背景 RLHF 通常包括三个阶段: 有监督微调(SFT) RLHF首先通过在高质量数据上进行监督学习来微调预训练的语言模型,得到模型 \(\pi_{SFT}\) 。 奖励建模阶段 (Reward Model) 在第二阶段,SFT模型根据提示 \(x\) 生成答案对 \((y_1, y_2) \sim \pi_{SFT}(y|x)\) 。这些答案对呈现给人类标注者,他们表达对一个答案的偏好,表示为 \(y_w \succ y_l|x\) ,其中 \(y_w\) 和 \(y_l\) 分别表示在 \((y_1, y_2)\) 中更受偏好和不受偏好的答案。 这些偏好被假定由某个潜在的奖励模型 \(r^*(y, x)\) 生成,我们无法直接访问该模型。一种流行的建模偏好的方法是Bradley-Terry(BT)模型,该模型规定人类偏好分布 \(p^*\) 可以写为: \[p^*(y_1 \succ y_2|x) = \frac{\exp(r^*(x, y_1))}{\exp(r^*(x, y_1)) + \exp(r^*(x, y_2))}
\] 假设我们有一个从 \(p^*\)...
Reinforcement Learning
2026-03-30

引言 时序差分(Temporal-Difference,TD)方法是强化学习中的一类核心算法,它结合了动态规划与蒙特卡洛方法的优点。TD方法是无模型(model-free)学习方法,不需要环境模型即可学习价值函数和最优策略。 TD方法的核心特点是通过比较不同时间步骤的估计值之间的差异来更新价值函数,这种差异被称为"时序差分误差"(TD error)。TD方法可以被视为解决贝尔曼方程或贝尔曼最优方程的特殊随机逼近算法。 基础TD算法:状态值函数学习 给定策略 \(\pi\) ,基础TD算法用于估计状态值函数 \(v_\pi(s)\) 。假设我们有一些按照策略 \(\pi\) 生成的经验样本 \((s_0, r_1, s_1, ..., s_t, r_{t+1}, s_{t+1}, ...)\) ,TD算法的更新规则为: \[\begin{equation}\begin{aligned}v_{t+1}(s_t) &= v_t(s_t) - \alpha_t(s_t)[v_t(s_t) - (r_{t+1} + \gamma v_t(s_{t+1}))]\\
v_{t+1}(s) &=...
Reinforcement Learning
2026-03-30
引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为: 如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验 。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 \(X\) 中值的随机变量 \(X\) ,我们的任务是计算 \(X\) 的均值或期望值: \(E[X]\) 有两种方法可以计算 \(E[X]\) : 基于模型的方法 :当已知随机变量的概率分布时,可以直接根据期望值的定义计算: \[E[X] = \sum_{x \in X} p(x) \cdot x\] 其中 \(p(x)\) 是 \(X\) 取值为 \(x\)...
最优策略(Optimal Policy ) 之前在 贝尔曼方程(Bellman Equation) 中说过, 状态值可以用来评估一个策略是好是坏 ,这里给出正式的概念: \[v_{\pi_1}(s) \geq v_{\pi_2}(s) \quad \text { for all } s \in \mathcal{S}\] 那么此时 \(\pi_1\) 比 \(\pi_2\) ”更好“ 最优状态值(Optimal State Value) : 对于任意状态 \(s\) ,最优状态值 \(v^*(s)\) 是所有可能策略中状态值的最大值: \[v^*(s) = \max_{\pi} v_{\pi}(s)\] 其中 \(v_{\pi}(s)\) 是策略 \(\pi\) 下的状态值。 最优策略(Optimal Policy) : 如果一个策略的状态值在所有状态中均大于或等于其他策略的状态值,则该策略为最优策略: \[\pi^* = \arg\max_{\pi} v_{\pi}(s), \forall s \in S\] 即最优策略总是选择使得状态值最大的动作。 性质 : 存在性...
Reinforcement Learning
2026-03-27
状态价值(State values) 定义 状态价值是强化学习中的核心概念,用于衡量Agent从某个状态出发、遵循特定策略后所能获得的期望回报。 数学表达为: \[
v_\pi(s) = \mathbb{E}[G_t | S_t = s]
\tag{1}\] 其中: \(v_\pi(s)\) :状态 \(s\) 的状态价值函数(state-value function) 或者简称为 状态价值(state value); \(\pi\) :智能体遵循的策略; \(G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots\) :从当前时间步 \(t\) 开始的折扣回报; \(\gamma \in (0, 1)\) :折扣因子,用于平衡即时奖励和未来奖励。 状态价值的特点 依赖于状态 \(s\) :状态价值是条件期望,条件是智能体从状态 \(s\) 开始。 依赖于策略 \(\pi\) :不同策略会生成不同的轨迹,从而影响状态价值。 与时间步无关 :状态价值是一个固定值,与当前时间步 \(t\) 无关。 代表一个状态的价值。...
Reinforcement Learning
2026-03-27

引言 强化学习中,找到最优策略是核心目标。本文详细介绍三种能够找到最优策略的基础算法: 价值迭代、策略迭代和截断策略迭代 。这些算法属于动态规划范畴,需要系统模型,是后续无模型强化学习算法的重要基础。 在强化学习的发展路线中,这些算法处于"基础工具"到"算法/方法"的过渡阶段,是从"有模型"到"无模型"学习的重要桥梁。 价值迭代(Value iteration) 价值迭代算法 基于收缩映射定理求解贝尔曼最优方程 。其核心迭代公式为: \[\begin{equation}v_{k+1} = \max_{\pi \in \Pi} (r_\pi + \gamma P_\pi v_k), k = 0, 1, 2, ...\tag{1}\end{equation}\] 根据收缩映射定理,当 \(k \to \infty\) 时, \(v_k\) 和 \(\pi_k\) 分别收敛到最优状态值和最优策略。 每次迭代包含两个步骤: 策略更新步骤 (policy update step) :找到能解决以下优化问题的策略 \[\pi_{k+1} = \arg\max_\pi (r_\pi +...
Reinforcement Learning
2026-03-27

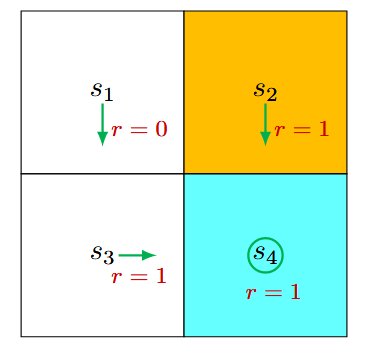
基础概念 Grid-Word Example 环境描述 :网格世界是一个直观的二维环境,包含: 白色格子 :可通行区域。 橙色格子 :禁止进入的区域(禁区)。 目标格子 :代理需要到达的目标位置。 任务目标 : 找到一条“好的”策略,使代理从任意初始位置到达目标格子。 策略应避免进入禁区、碰撞边界或走不必要的弯路。 什么是强化学习:依据策略执行动作-感知状态-得到奖励 所谓强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。 a computational approach to learning whereby an agent tries to maximize the total amount of reward it receives while interacting with a complex and uncertain environment 经典的强化学习模型可以总结为下图的形式(你可以理解为任何强化学习都包含这几个基本部分:智能体、行为、环境、状态、奖励):...

💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Generative Model
2026-03-04

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Math
2026-03-02

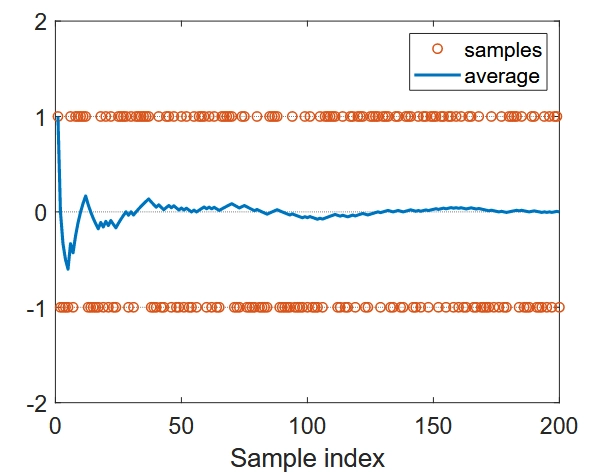
引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 \(X\) ,其取值来自有限集合 \(\mathcal{X}\) 。我们的目标是估计 \(E[X]\) 。假设我们有一个独立同分布的样本序列 \(\{x_i\}_{i=1}^n\) ,那么 \(X\) 的期望值可以近似为: \[E[X] \approx \bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\] 非增量方法与增量方法 非增量方法 :先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法 :定义 \[w_{k+1} = \frac{1}{k}\sum_{i=1}^k x_i, k = 1, 2, ...\] 可以推导出递归公式: \[{w}_{k + 1} =...
Self-Supervised
2026-01-23
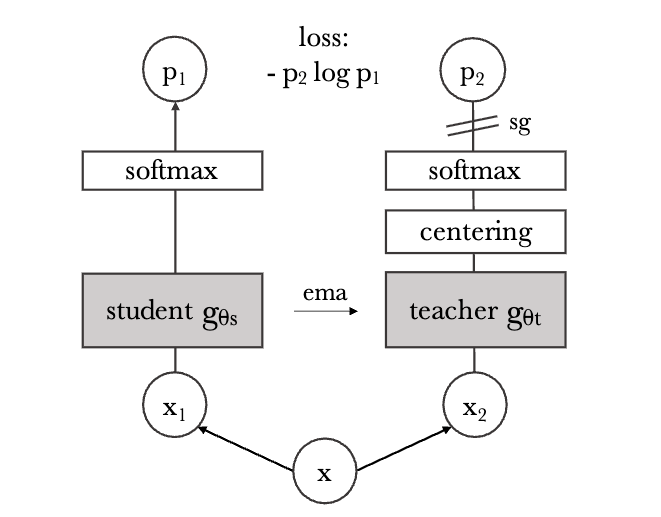
DINO Emerging Properties in Self-Supervised Vision Transformers 论文地址: arxiv.org/pdf/2104.14294 DINO摇摆到了动量式更新,果然【加动量】还是比【只用梯度停止】香。DINO的名字来自于Self- di stillation with no labels中的蒸馏和No标签。 DINO的训练步骤 其实以前的对比学习方案也可以理解为知识蒸馏,DINO里更具体得描述了知识蒸馏的含义。 下图展示了一个样本通过数据增强得到一对views \((x_1,x_2)\) 。注意DINO后面还会使用更复杂的裁剪和对比方案,但这里简单起见先不考虑那些。模型将输入图像的两种不同的随机变换 \(x_1\) 和 \(x_2\) 分别传递给学生和教师网络。 这两个网络具有相同的架构,但参数不同 。教师网络的输出以batch内计算的平均值,进行中心化(减去均值)。每个网络输出一个 \(K\)...