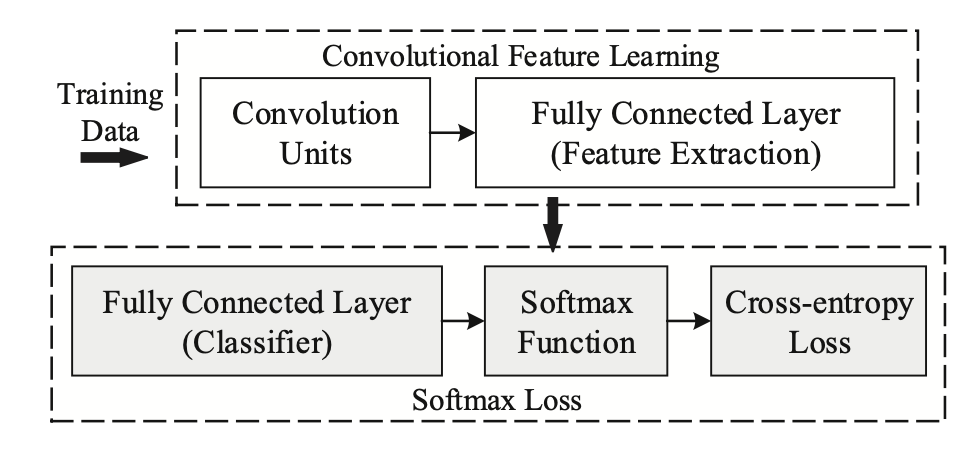
近期,人脸识别研究领域的主要进展之一集中在了 Softmax Loss 的改进之上;本文从两种主要的改进方式——做归一化以及增加类间 margin——展开梳理,介绍了近年来基于 Softmax 的 Loss 的研究进展。 Softmax简介 Softmax Loss 因为其易于优化,收敛快等特性被广泛应用于图像分类领域。然而,直接使用 softmax loss 训练得到的 feature 拿到 retrieval,verification 等“需要设阈值”的任务时,往往并不够好。 这其中的原因还得从 Softmax 的本身的定义说起,Softmax loss 在形式上是 softmax 函数加上交叉熵损失,它的目的是让所有的类别在概率空间具有最大的对数似然,也就是保证所有的类别都能分类正确,...