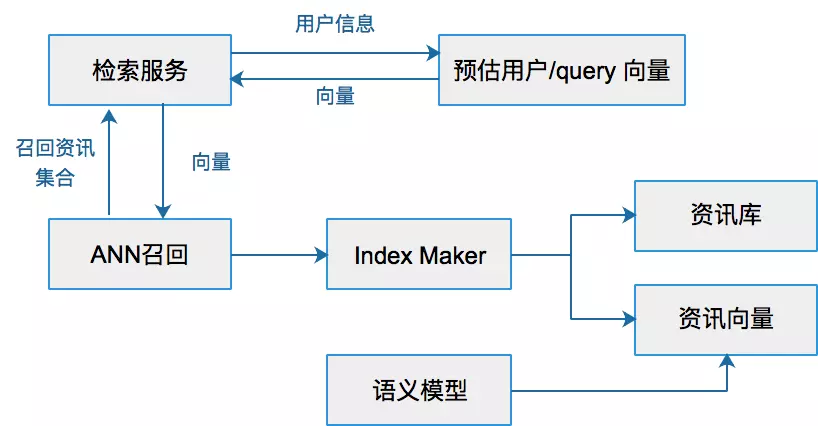
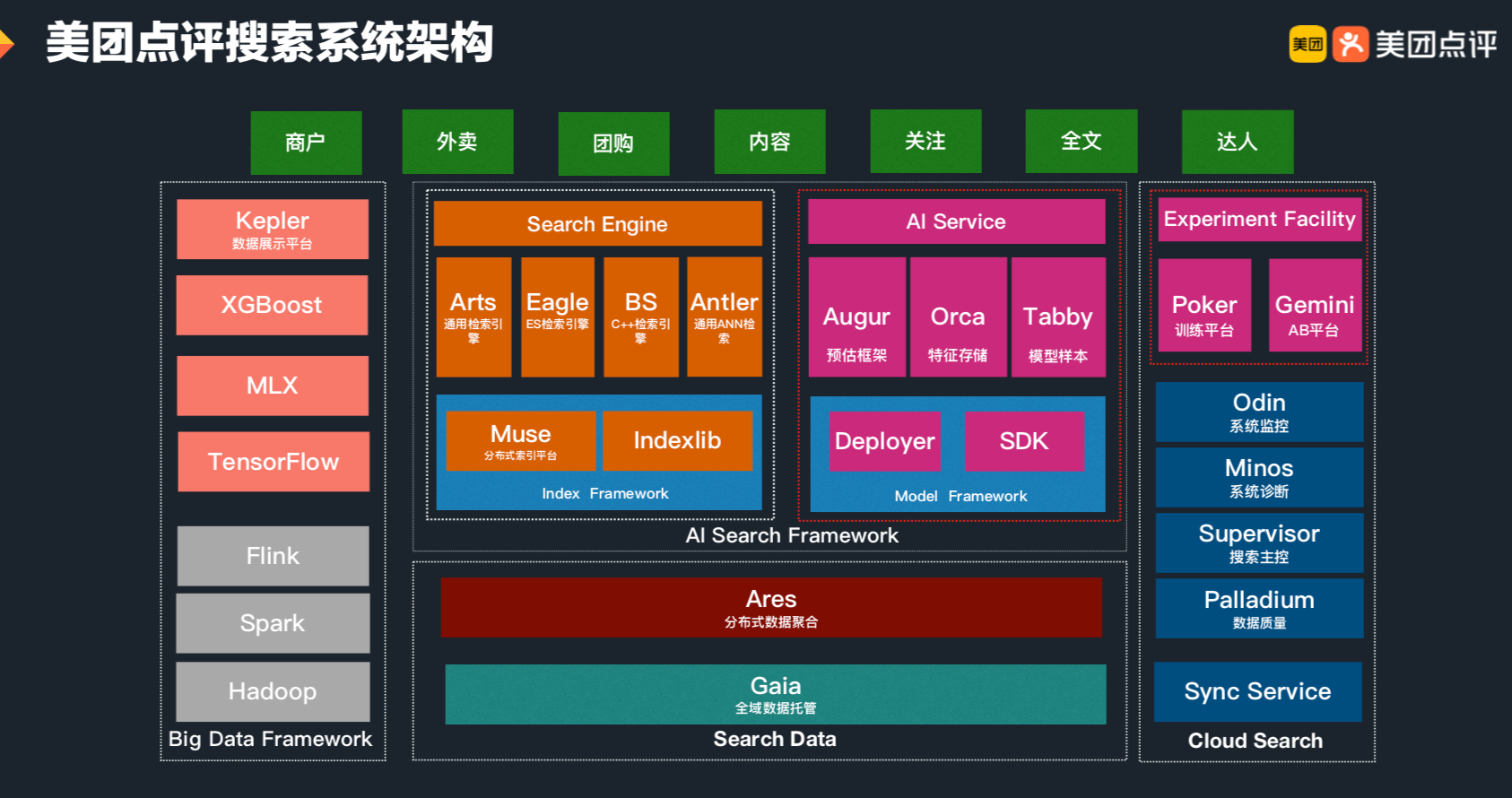
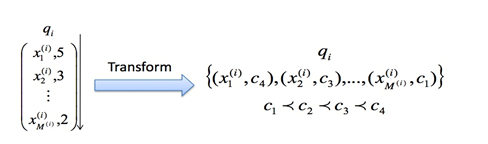Search&Rec
2026-01-11
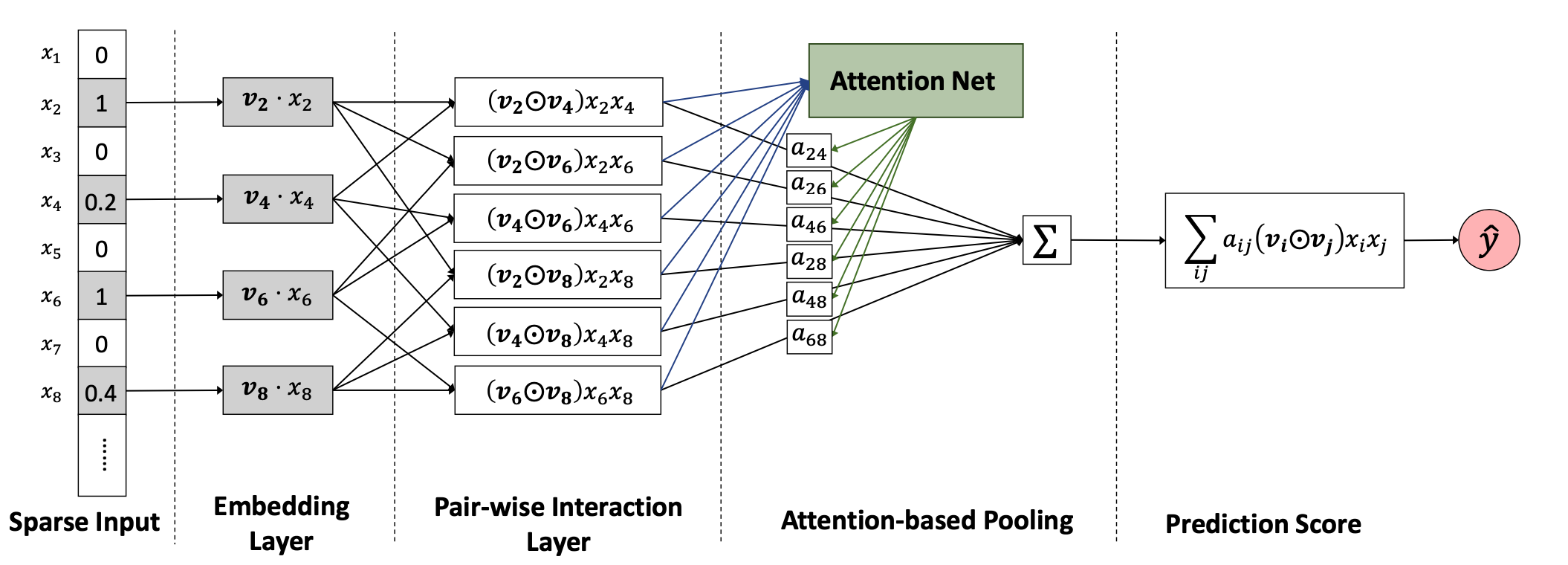
FM:Factorization Machines, 2010 —— 隐向量学习提升模型表达 参考 Untitled 优势: 可以有效处理稀疏场景下的特征学习 具有线性时间复杂度 对训练集中未出现的交叉特征信息也可进行泛化 不足: 2way的FM仅枚举了所有特征的二阶交叉信息,没有考虑高阶特征的信息 2way的FM仅枚举了所有特征的二阶交叉信息,没有考虑高阶特征的信息 FFM(Fieldaware Factorization Machine)是Yuchin Juan等人在2015年的比赛中提出的一种对FM改进算法,主要是引入了field概念,即认为每个feature对于不同field的交叉都有不同的特征表达。FFM相比于FM的计算时间复杂度更高,但同时也提高了本身模型的表达能力。FM也可以看...