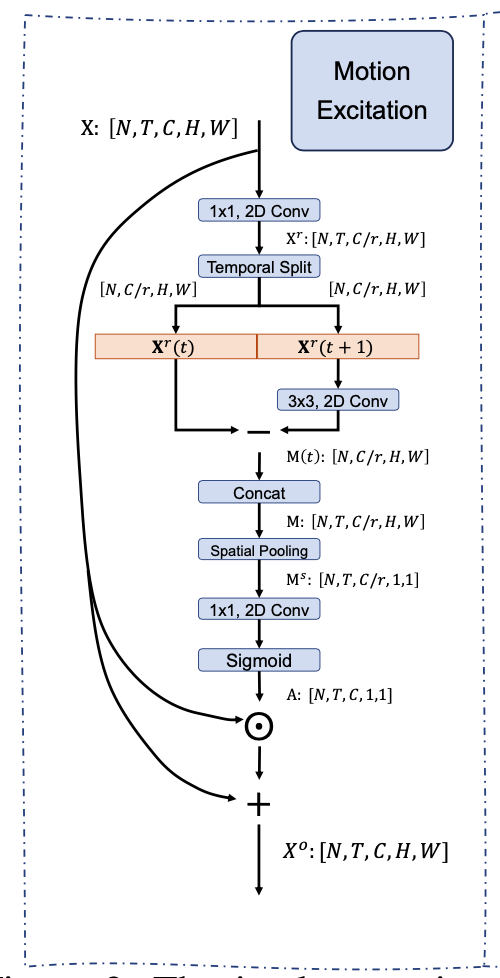
Motivation Motion feature 学习过程中存在的问题: 利用 optical flow 存储和计算的开销太大 现阶段的网络设计,spatiotemporal 建模 和Motion feature 建模分离 比如STM 直接 Add spatio temporal feature 和 motion encoding feature TEA 的 ME 则利用了 Motion feature 做 channeI attention 过去的建模都 focus 在 framelevel motion,更好的建模方式 featurelevel motion 长时建模存在的问题: 单帧过backbone,最后的feature 进行 temporal max/average poolin...
3D Model
2026-01-11

研究动机 目前 3Dbased 的方法在大规模的 scenebased 的数据集(如kinetics)上相对于2D的方法取得了更好的效果,但是3Dbased也存在一些明显的问题: 3Dbased 的网络参数量大,计算开销大,训练的 scheduler 更长,inference latency 明显慢于 2Dbased 的方法。 3D卷积其实并不能很好得学到时序上信息的变化,而且3D卷积学出来的时序Kernel的weight的分布基本一致,更多的还是对时序上的信息做一种 smooth aggregation。这一点在之前的工作TANet 中有比较详细的讨论。也基于此,3Dbased 的网络在SomethingSomething这种对时序信息比较敏感的video数据集上并不能取得很好的效果( 得...
3D Model
2026-01-11

Classification,Detection Classification:给定预先裁剪好的视频片段,预测其所属的行为类别 Detection:视频是未经过裁剪的,需要先进行人的检测where和行为定位(分析行为的始末时间)when,再进行行为的分类what。 通常所说的行为识别更偏向于对时域预先分割好的序列进行行为动作的分类,即 Trimmed Video Action Classification。 TwoStream Twostream convolutional networks 简介 TwoStream CNN网络顾名思义分为两个部分, 1. 空间流处理RGB图像,得到形状信息; 1. 时间流/光流处理光流图像,得到运动信息。 两个流最后经过softmax后,做分类分数的融合,...
Computer Vision
2026-01-11
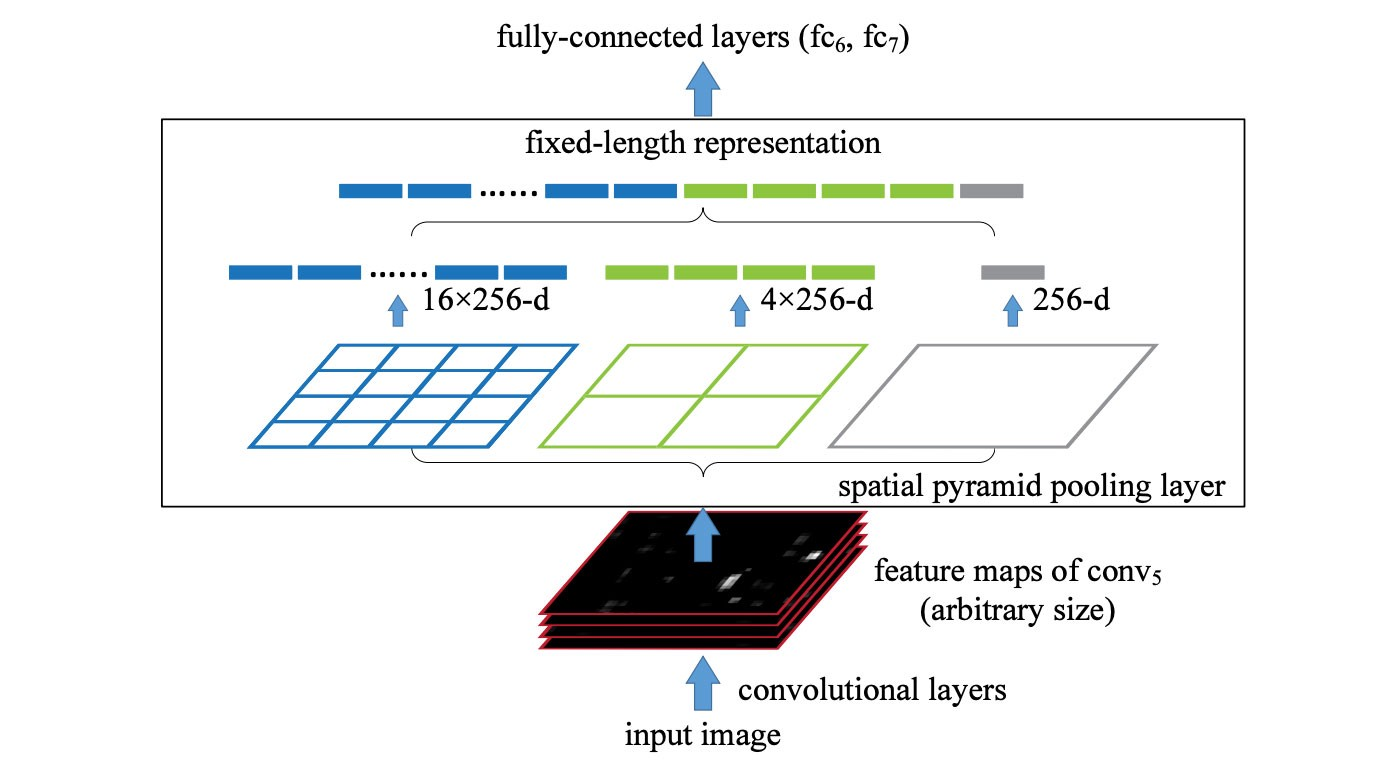
SPP (spatial pyramid pooling layer) SPP applies a slightly different strategy in detecting objects of different scales. It replaces the last pooling layer (after the last convolutional layer) with a spatial pyramid pooling layer. The feature maps are spatially divided into m×m bins with m, say, equals 1, 2, and 4 respectively. Then a maximum pool i...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...
Computer Vision
2026-01-11

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是Endtoend。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他...
Large Model
2026-01-11

UITARS 简介 UITARS(User Interface Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型: 输入方式:仅使用屏幕截图作为视觉输入 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等) 模型特性:端到端的原生智能体模型,无需复杂的中间件或框架 传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: 平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。 模块化...
Computer Vision
2026-01-11

一、IOU(Intersection over Union) 1. 特性(优点) IoU就是我们所说的交并比,是目标检测中最常用的指标,在anchorbased的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和groundtruth的距离。 1. 可以说它可以反映预测检测框与真实检测框的检测效果。 1. 还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性) [代码] 2. 作为损失函数会出现的问题(缺点) 1. 如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重...
Computer Vision
2026-01-11

Introduction 目标检测中NMS需要依据候选检测目标的排序来进行筛选框,如果分类得分较低,但是定位框准确会导致在NMS中将该bbox框被排除掉,因此这个排序的可靠性就非常重要。之前的工作主要采用IOU分支(IOUNet)与Centerness得分(FCOS)来作为大量候选检测的排序依据。 然而,本文认为这些方法可以有效缓解分类得分和物体定位精度之间的不对齐问题。 但是,它们是次优解的,因为将两个不完善的预测相乘可能会导致排名依旧变差,作者经过试验表明,通过这种方法实现的性能上限非常有限。 此外,增加一个额外的网络分支来预测定位分数并不是一个很好的解决方案,并且会带来额外的计算负担。 基于上述分析,作者提出:不采用预测一个额外的定位精确度得分(IOUaware Centerness)...
Computer Vision
2026-01-11
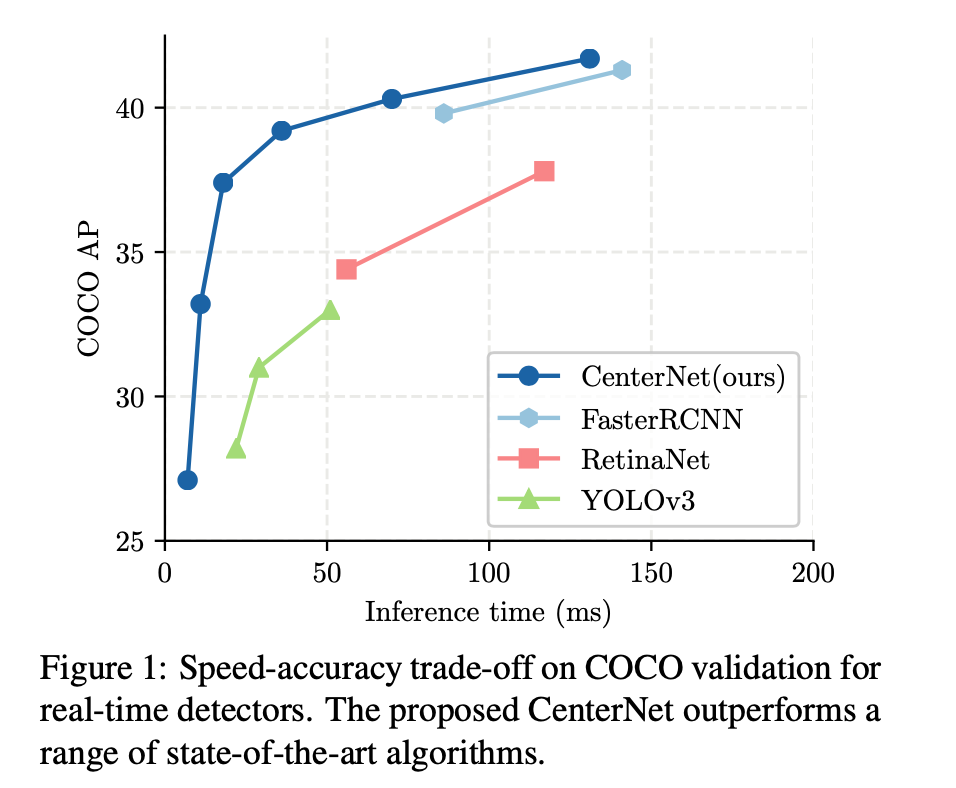
前言 anchorfree目标检测属于anchorfree系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于onestage和twostage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet的精度比YOLOv3提高了4个左右的点。 CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如肢体识别或者3D目标检测等等。 那CenterNet相比于之前的onestage和twostage的目标检测有什么特点? CenterNet的“anchor”仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是...
Computer Vision
2026-01-11

网络整体介绍 ThunderNet的整体架构如下图所示。 ThunderNet使用320×320像素作为网络的输入分辨率。整体的网络结构分为两部分:Backbone部分和Detection部分。网络的骨干部分为SNet,SNet是基于ShuffleNetV2进行修改得到的。 网络的检测部分,利用了压缩的RPN网络,修改自LightHead RCNN网络用以提高效率。 并提出Context Enhancement Module整合局部和全局特征增强网络特征表达能力。 并提出Spatial Attention Module空间注意模块,引入来自RPN的前后景信息用以优化特征分布。 backbone 部分 1.输入分辨率 为了加快推理(前向操作)速度,作者使用320320大小的输入图像。需要注意的...
Computer Vision
2026-01-11
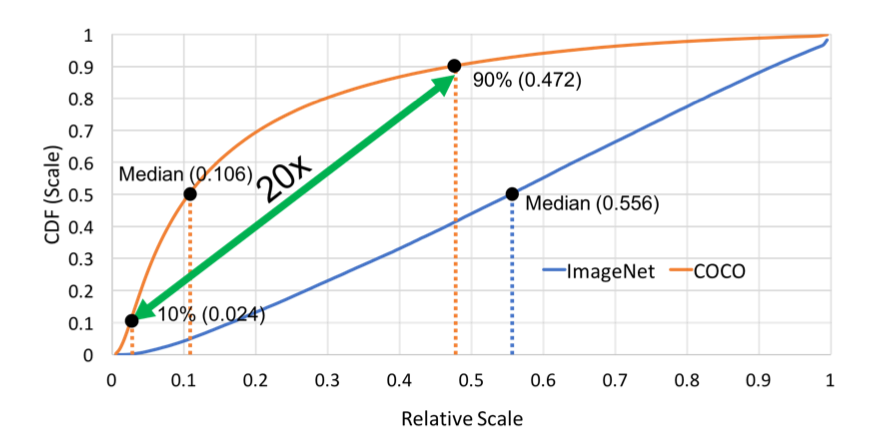
1. 检测任务的困难 图像分类算法,比如ResNeXt101 32 × 48d网络结构,在Imagenet数据集上的Top5准确率已经98%左右,Top1为85%。对于图像检测算法,最好的模型在coco数据集上的效果 AP_{50} 为62%,显然,总体上来看,准确率差了20个点左右,那么问题来了,为什么检测算法比识别算法的效果低这么多呢? 1.1 尺度差异 作者认为原因在于,检测任务中的目标存在较大的尺度变化(large scale variation)。作者统计了Imagenet和COCO数据集的特点,如下图, 其中,横坐标表示目标相对于原图的比例,纵坐标表示累计分布(cumulation distribution function)。显然,由图中可以看出,COCO数据集中50%的目标相...