背包问题
Search&Rec
2026-01-11

在电商搜索中,query推荐有很多种产品形态,不同的产品形态也扮演着不同的角色,常见的有query suggestion(SUG)、猜你想搜(搜索发现、大家都在搜)、细选(锦囊)、搜索底纹、搜索PUSH、搜索“风向标”(点击回退query推荐)等。以淘宝当前版本的产品形态为例,有: 上述每个方向都值得单独介绍,而本文则先整体从query推荐角度,放在一起介绍,方便横向对比各个场景的目标和方法上的异同之处。而以经典的分类方式展开,可以将query 推荐策略放在用户搜索前、搜索中、浏览中、搜索后(本章不涉及讨论)等各个状态阶段来进行比较: 目标 以上引出了搜索query推荐的两大目标: 搜索增长,目标提升提升渗透率,将用户引导到成交效率更高的搜索场景,提升搜索活跃度,常见的产品形态有:底纹、qu...
Search&Rec
2026-01-11
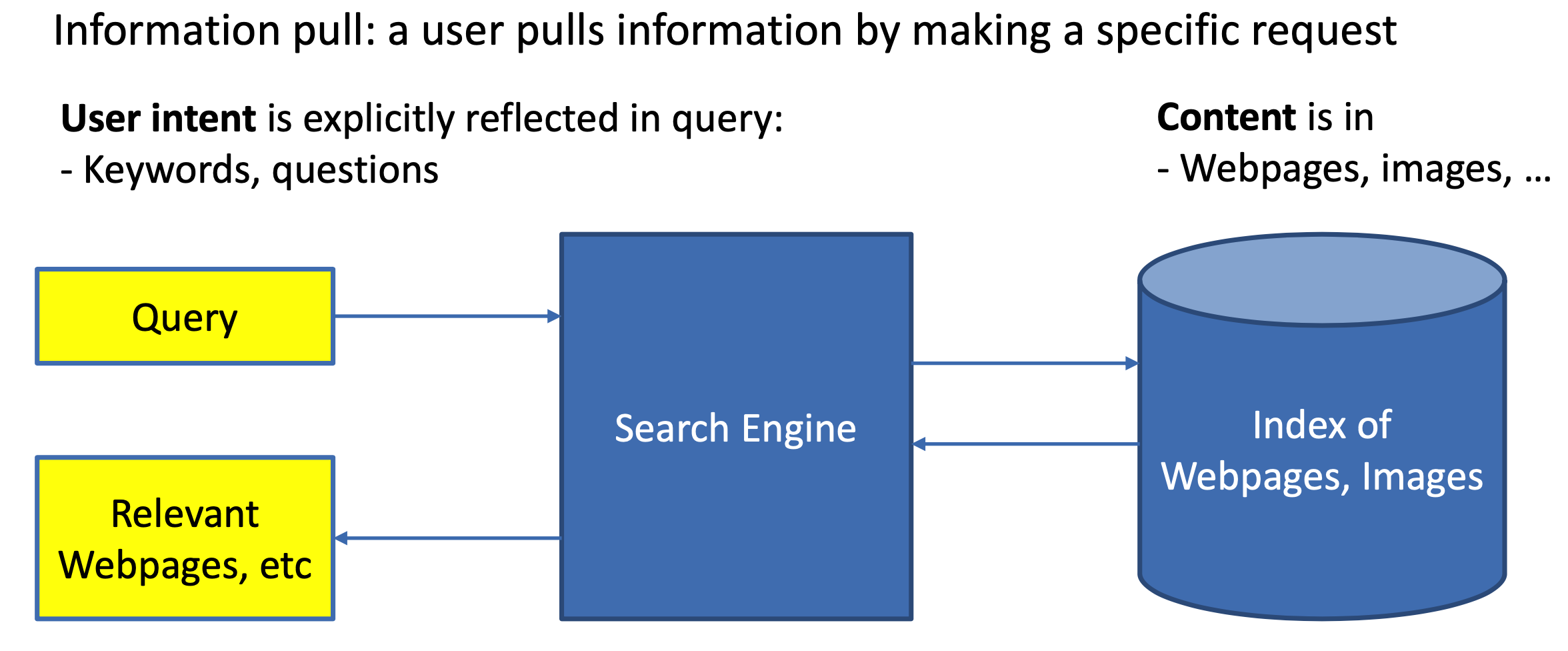
1. 搜索引擎概述 1.1 推荐和搜索比较 推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。 对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过querydoc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。 对于推荐来说,推荐系统就是系统根据用户的属性(如性别、年龄、学历等),用户在系统里过去的行为(例如浏览、点击、搜索、收藏等),以及当前上下文环境(如网络、手机设备等),从而给用户推...
Search&Rec
2026-01-11

精排是用pointwise方式对商品的CTR/CVR进行预估,旨在建模s=f(user, query, item, context) ,对候选商品进行打分。但有些情况下仅有精排还存在不足之处,如: 1、即使对单个商品进行打分,资源效率限制下,上千候选的精排有时也无法落地更加复杂的模型; 2、pointwise模式的打分无法从候选列表整体或上下文实时反馈角度出发进行排序; 3、直接使用精排分排序无法满足特殊整体性排序需求,如常见的搜索结果的多样性(如价格、地域、品牌、风格等属性的打散)、发现性、异质内容的混排调控(如商品、内容、广告等物料的混排)、流量调控等。 相应地,从以上三点出发,本文从“更加精准打分”、“关注序和上下文”、“特殊需求重排”三方面梳理重排的一般方法: 更加精准打分 重排的第...
Search&Rec
2026-01-11

讨论一下推荐系统三板斧:数据、特征和模型,因为搜索的排序套路和推荐十分类似,除了多了query维度特征,对相关性有一定的要求,其他很大程度上思想一致。 这里先行引用一个比较形象的推荐系统优化流程: 1. 明确业务目标 1. 将业务目标转化为机器学习可优化目标 1. 样本收集 1. 特征工程 1. 模型选择和训练 1. 离线评测验证 1. 在线AB验证 1. 通过离线验证和在线AB的结果反馈到2,形成一个增强回路慢慢起飞。 而在一般情况下,各个环节的贡献占比:样本特征工程模型。另外如果离线验证集85分,线上很多时候也会略低,各种原因也不胜枚举:特征延迟、特征不一致、甚至在样本落盘时的数据丢失等等。 本篇先行介绍上述过程特征工程的一般方法,包括特征设计、清洗、变换以及特征选择,并在最后讨论深度学...
Algorithm
2026-01-11

题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出:5 解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root...
Search&Rec
2026-01-11
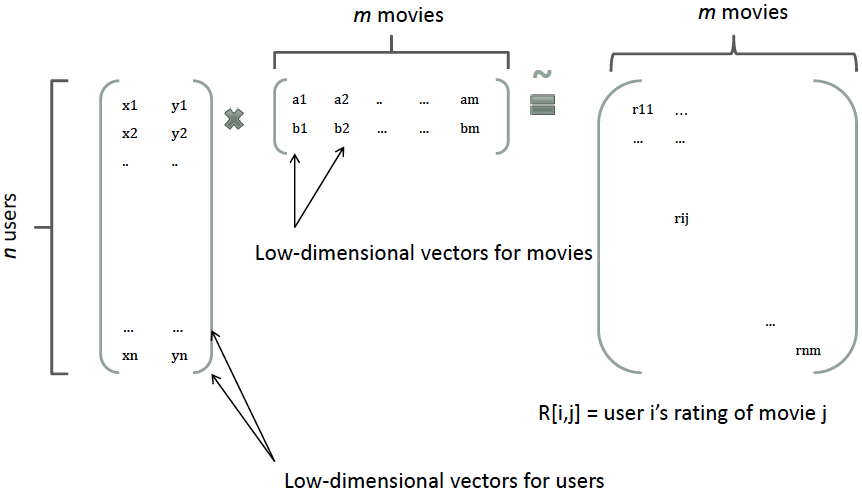
CTR预测问题简介 点击率(Click Through Rate, CTR)预估是程序化广告里的一个最基本而又最重要的问题。比如在竞价广告里,排序的依据就是 𝑐𝑡𝑟×𝑏𝑖𝑑 。通过选择 𝑐𝑡𝑟×𝑏𝑖𝑑 最大的广告就能最大化平台的eCPM。从机器学习的角度来说这是一个普通的回归问题,但是它的特殊性在于训练数据只有0/1的值——因为我们没有办法给同一个用户展示同一个广告1万次,然后统计点击的次数来估计真实的点击率。另外有人也许会有这样的看法:对于某一个特定的曝光,某个用户是否点击某个广告是确定的,第一次不点,第二次也不会点,因此点击率是一个0/1的固定值而不是一个01之间的概率值。这个说法有一些道理,原因是第二次实验和第一次使用不是独立同分布的。“真正”的做法是第二次做实验前要擦除用户第一次实验...
Search&Rec
2026-01-11
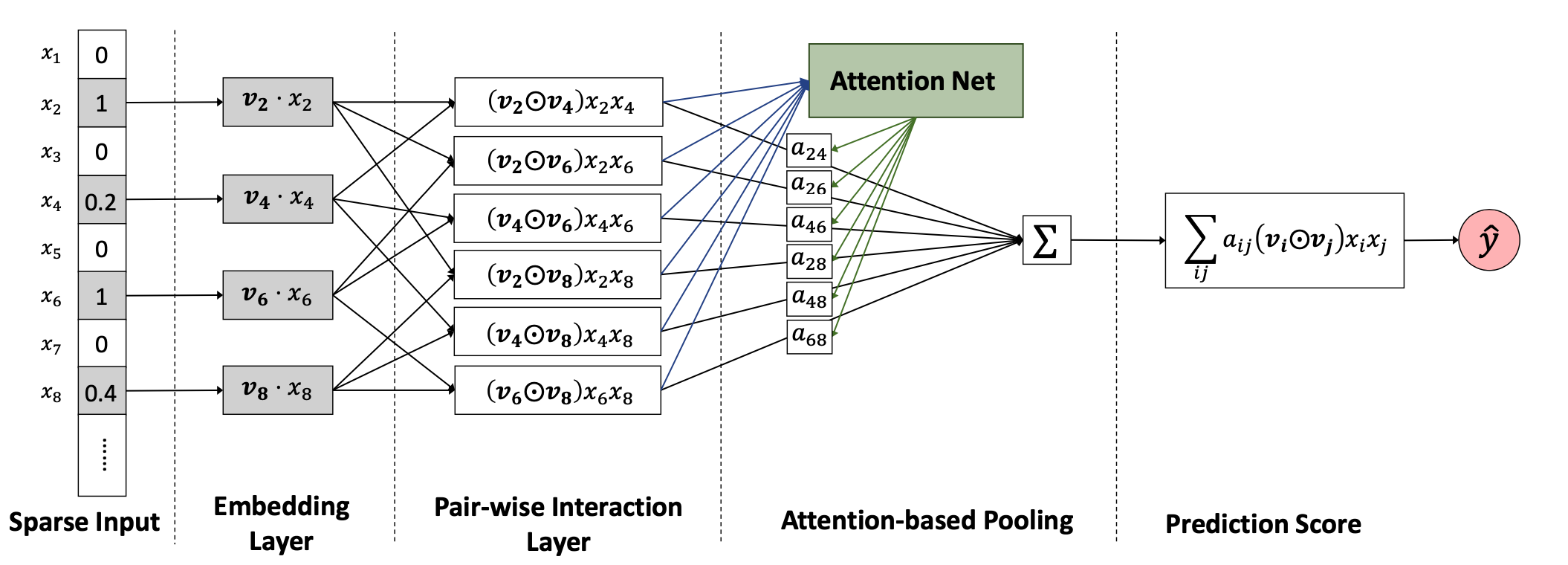
FM:Factorization Machines, 2010 —— 隐向量学习提升模型表达 参考 Untitled 优势: 可以有效处理稀疏场景下的特征学习 具有线性时间复杂度 对训练集中未出现的交叉特征信息也可进行泛化 不足: 2way的FM仅枚举了所有特征的二阶交叉信息,没有考虑高阶特征的信息 2way的FM仅枚举了所有特征的二阶交叉信息,没有考虑高阶特征的信息 FFM(Fieldaware Factorization Machine)是Yuchin Juan等人在2015年的比赛中提出的一种对FM改进算法,主要是引入了field概念,即认为每个feature对于不同field的交叉都有不同的特征表达。FFM相比于FM的计算时间复杂度更高,但同时也提高了本身模型的表达能力。FM也可以看...
Algorithm
2026-01-11
题目 Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array. Note: The number of elements initialized in nums1 and nums2 are m and n respectively. You may assume that nums1 has enough space (size that is equal to m + n) to hold additional elements from nums2. Example: [代码] Constraints: 10^9 <= nums1[i], nums2[i] <...
Machine Learning
2026-01-11
随机森林 (Random Forests) 是一种利用CART决策树作为基学习器的 Bagging 集成学习算法。随机森林模型的构建过程如下: 数据采样 作为一种 Bagging 集成算法,随机森林同样采用有放回的采样,对于总体训练集 T ,抽样一个子集 T_{sub} 作为训练样本集。除此之外,假设训练集的特征个数为 d ,每次仅选择 k(k<d) 个构建决策树。因此,随机森林除了能够做到样本扰动外,还添加了特征扰动,对于特征的选择个数,推荐值为 k=log_2d 。 树的构建 每次根据采样得到的数据和特征构建一棵决策树。在构建决策树的过程中,会让决策树生长完全而不进行剪枝。构建出的若干棵决策树则组成了最终的随机森林。 随机森林在众多分类算法中表现十分出众,其主要的优点包括: 1. 由于...
Machine Learning
2026-01-11
AdaBoost基本思路 分类问题 Adaboost 是 Boosting 算法中有代表性的一个。原始的 Adaboost 算法用于解决二分类问题,因此对于一个训练集 [公式] 其中 [Math] ,,首先初始化训练集的权重 [公式] 根据每一轮训练集的权重 D_m ,对训练集数据进行抽样得到 T_m ,再根据 T_m 训练得到每一轮的基学习器 h_m 。通过计算可以得出基学习器 h_m 的误差为 e_m [公式] 根据基学习器的误差计算得出该基学习器在最终学习器中的权重系数 [公式] 为什么这样计算弱学习器权重系数?从上式可以看出,如果分类误差率 𝑒_𝑘 越大,则对应的弱分类器权重系数 [Math] 越小。也就是说,误差率小的弱分类器权重系数越大。具体为什么采用这个权重系数公式,见AdaB...