129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...
Deep Learning
2026-01-11
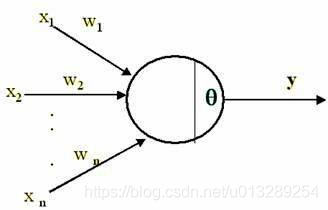
1.深度学习偏置的作用? 我们在学深度学习的时候,最早接触到的神经网络应该属于感知器(感知器本身就是一个很简单的神经网络,也许有人认为它不属于神经网络,当然认为它和神经网络长得像也行) 要想激活这个感知器,使得 y=1 ,就必须使 x_1w_1 + x_2w_2 +....+x_nw_n T ( T 为一个阈值),而 T 越大,想激活这个感知器的难度越大,人工选择一个阈值并不是一个好的方法,因为样本那么多,我不可能手动选择一个阈值,使得模型整体表现最佳,那么我们可以使得T变成可学习的,这样一来, T 会自动学习到一个数,使得模型的整体表现最佳。当把T移动到左边,它就成了偏置, x_1w_1 + x_2w_2 +....+x_nw_n T 0 xw +b 0 ,总之,偏置的大小控制着激活这个感...
Deep Learning
2026-01-11
一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。 还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到 [Math] 等操作),所以没法直接用。 这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀...
Deep Learning
2026-01-11
如何计算RF 公式一:这个算法从top往下层层迭代直到追溯回input image,从而计算出RF。 [公式] 其中,RF是感受野。RF和RF有点像,N代表 neighbour,指的是第n层的 a feature在n1层的RF,记住N_RF只是一个中间变量,不要和RF混淆。 stride是步长,ksize是卷积核大小。
Search&Rec
2026-01-11

在电商搜索中,query推荐有很多种产品形态,不同的产品形态也扮演着不同的角色,常见的有query suggestion(SUG)、猜你想搜(搜索发现、大家都在搜)、细选(锦囊)、搜索底纹、搜索PUSH、搜索“风向标”(点击回退query推荐)等。以淘宝当前版本的产品形态为例,有: 上述每个方向都值得单独介绍,而本文则先整体从query推荐角度,放在一起介绍,方便横向对比各个场景的目标和方法上的异同之处。而以经典的分类方式展开,可以将query 推荐策略放在用户搜索前、搜索中、浏览中、搜索后(本章不涉及讨论)等各个状态阶段来进行比较: 目标 以上引出了搜索query推荐的两大目标: 搜索增长,目标提升提升渗透率,将用户引导到成交效率更高的搜索场景,提升搜索活跃度,常见的产品形态有:底纹、qu...
Search&Rec
2026-01-11
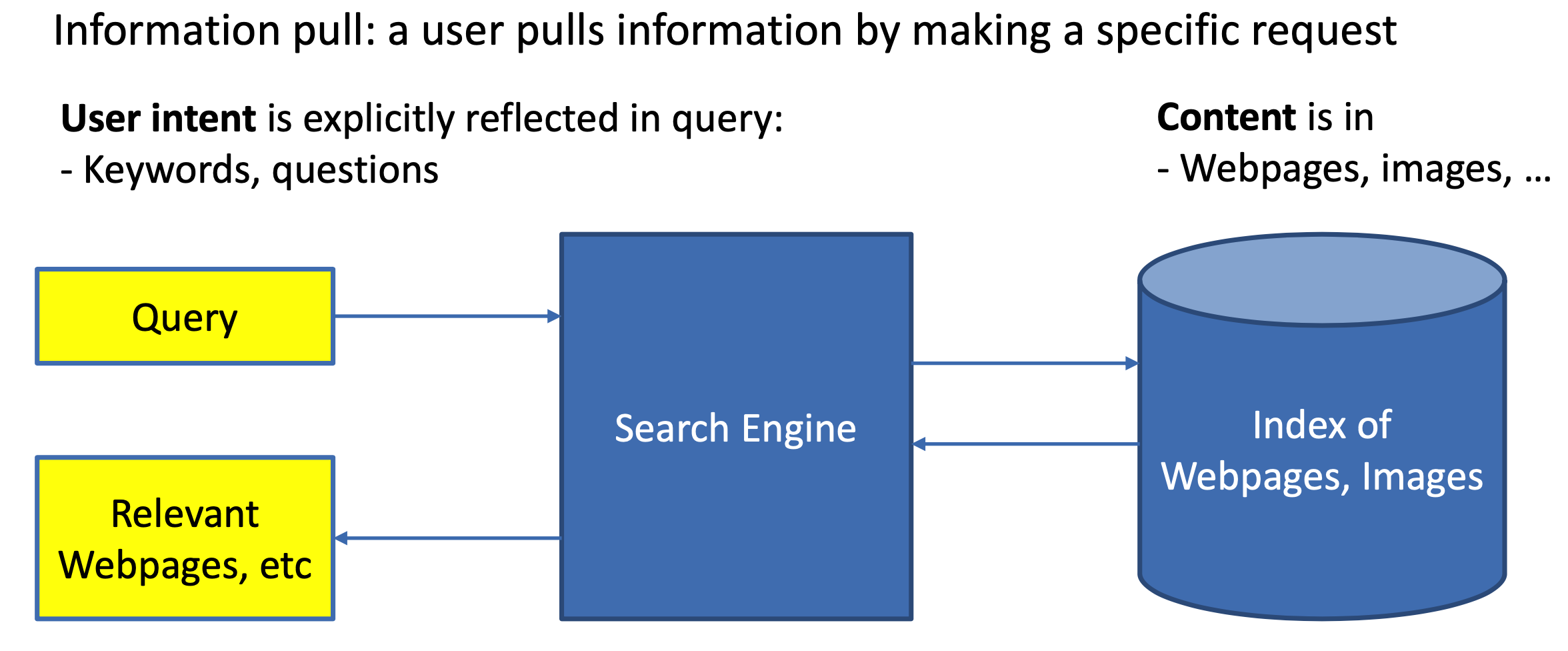
1. 搜索引擎概述 1.1 推荐和搜索比较 推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。 对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过querydoc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。 对于推荐来说,推荐系统就是系统根据用户的属性(如性别、年龄、学历等),用户在系统里过去的行为(例如浏览、点击、搜索、收藏等),以及当前上下文环境(如网络、手机设备等),从而给用户推...
Search&Rec
2026-01-11

精排是用pointwise方式对商品的CTR/CVR进行预估,旨在建模s=f(user, query, item, context) ,对候选商品进行打分。但有些情况下仅有精排还存在不足之处,如: 1、即使对单个商品进行打分,资源效率限制下,上千候选的精排有时也无法落地更加复杂的模型; 2、pointwise模式的打分无法从候选列表整体或上下文实时反馈角度出发进行排序; 3、直接使用精排分排序无法满足特殊整体性排序需求,如常见的搜索结果的多样性(如价格、地域、品牌、风格等属性的打散)、发现性、异质内容的混排调控(如商品、内容、广告等物料的混排)、流量调控等。 相应地,从以上三点出发,本文从“更加精准打分”、“关注序和上下文”、“特殊需求重排”三方面梳理重排的一般方法: 更加精准打分 重排的第...
Search&Rec
2026-01-11

讨论一下推荐系统三板斧:数据、特征和模型,因为搜索的排序套路和推荐十分类似,除了多了query维度特征,对相关性有一定的要求,其他很大程度上思想一致。 这里先行引用一个比较形象的推荐系统优化流程: 1. 明确业务目标 1. 将业务目标转化为机器学习可优化目标 1. 样本收集 1. 特征工程 1. 模型选择和训练 1. 离线评测验证 1. 在线AB验证 1. 通过离线验证和在线AB的结果反馈到2,形成一个增强回路慢慢起飞。 而在一般情况下,各个环节的贡献占比:样本特征工程模型。另外如果离线验证集85分,线上很多时候也会略低,各种原因也不胜枚举:特征延迟、特征不一致、甚至在样本落盘时的数据丢失等等。 本篇先行介绍上述过程特征工程的一般方法,包括特征设计、清洗、变换以及特征选择,并在最后讨论深度学...
Search&Rec
2026-01-11
CTR预测问题简介 点击率(Click Through Rate, CTR)预估是程序化广告里的一个最基本而又最重要的问题。比如在竞价广告里,排序的依据就是 𝑐𝑡𝑟×𝑏𝑖𝑑 。通过选择 𝑐𝑡𝑟×𝑏𝑖𝑑 最大的广告就能最大化平台的eCPM。从机器学习的角度来说这是一个普通的回归问题,但是它的特殊性在于训练数据只有0/1的值——因为我们没有办法给同一个用户展示同一个广告1万次,然后统计点击的次数来估计真实的点击率。另外有人也许会有这样的看法:对于某一个特定的曝光,某个用户是否点击某个广告是确定的,第一次不点,第二次也不会点,因此点击率是一个0/1的固定值而不是一个01之间的概率值。这个说法有一些道理,原因是第二次实验和第一次使用不是独立同分布的。“真正”的做法是第二次做实验前要擦除用户第一次实验...
Search&Rec
2026-01-11
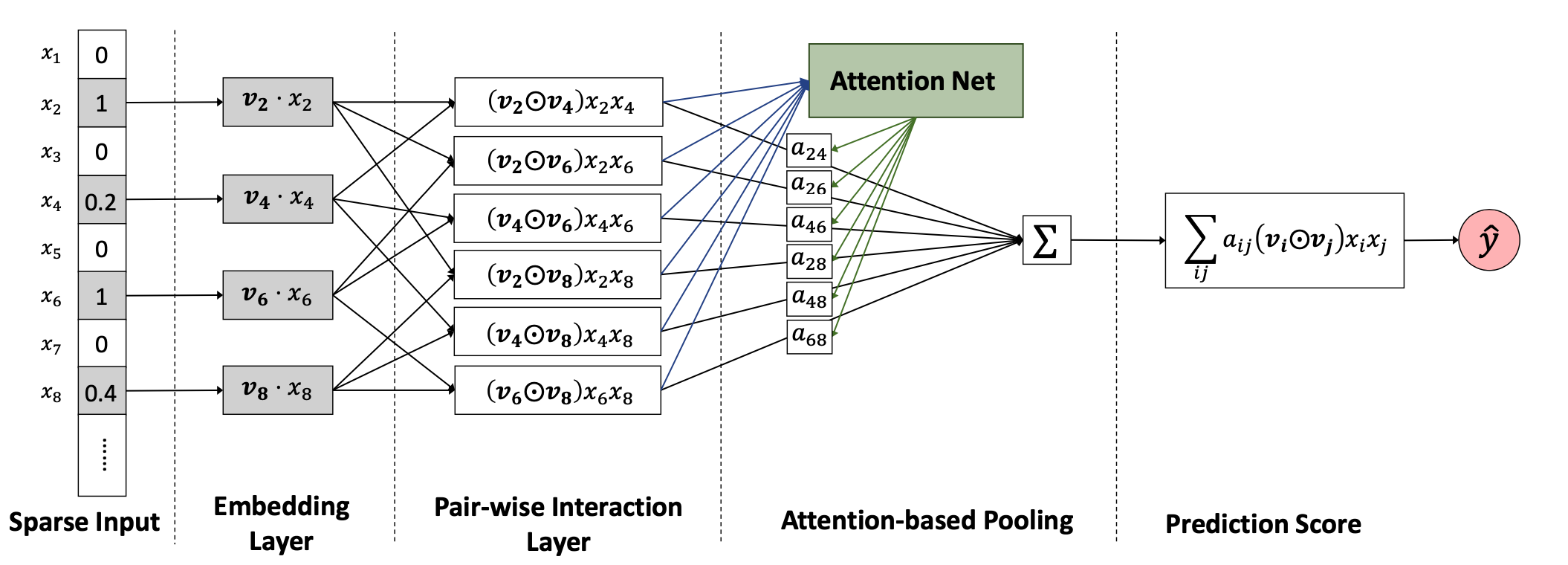
FM:Factorization Machines, 2010 —— 隐向量学习提升模型表达 参考 Untitled 优势: 可以有效处理稀疏场景下的特征学习 具有线性时间复杂度 对训练集中未出现的交叉特征信息也可进行泛化 不足: 2way的FM仅枚举了所有特征的二阶交叉信息,没有考虑高阶特征的信息 2way的FM仅枚举了所有特征的二阶交叉信息,没有考虑高阶特征的信息 FFM(Fieldaware Factorization Machine)是Yuchin Juan等人在2015年的比赛中提出的一种对FM改进算法,主要是引入了field概念,即认为每个feature对于不同field的交叉都有不同的特征表达。FFM相比于FM的计算时间复杂度更高,但同时也提高了本身模型的表达能力。FM也可以看...
Large Model
2026-01-11

这是OpenCompass的offitial ranking 榜单 🔖 https://rank.opencompass.org.cn/home MMBench 鉴于现行评测方式所存在的问题,我们重新定义了一套针对当前多模态大模型的评测流程——MMBench。其主要包含两个方面: 自上而下的能力维度设计,根据定义的能力维度构造了一个评测数据集 引入 ChatGPT,以及提出了 CircularEval 的评测方式,使得评测的结果更加稳定 Paper 链接: 🔖 https://arxiv.org/pdf/2307.06281 github: 数据集 数据集构造 主要目的是对模型的各种能力进行全方位的考察,所以我们自上而下定义了三级能力维度 (L1L3), 第一级维度(L1)包含感知与推理两项...
Deep Learning
2026-01-11

最近,似乎现在每个大型语言模型(LLM)和新闻中提到的复杂神经网络架构都使用略有不同的激活函数,而就在几年前,最常见的做法只是在神经网络的内部层中使用 ReLU。 曾经优秀的 ReLUs 怎么了,以及是什么促使最新的大型语言模型(LLMs)的创造者们开始使用不同的(更高级的)激活函数? Threshold activation (Perceptron) 1957 年,罗森布拉特建造了“感知机” 最古老的激活函数是基本感知器。它由芝加哥大学精神病学系的爱德华·麦克洛奇和沃尔特·皮茨构思,后来由弗兰克·罗森布拉特在 1957 年于康奈尔航空实验室为美国海军在硬件上更著名地实现了。该算法非常简单,其基本规则是:如果某个值超过某个阈值,则返回 1,否则返回 0。有些变体会返回 1 或1。 由于其二元...