129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...
Generative Model
2026-01-19
基于文章 《Elucidating the Design Space of Diffusion-Based Generative Models》 来统一扩散模型框架 通用扩散模型框架推导 加噪公式 Flow Matching的一步加噪公式 \[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\varepsilon\] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;(1-t)\mathbf{x}_0,t^2\mathbf{I})\] Score Matching的一步加噪公式 \[\mathbf{x}_t=\mathbf{x}_0+\sigma_t\varepsilon \] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2\mathbf{I})\] DDPM/DDIM的一步加噪公式...
Deep Learning
2026-01-11
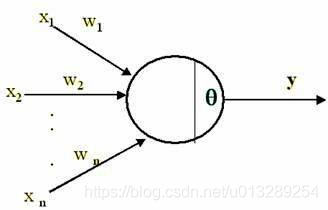
1.深度学习偏置的作用? 我们在学深度学习的时候,最早接触到的神经网络应该属于感知器(感知器本身就是一个很简单的神经网络,也许有人认为它不属于神经网络,当然认为它和神经网络长得像也行) 要想激活这个感知器,使得 y=1 ,就必须使 x_1w_1 + x_2w_2 +....+x_nw_n T ( T 为一个阈值),而 T 越大,想激活这个感知器的难度越大,人工选择一个阈值并不是一个好的方法,因为样本那么多,我不可能手动选择一个阈值,使得模型整体表现最佳,那么我们可以使得T变成可学习的,这样一来, T 会自动学习到一个数,使得模型的整体表现最佳。当把T移动到左边,它就成了偏置, x_1w_1 + x_2w_2 +....+x_nw_n T 0 xw +b 0 ,总之,偏置的大小控制着激活这个感...
Deep Learning
2026-01-11
一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。 还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到 [Math] 等操作),所以没法直接用。 这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀...
Deep Learning
2026-01-11
如何计算RF 公式一:这个算法从top往下层层迭代直到追溯回input image,从而计算出RF。 [公式] 其中,RF是感受野。RF和RF有点像,N代表 neighbour,指的是第n层的 a feature在n1层的RF,记住N_RF只是一个中间变量,不要和RF混淆。 stride是步长,ksize是卷积核大小。
Large Model
2026-01-11

这是OpenCompass的offitial ranking 榜单 🔖 https://rank.opencompass.org.cn/home MMBench 鉴于现行评测方式所存在的问题,我们重新定义了一套针对当前多模态大模型的评测流程——MMBench。其主要包含两个方面: 自上而下的能力维度设计,根据定义的能力维度构造了一个评测数据集 引入 ChatGPT,以及提出了 CircularEval 的评测方式,使得评测的结果更加稳定 Paper 链接: 🔖 https://arxiv.org/pdf/2307.06281 github: 数据集 数据集构造 主要目的是对模型的各种能力进行全方位的考察,所以我们自上而下定义了三级能力维度 (L1L3), 第一级维度(L1)包含感知与推理两项...
Generative Model
2026-01-11

Diffusion Models from SDE 连续扩散模型 (Continuous Diffusion Models) 将传统的离散时间扩散过程扩展到连续时间域,可以被视为一个随机过程,使用随机微分方程(SDE)来描述。其前向过程可以写成如下形式: [公式] 其中, f(x,t) 可以看成偏移系数, g(t) 可以看成是扩散系数, dw 是标准布朗运动。这个SDE 描述了数据在连续时间域内如何被噪声逐渐破坏。 这个随机过程的逆向过程存在(更准确的描述:下面的逆向时间SDE具有与正向过程SDE相同的联合分布)为 [公式] 前面我们得到了扩散过程的逆向过程可以用一个SDE描述(逆向随机过程),事实上,存在一个确定性过程 (用ODE描述)也是它的逆向过程 (更准确的描述:这个ODE过程的在任...
Deep Learning
2026-01-11

最近,似乎现在每个大型语言模型(LLM)和新闻中提到的复杂神经网络架构都使用略有不同的激活函数,而就在几年前,最常见的做法只是在神经网络的内部层中使用 ReLU。 曾经优秀的 ReLUs 怎么了,以及是什么促使最新的大型语言模型(LLMs)的创造者们开始使用不同的(更高级的)激活函数? Threshold activation (Perceptron) 1957 年,罗森布拉特建造了“感知机” 最古老的激活函数是基本感知器。它由芝加哥大学精神病学系的爱德华·麦克洛奇和沃尔特·皮茨构思,后来由弗兰克·罗森布拉特在 1957 年于康奈尔航空实验室为美国海军在硬件上更著名地实现了。该算法非常简单,其基本规则是:如果某个值超过某个阈值,则返回 1,否则返回 0。有些变体会返回 1 或1。 由于其二元...
Deep Learning
2026-01-11

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 X ,其取值来自有限集合 [Math] 。我们的目标是估计 E[X] 。假设我们有一个独立同分布的样本序列 \{x_i\}_{i=1}^n ,那么 X 的期望值可以近似为: [公式] 非增量方法与增量方法 非增量方法:先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法:定义 [公式] 可以推导出递归公式: [公式] 这个算法可以增量式地...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...
Large Model
2026-01-11

模型概述 KimiVL 是一个高效的开源混合专家视觉语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(KimiVLA3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等. 模型架构 KimiVL 的架构由三个主要部分组成: MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters 视觉模型 400M nativeresolution MoonViT vision encoder. MLP Projector MoonViT: 原生...
Generative Model
2026-01-11

💡 Score based generative model SMLD的关键点: 正式开始介绍之前首先解答一下这个问题:scorebased 模型是什么东西,微分方程在这个模型里到底有什么用?我们知道生成模型基本都是从某个现有的分布中进行采样得到生成的样本,为此模型需要完成对分布的建模。根据建模方式的不同可以分为隐式建模(例如 GAN、diffusion models)和显式建模(例如 VAE、normalizing flows)。和上述的模型相同,scorebased 模型也是用一定方式对分布进行了建模。具体而言,这类模型建模的对象是概率分布函数 log 的梯度,也就是 score function,而为了对这个建模对象进行学习,需要使用一种叫做 score matching 的技术,这也...