
简介 生成对抗网络 ( Generative Adversarial Network, GAN ) 是由 Goodfellow 于 2014 年提出的一种对抗网络。这个网络框架包含两个部分,一个生成模型 (generative model) 和一个判别模型 (discriminative model)。其中,生成模型可以理解为一个伪造者,试图通过构造假的数据骗过判别模型的甄别;判别模型可以理解为一个警察,尽可能甄别数据是来自于真实样本还是伪造者构造的假数据。两个模型都通过不断的学习提高自己的能力,即生成模型希望生成更真的假数据骗过判别模型,而判别模型希望能学习如何更准确的识别生成模型的假数据。 网络框架 GAN 由两部分构成,一个 生成器 ( Generator ) 和一个 判别器 ( Discriminator )。对于生成器,我们需要学习关于数据 \(x\) 的一个分布 \(p_g\) ,首先定义一个输入数据的先验分布 \(p_z(z)\) ,其次定义一个映射 \(G \left(\boldsymbol{z}; \theta_g\right): \boldsymbol{z}...
Large Model
2026-01-15

🔖 https://www.deepseek.com/ DeepSeek LLM 代码地址: https://github.com/deepseek-ai/DeepSeek-LLM 背景 量化巨头幻方探索AGI(通用人工智能)新组织“深度求索”在成立半年后,发布的第一代大模型,免费商用,完全开源。作为一家隐形的AI巨头,幻方拥有1万枚英伟达A100芯片,有手撸的HAI-LLM训练框架HAI-LLM:高效且轻量的大模型训练工具。 概述 DeepSeek LLMs,这是一系列在2万亿标记的英语和中文大型数据集上从头开始训练的开源模型 在本文中,深入解释了超参数选择、Scaling Laws以及做过的各种微调尝试。校准了先前工作中的Scaling Laws,并提出了新的最优模型/数据扩展-缩放分配策略。此外,还提出了一种方法,使用给定的计算预算来预测近似的batch-size和learning-rate。进一步得出结论,Scaling Laws与数据质量有关,这可能是不同工作中不同扩展行为的原因。在Scaling Laws的指导下,使用最佳超参数进行预训练,并进行全面评估。...
Large Model
2026-01-15

简介 24年12月,研究团队开发了 DeepSeek-V3,这是一个基于 MoE 架构的大模型,总参数量达到 671B,其中每个 token 会激活 37B 个参数。 基于提升性能和降低成本的双重目标,在架构设计方面,DeepSeek-V3 采用了 MLA 来确保推理效率,并使用 DeepSeekMoE 来实现经济高效的训练。这两种架构在 DeepSeek-V2 中已经得到验证,证实了它们能够在保持模型性能的同时实现高效的训练和推理。 除了延续这些基础架构外,研究团队还引入了两项创新策略来进一步提升模型性能。 首先,DeepSeek-V3 首创了 无辅助损失的负载均衡 策略(auxiliary-loss-free strategy for load balancing),有效降低了负载均衡对模型性能的负面影响。另外,DeepSeek-V3 采用了 多 token 预测训练目标, 这种方法在评估基准测试中展现出了显著的性能提升。 为了提高训练效率,该研究采用了 FP8 混合精度训练技术...
Self-Supervised
2026-01-11
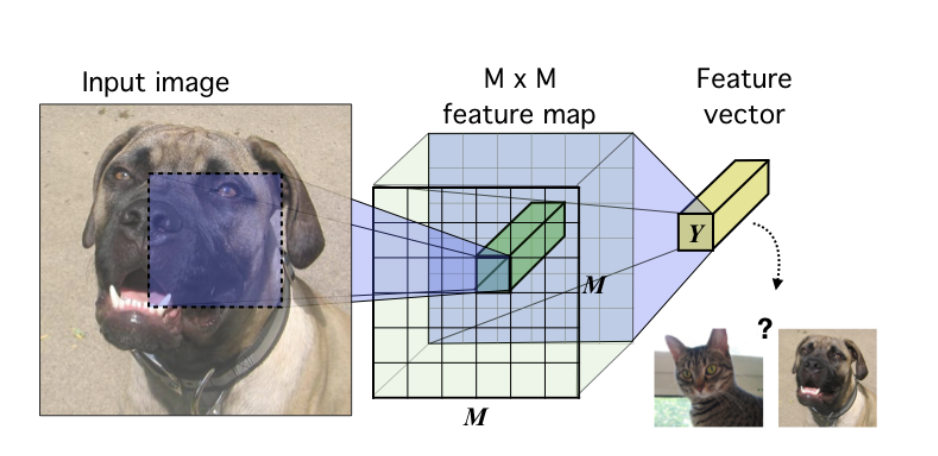
相关内容 自监督学习(Selfsupervised):属于无监督学习,其核心是自动为数据打标签(伪标签或其他角度的可信标签,包括图像的旋转、分块等等),通过让网络按照既定的规则,对数据打出正确的标签来更好地进行特征表示,从而应用于各种下游任务。 互信息(Mutual Information):表示两个变量 X 和 Y 之间的关系,定义为: 噪声对抗估计(Noise Contrastive Estimation, NCE):在NLP任务中一种降低计算复杂度的方法,将语言模型估计问题简化为一个二分类问题。 Introduction 无监督学习一个重要的问题就是学习有用的 representation,本文的目的就是训练一个 representation learning 函数(即编码器encod...
Large Model
2026-01-11

梯度检查点(Gradient Checkpointing) 大模型的参数量巨大,即使将batch_size设置为1并使用梯度累积的方式更新,也仍然会OOM。原因是通常在计算梯度时,我们需要将所有前向传播时的激活值保存下来,这消耗大量显存。 还有另外一种延迟计算的思路,丢掉前向传播时的激活值,在计算梯度时需要哪部分的激活值就重新计算哪部分的激活值,这样做倒是解决了显存不足的问题,但加大了计算量同时也拖慢了训练。 梯度检查点(Gradient Checkpointing)在上述两种方式之间取了一个平衡,这种方法采用了一种策略选择了计算图上的一部分激活值保存下来,其余部分丢弃,这样被丢弃的那一部分激活值需要在计算梯度时重新计算。 下面这个动图展示了一种简单策略:前向传播过程中计算节点的激活值并保存...
Large Model
2026-01-11
简介 基于lmmsengine中的训练时对数据packing操作以及use_rmpad消除了所有padding计算的逻辑 Packing 总体逻辑基于packing_length 将不同的数据填充到一个sequence中,具体来说 在Datsset中, 如下代码所示,将不同的数据append到buffer列表中 [代码] 在 Collator 组合成batch的形式传入到模型的输入, 这里还是将数据padding [代码] rmpad 项目中,是以 monkey patch的形式(也就是打热补丁) 替换rmpad操作的,如下代码所示,主要就是替换模型中的forward操作 [代码] Qwen3VLModel.forward 显式调用了 _unpad_input。它计算了非 padding 元...
Large Model
2026-01-11

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈:中间矩阵占用大量显存 I/O开销:频繁的全局内存访问降低效率 扩展性限制:难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 SelfAtention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 [Math] ): [公式] 其中: Q, K, V, O 都是形...
Large Model
2026-01-11

模型概述 KimiVL 是一个高效的开源混合专家视觉语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(KimiVLA3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等. 模型架构 KimiVL 的架构由三个主要部分组成: MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters 视觉模型 400M nativeresolution MoonViT vision encoder. MLP Projector MoonViT: 原生...
Large Model
2026-01-11

背景:大模型 vs. GPU Memory 大模型最大的特点是模型参数多,训练时需要很大的GPU显存。举个例子,帮助大家的理解:对于一个常见的7B规模参数的大模型(如LLaMA-2 7B),基于16-bit混合精度训练时,在仅考虑模型参数、梯度、优化器情况下,显存占用就有112GB,显然目前A100、H100这样主流的显卡单张是放不下的,更别提国内中小厂喜欢用的A6000/5000、甚至消费级显卡。 上面的例子中,参数占GPU 显存近 14GB(每个参数2字节)。再考虑到训练时 梯度的存储占14GB(每个参数对应一个梯度,也是2字节)、优化器Optimizer假设是用目前主流的AdamW则是8...
Large Model
2026-01-11

Chameleon:生成理解统一模型的开山之作 🔖 https://arxiv.org/pdf/2405.09818 Chameleon 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。完整记录了为实现 mixedmodal 模型的架构设计,稳定训练方法,对齐的配方。并在一系列全面的任务上进行评估:有纯文本任务,也有图像文本任务 (视觉问答、图像字幕),也有图像生成任务,还有混合模态的生产任务。 如下图所示,Chameleon 将所有模态数据 (图像、文本和代码) 都表示为离散 token,并使用统一的 Transformer 架构。训练数据是交错混合模态数据 ∼10T token,以端到端的方式从头开始训练。文本 token 用绿色表示,图像...
Large Model
2026-01-11
🔖 https://docs.dify.ai/zhhans/gettingstarted/installselfhosted Docker 按照官方文档说明配置即可 https://docs.dify.ai/zhhans/gettingstarted/installselfhosted/dockercompose 源码安装 参考官方步骤, 需要补充一些内容 https://docs.dify.ai/zhhans/gettingstarted/installselfhosted/localsourcecode 在启动API 服务之前需要安装PostgreSQL数据库和Redis Postgres安装配置(非Root) 下载二进制编译好的安装包, 下载地址在这里 解压并创建data目录 初始化d...
Large Model
2026-01-11

概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 D = \{(x_i, y^_i)\}_{i=1}^n ,其中包含问题 x_i 和对应的真实答案 y^_i ,目标是训练一个策略模型 [Math] 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 z = (z_1, z_2, ..., z_m) 来连接问题 x 和答案 y ,每个 z_i 是解决问题的重要中间步骤。 当解决问题 x 时,思维 [Math] 被自回归采样,最终答案 [Math] 。 强化学习目标 基于真实答案 y^ ,分配一个值 [Math] , Ki...