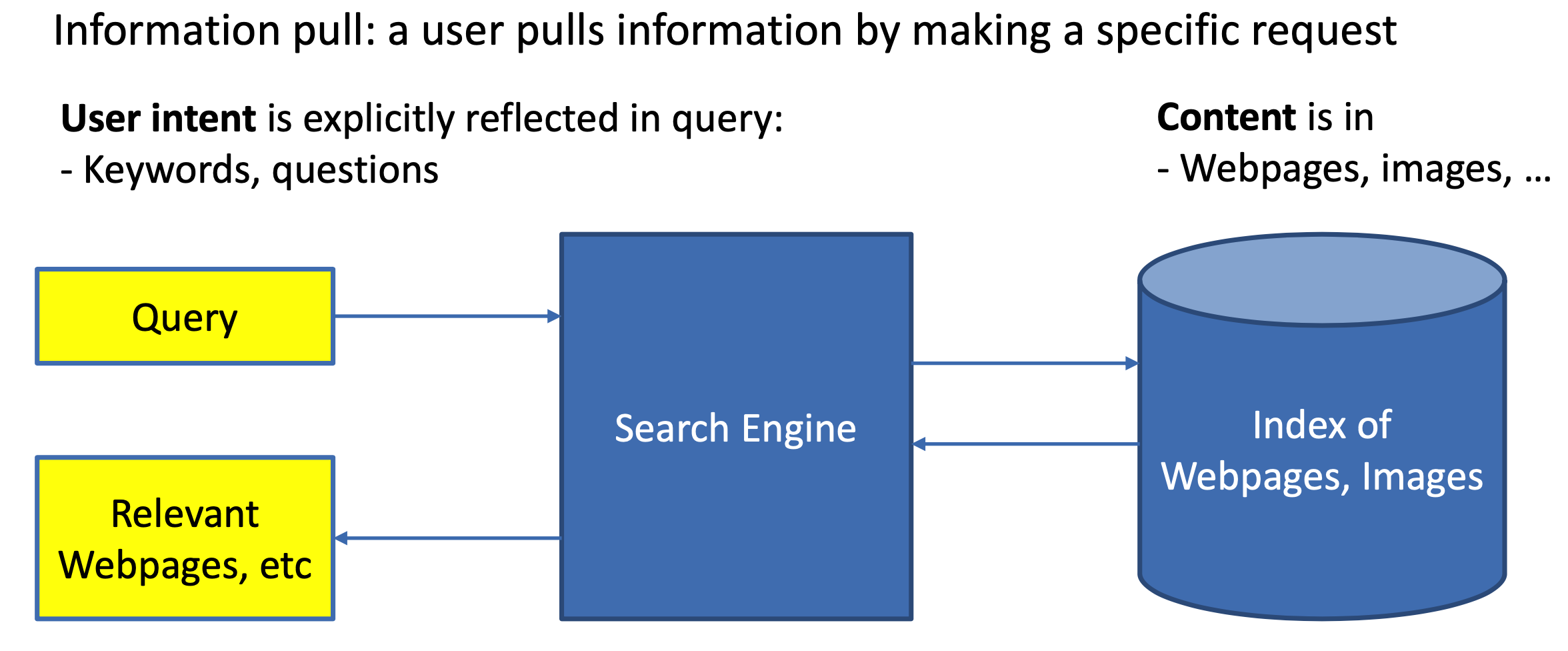
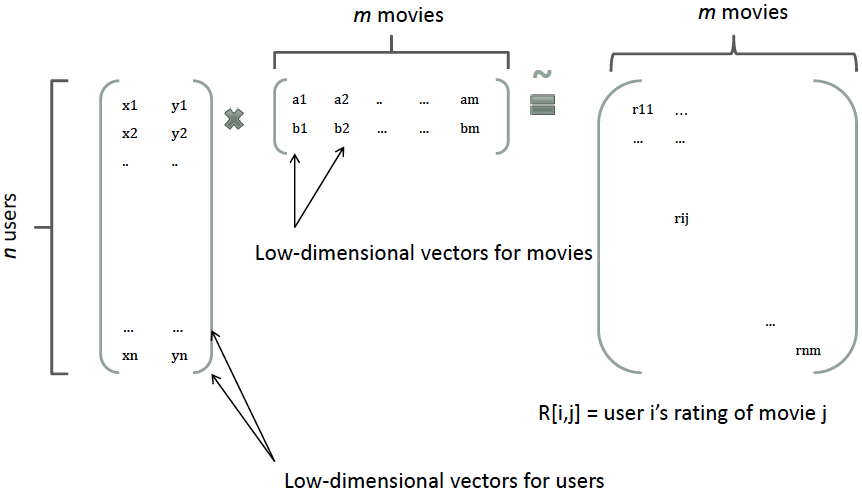
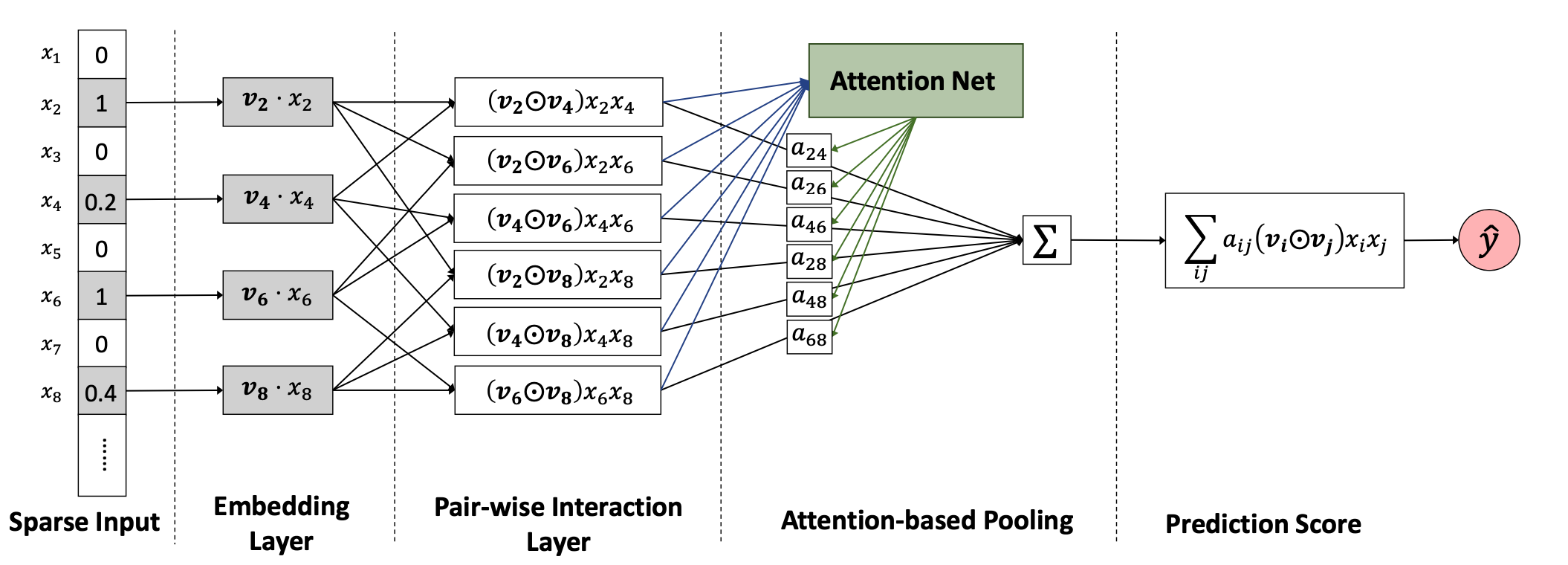
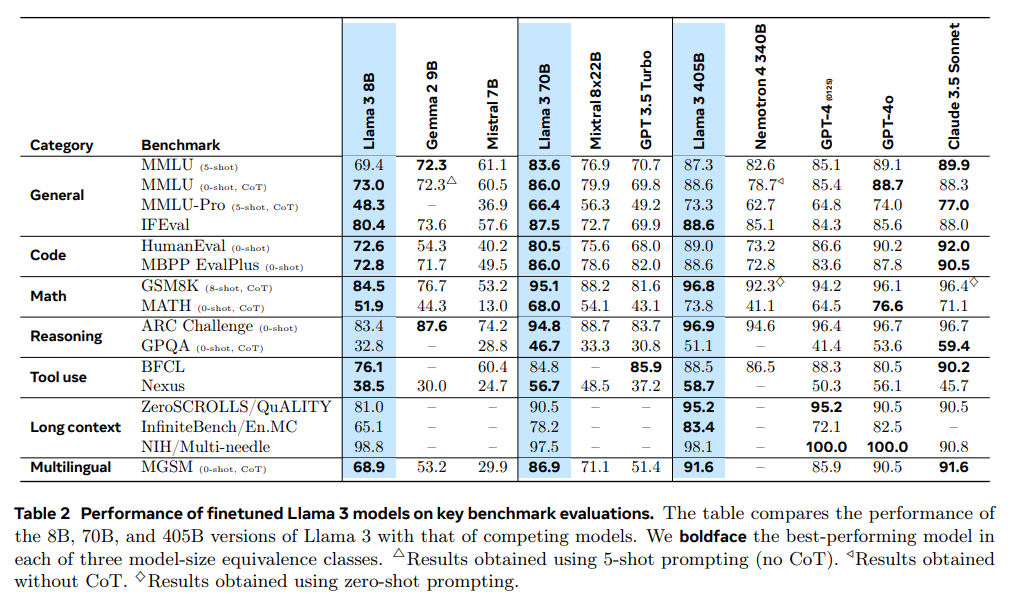
Search&Rec
2026-01-11

在电商搜索中,query推荐有很多种产品形态,不同的产品形态也扮演着不同的角色,常见的有query suggestion(SUG)、猜你想搜(搜索发现、大家都在搜)、细选(锦囊)、搜索底纹、搜索PUSH、搜索“风向标”(点击回退query推荐)等。以淘宝当前版本的产品形态为例,有: 上述每个方向都值得单独介绍,而本文则先整体从query推荐角度,放在一起介绍,方便横向对比各个场景的目标和方法上的异同之处。而以经典的分类方式展开,可以将query 推荐策略放在用户搜索前、搜索中、浏览中、搜索后(本章不涉及讨论)等各个状态阶段来进行比较: 目标 以上引出了搜索query推荐的两大目标: 搜索增长,目标提升提升渗透率,将用户引导到成交效率更高的搜索场景,提升搜索活跃度,常见的产品形态有:底纹、qu...