Computer Vision
2026-01-11
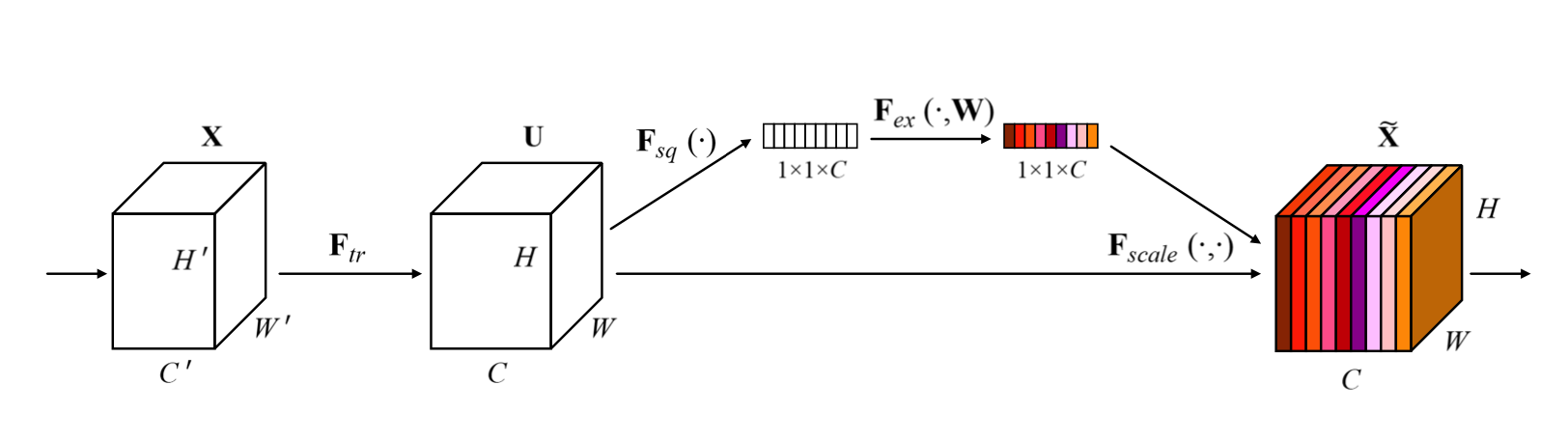
SENet SE模块比较简单,目的是对特征通道进行重新加权,如上图所示 CBAM: Convolutional Block Attention Module CBAM考虑了在channel和空间尺度两个层面分别进行attention,如上图所示,方法也很简单分别在channel和空间维度上进行avg pooling 和max pooling,然后汇合在一起。