
简介 生成树(spanning tree) 在图论中,无向图 G=(V,E) 的生成树(spanning tree)是具有G的全部顶点,但边数最少的联通子图。假设G中一共有n个顶点,一颗生成树满足下列条件: (1)n个顶点; (2)n1条边; (3)n个顶点联通; (4)一个图的生成树可能有多个。最小生成树(minimum spanning tree, MST)/最小生成森林:联通加权无向图中边缘权重加和最小的生成树。给定无向图 G=(V,E) , (u,v) 代表顶点 u 与顶点 v 的边, w(u,v) 代表此边的权重,若存在生成树T使得: [公式] 最小,则 T 为 G 的最小生成树。对于非连通无向图来说,它的每一连通分量同样有最小生成树,它们的并被称为最小生成森林。最小生成树除了继承...
Algorithm
2026-01-11
给一个无向图,判断其是否为一棵树。如果是树的话,所有的节点必须是连接的,也就是说必须是连通图,而且不能有环,所以就变成了验证是否是连通图和是否含有环。 [代码]
Algorithm
2026-01-11
题目 中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。 例如, [2,3,4] 的中位数是 3 [2,3] 的中位数是 (2 + 3) / 2 = 2.5 设计一个支持以下两种操作的数据结构: void addNum(int num) 从数据流中添加一个整数到数据结构中。 double findMedian() 返回目前所有元素的中位数。 示例: addNum(1) addNum(2) findMedian() 1.5 addNum(3) findMedian() 2 题解 维护两个堆:大顶堆和小顶堆。并且需满足如下条件: 小顶堆的所有元素都大于等于大顶堆的所有元素。 大顶堆中的元素数量大于等于小顶堆中的元素数量。 大顶堆对应排序后的列表的左半部分;小顶堆对应排序...
Algorithm
2026-01-11
[代码] 自己实现小顶堆 [代码] 变态的需求来了:给出N长的序列,求出BtmK小的元素,即使用大顶堆。 概括一种最简单的: 将push(e)改为push(e)、pop(e)改为pop(e)。 也就是说,在存入堆、从堆中取出的时候,都用相反数,而其他逻辑与TopK完全相同,看代码: [代码] 自己实现大顶堆 [代码]
二叉树结构 [代码] 递归 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度:O(h),h为树的高度。最坏情况下需要空间O(n),平均情况为O(logn) 递归1: 二叉树遍历最易理解和实现版本 [代码] 递归2: 通用模板 可以适应不同的题目,添加参数、增加返回条件、修改进入递归条件、自定义返回值 [代码] 迭代 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:O(h),h为树的高度。取决于树的结构,最坏情况存储整棵树,即O(n) 迭代1: 前序遍历最常用模板(后序同样可以用) [代码] 迭代2: 前、中、后序遍历通用模板(只需一个栈的空间) [代码] 迭代3:标记法迭代(需要双倍的空间来存储访问状态) 前、中、后、层序通用模板,只需改...
3D Model
2026-01-11

Temporal action detection可以分为两种setting, 一是offline的,在检测时视频是完整可得的,也就是可以利用完整的视频检测动作发生的时间区间(开始时间+结束时间)以及动作的类别; 二是 online的,即处理的是一个视频流,需要在线的检测(or 预测未来)发生的动作类别,但无法知道检测时间点之后的内容。online的问题设定更符合surveillance的需求,需要做实时的检测或者预警;offline的设定更符合视频搜索的需求,比如youtube可能用到的 highlight detection / preview generation。 问题演化 Early action detection Online action detection Online a...
背包问题

简介 这篇文章的思路就是之前的工作都是在利用历史信息和当前时刻的信息,而这篇文章就是要预测未来的信息来结合历史信息做分类。整体框架采用的lstm。 方法 传统的RNN或者LSTM并不能接收未来的信息,所以作者设计了一个TRN Cell为一个循环单元,TRN Cell 的算法流程如下: 右侧的可以横过来看,输入是大lstm中的隐状态h(文中把大的lstm称作Encoder),以h为输入再经过小的lstm,将输出连接起来构成future信息。 再解释一下就是,endcoder中得到了时间t的信息,那以t的信息为输入,再经过序列lstm,每个输出就可以看作是对未来 t+1...t+l_d 的预测,这些预测再经过一个FC层和 t 时刻的结合起来,作用于encoder的下一时序。 从Loss的角度来说...
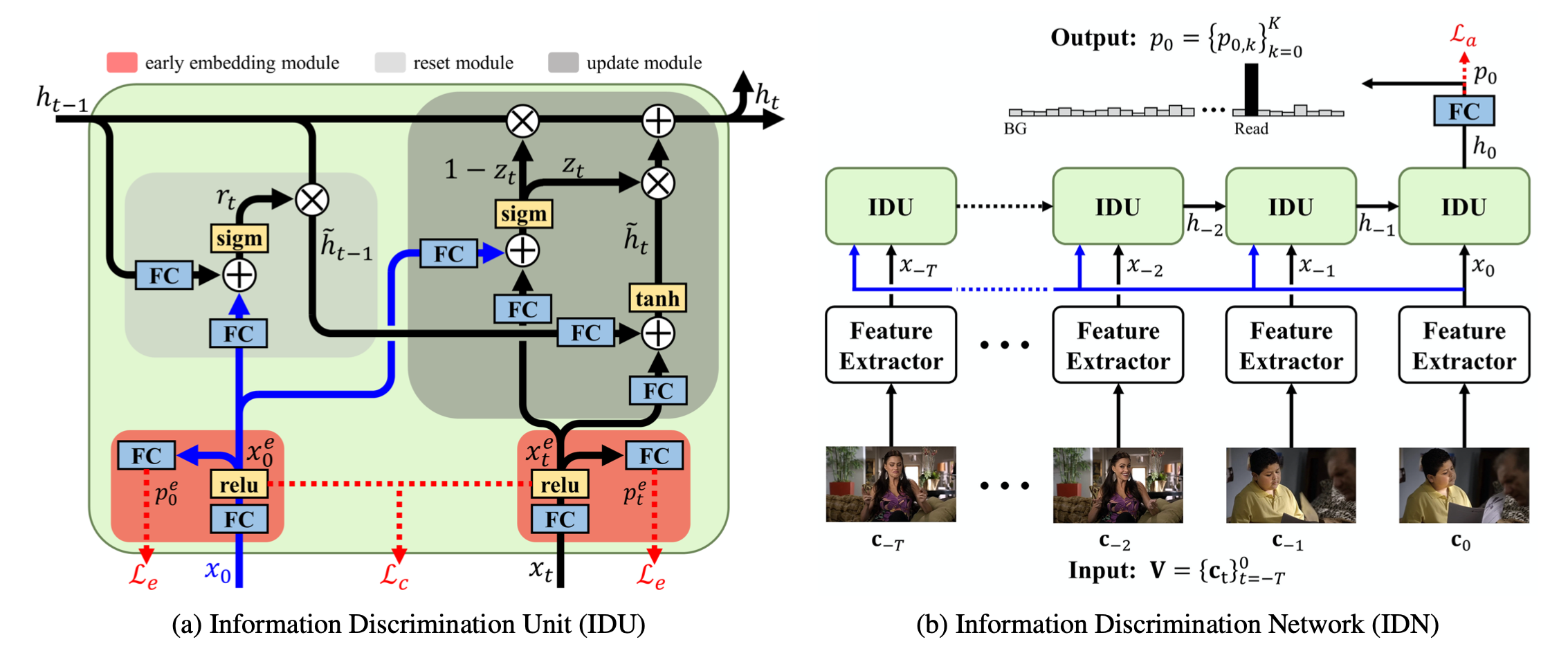
简介 这篇文章主要的动机是,之前的RNN,LSTM,GRU这样的循环结构中,循环单元累计历史输入,但忽视了其与当前动作的联系,所以不能得到一个有效的判别性的表示。 Specifically, the recurrent unit accumulates the input information without explicitly considering its relevance to the current action, and thus the learned representation would be less discriminative. 所以, 这篇文章就是在探索是否可以学习一个判别性较强的表示区分相关和不相关的信息以检测当前要动作。 how RNNs can lear...
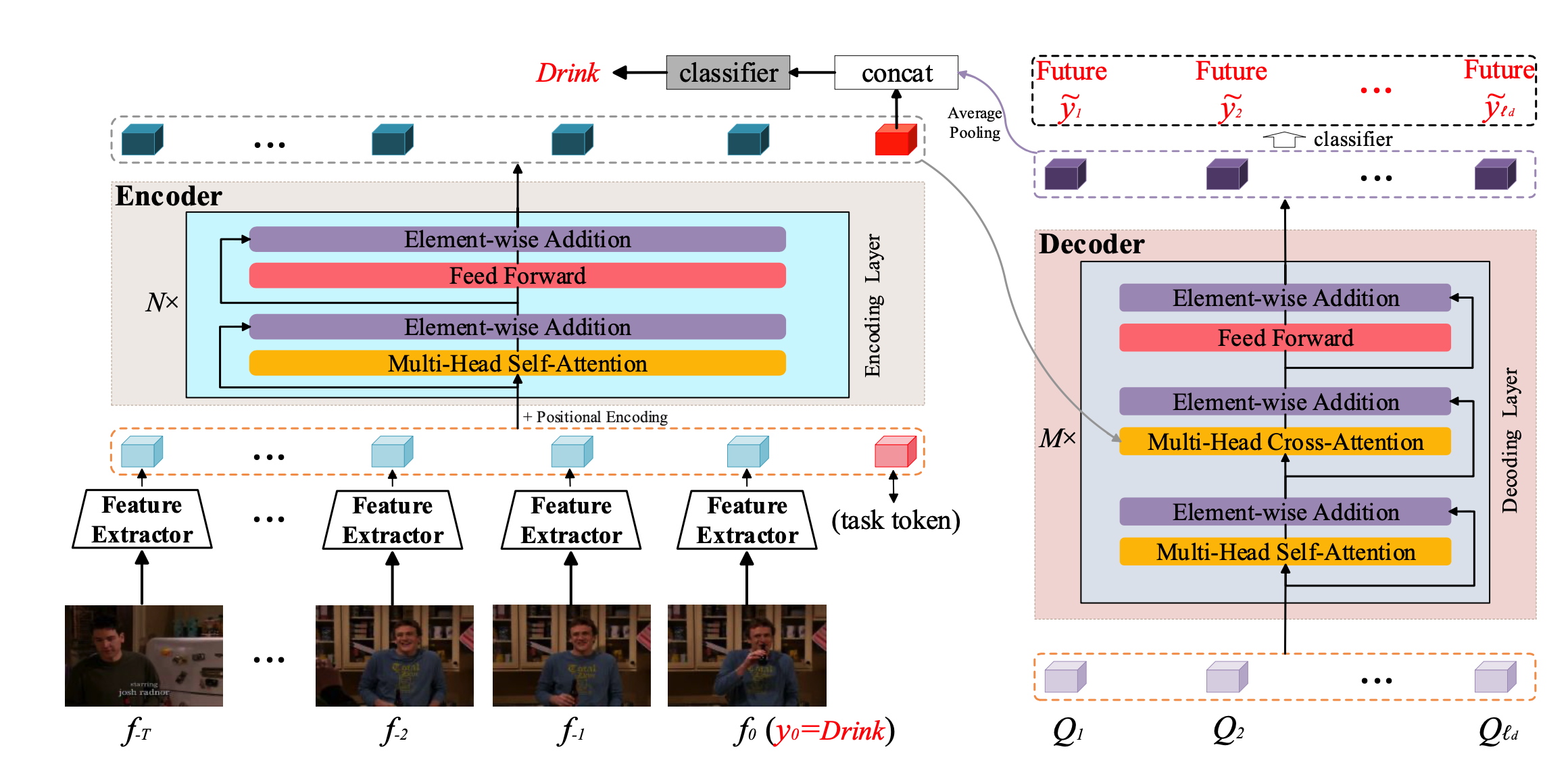
简介 之前的很多方法都是用RNN的结构去构建时序上的依赖关系,但是RNN的结构的缺点是不能并行操作,且存在梯度消失的现象。所以本文就是将之前的RNN的结构改为Transfomer的形式。延续了之前TRN的整个网络的框架,也是结合了对未来帧的预测与历史帧的表示相结合来对当前的动作进行预测。 方法 整个网络框架如上图所示, Encoder就是利用transfomer对longrange的历史和目前帧进行特征表示,其中要说明的一个点就是,这里的特征空间包含T个历史特征,当前窗口的特征以及一个task token,这个task token的作用可以从下图看出来 这幅图对比的是输入进classifier的特征与网络输入的特征的相似性,可以看出w/o task token 对应的是当前t=0时刻的特征,...
3D Model
2026-01-11
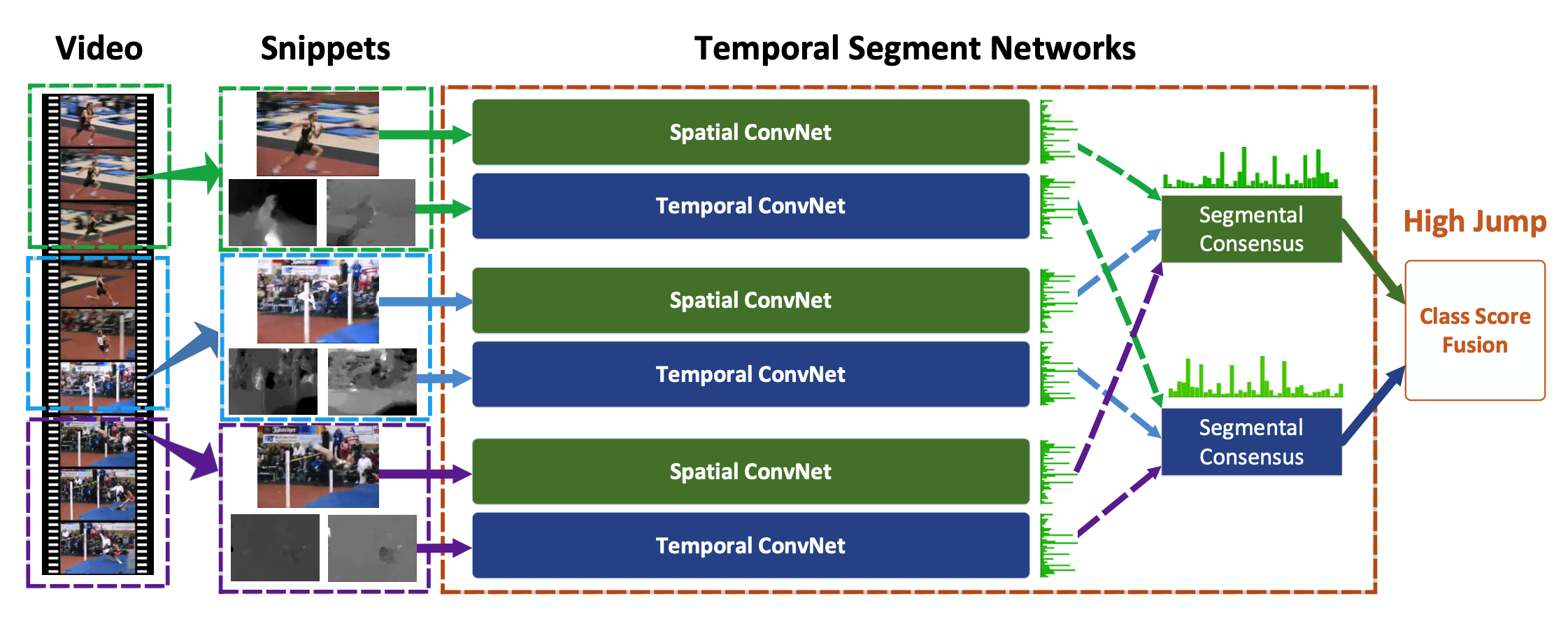
简介 这篇ECCV2016的文章主要提出TSN(temporal segment network)结构用来做视频的动作识别。TSN可以看做是双流(two stream)系列的改进,在此基础上,文章要解决两个问题:1、是longrange视频的行为判断问题(有些视频的动作时间较长)。2、是解决数据少的问题,数据量少会使得一些深层的网络难以应用到视频数据中,因为过拟合会比较严重。 针对第一个问题,首先,为什么目前的双流结构网络难以学习到视频的长时间信息?因为其针对的主要是单帧图像或者短时间内的一堆帧图像数据,但这对于时间跨度较长的视频动作检测而言是不够的。因此采用更加密集的图像帧采样方式来获取视频的长时间信息是比较常用的方法,但是这样做会增加不少时间成本,同时作者发现视频的连续帧之间存在冗余,因...
3D Model
2026-01-11
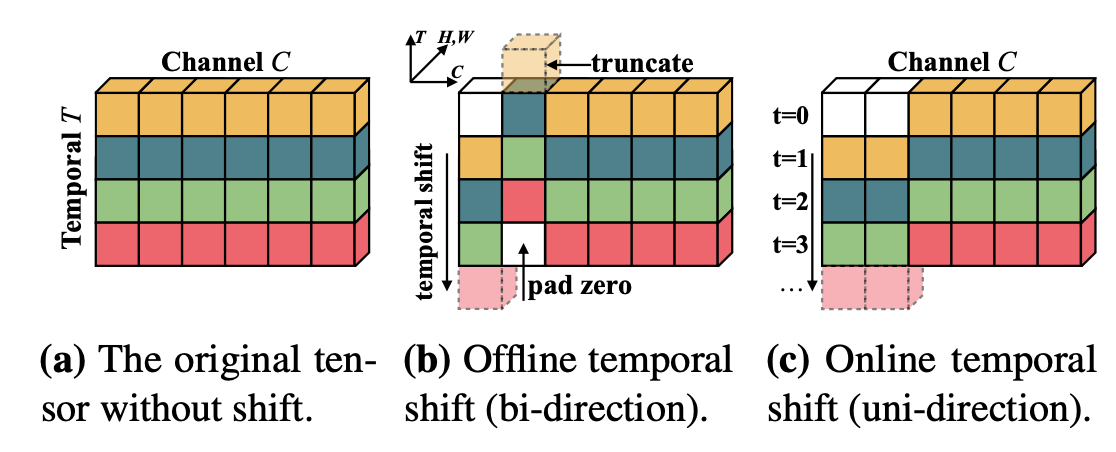
Related Work: 大概过一下之前的几个重要工作(也是本文性能对比的主要几个stateoftheart): 1. TSN:视频动作/行为识别的基本框架,将视频帧下采样(分成K个Segment,各取一帧)后接2D CNN对各帧进行处理+fusion 1. TRN:对视频下采样出来的 frames 的deep feature,使用 MLP 来融合,建立帧间temporal context 联系。最后将多级(不同采样率)出来的结果进行再一步融合,更好表征shortterm 和 longterm 关系。 1. ECO系列: 1. NL I3D+GCN:使用 nonlocal I3D来捕获longrange时空特征,使用 spacetime region graphs 来获取物体区域间的关联及...