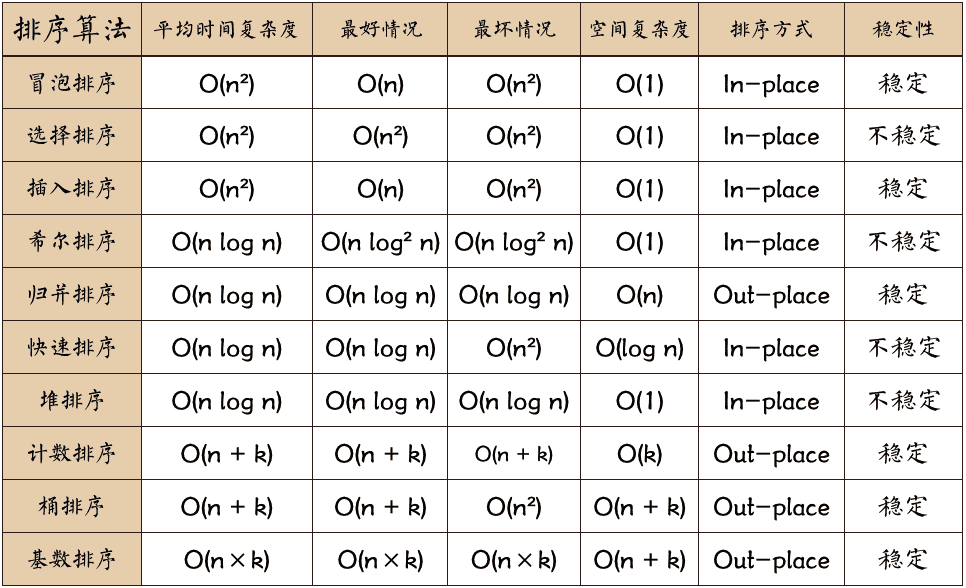
排序算法是《数据结构与算法》中最基本的算法之一。 排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。用一张图概括: 冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复地遍历待排序的列表,比较相邻的元素并交换它们的位置来实现排序。该算法的名称来源于较小的元素会像"气泡"一样逐渐"浮"到列表的顶端。 算法步骤 比较相邻元素 :从列表的第一个元素开始,比较相邻的两个元素。 交换位置 :如果前一个元素比后一个元素大,则交换它们的位置。 重复遍历 :对列表中的每一对相邻元素重复上述步骤,直到列表的末尾。这样,最大的元素会被"冒泡"到列表的最后。 缩小范围 :忽略已经排序好的最后一个元素,重复上述步骤,直到整个列表排序完成。 假设有一个待排序的列表 [5, 3, 8, 4, 6] ,冒泡排序的过程如下: 第一轮遍历 : 比较 5 和 3,交换位置,列表变为 [3,...
Algorithm
2026-02-25
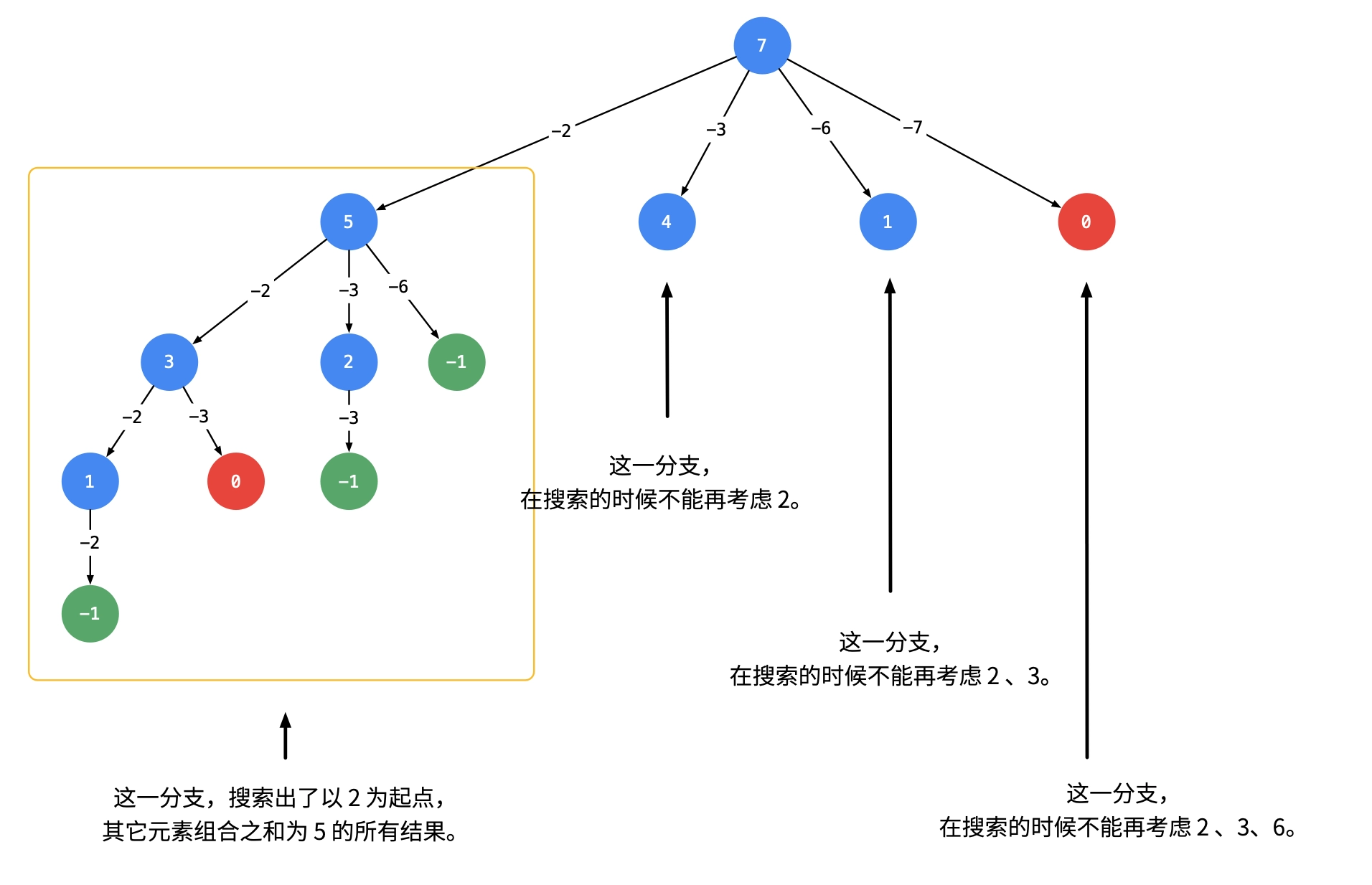
DFS 39&40. 组合总和 题目 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。 对于给定的输入,保证和为 target 的不同组合数少于 150 个。 示例 1: 输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。 示例 2: 输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]] 示例 3: 输入: candidates = [2], target = 1
输出: [] 提示: 1 <=...
二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
Algorithm
2026-02-25
实现 方式一:使用 heapq 标准库 这是 Python 最快、最节省内存的方式,因为 heapq 底层是用 C 语言实现的。 小顶堆 (Min Heap) Python 的 heapq 默认就是小顶堆。 import heapq
# 初始化
min_heap = []
# 添加元素 O(log N)
heapq.heappush(min_heap, 5)
heapq.heappush(min_heap, 2)
heapq.heappush(min_heap, 8)
# 查看堆顶 O(1)
print(min_heap[0]) # 输出: 2
# 弹出堆顶 O(log N)
pop_val = heapq.heappop(min_heap)
print(pop_val) # 输出: 2
print(min_heap) # 输出: [5, 8] (注意:堆内部不一定有序,但堆顶一定是最小的)
# 将已有的列表转化为堆 O(N)
nums = [5, 7, 1, 3]
heapq.heapify(nums)
print(nums) #...
堆和优先队列的关系 这是一个非常经典且核心的计算机科学概念问题。一言以蔽之: 优先队列(Priority Queue)是逻辑接口(ADT),而堆(Heap)是实现这个接口最高效的物理数据结构。 它们的关系可以类比为 “接口(Interface)” 与 “实现类(Implementation)” 的关系,或者 “汽车(功能)”与 “发动机(核心组件)” 的关系。 优先队列 (Priority Queue) —— 逻辑层 (ADT) 定义 :它是一种 抽象数据类型 (Abstract Data Type, ADT) 。它定义了数据的 行为 ,而不是数据的存储方式。 规则 :普通的队列是“先进先出”(FIFO),而优先队列是 “优先级最高的先出” 。 核心操作 : insert(item, priority) : 插入一个带优先级的元素。 deleteMax() 或 deleteMin() : 取出并删除优先级最高(或最低)的元素。 peek() : 查看优先级最高的元素。 堆 (Heap) —— 物理层 (Data Structure) 定义 :它是一种具体的 数据结构 。通常指 二叉堆...
引入 在具体讲何为「背包 dp」前,先来看如下的例题: 题意概要:有 \( 𝑛\) 个物品和一个容量为 \( 𝑊\) 的背包,每个物品有重量 \(𝑤_𝑖\) 和价值 \(𝑣_𝑖\) 两种属性,要求选若干物品放入背包使背包中物品的总价值最大且背包中物品的总重量不超过背包的容量. 在上述例题中,由于每个物体只有两种可能的状态(取与不取),对应二进制中的 0 和 1,这类问题便被称为「0-1 背包问题」. 0-1背包 解释 例题中已知条件有第 \(𝑖\) 个物品的重量 \(𝑤_𝑖\) ,价值 \(𝑣_𝑖\) ,以及背包的总容量 \(𝑊\) . 设 DP 状态 \(𝑓_{𝑖,𝑗} \) 为在只能放前 \(𝑖\) 个物品的情况下,容量为 \(𝑗\) 的背包所能达到的最大总价值. 考虑转移.假设当前已经处理好了前 \(𝑖 −1 \) 个物品的所有状态,那么对于第 \(𝑖\) 个物品,当其不放入背包时,背包的剩余容量不变,背包中物品的总价值也不变,故这种情况的最大价值为 \(𝑓_{𝑖−1,𝑗}\) ;当其放入背包时,背包的剩余容量会减小 \(𝑤_𝑖\) ,背包中物品的总价值会增大 \(𝑣_𝑖\)...

简介 生成树(spanning tree) 在图论中,无向图 \(G=(V,E)\) 的生成树(spanning tree)是具有 \(G\) 的全部顶点,但边数最少的联通子图。假设 \(G\) 中一共有 \(n\) 个顶点,一颗生成树满足下列条件 \(n\) 个顶点; \(n-1\) 条边; \(n\) 个顶点联通; 一个图的生成树可能有多个。 最小生成树(minimum spanning tree, MST)/最小生成森林 :联通加权无向图中边缘权重加和最小的生成树。给定无向图 \(G=(V,E)\) , \((u,v)\) 代表顶点 \(u\) 与顶点 \(v\) 的边, \(w(u,v)\) 代表此边的权重,若存在生成树T使得: \[w(T) = \sum_{(u,v)\in T}w(w,v)\] 最小,则 \(T\) 为 \(G\) 的最小生成树。对于非连通无向图来说,它的每一 连通分量 同样有最小生成树,它们的并被称为 最小生成森林 。最小生成树除了继承生成树的性质之外,还存在下面两个特点: 当图的每一条边的权值都相同时,该图的所有生成树都是最小生成树;...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
Search&Rec
2026-01-11
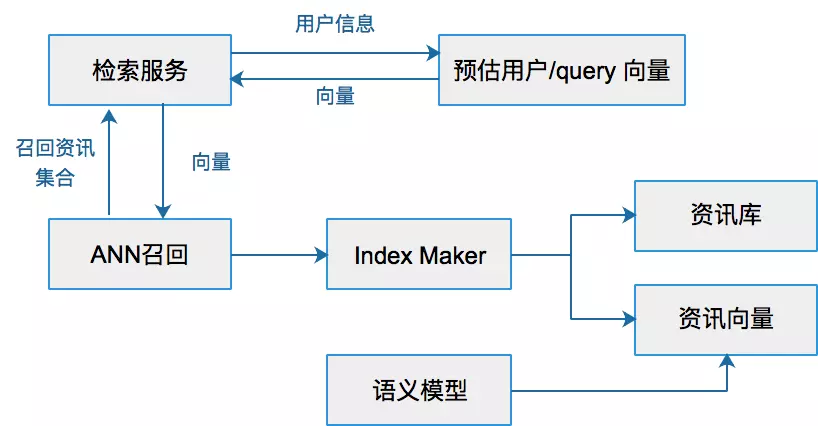
1. 概述 新闻推荐系统从海量新闻中推荐出你感兴趣的新闻,百度从海量的搜索结果中找到最优的结果,短视频推荐出你每天都停不下来的视频流,这些里面都包含ANN方法。当然,在现在的检索系统中,往往是多分支并行触发的效果,虽然DNN 大行其道,但是 ANN 一直不可或缺。 通用理解上,ANN(Approximate Nearest Neighbor)是在向量空间中搜索向量最近邻的优化问题。目前业界常用nmslib、Annoy算法作为实现。在实际的工程应用中,ANN是作为一种向量检索技术应用,用于解决长尾Query召回问题。将一个资讯的ANN 召回系统抽象出来大概是下面的样子。 Ann(approximate nearest neighbor)是指一系列用于解决最近邻查找问题的近似算法。最近邻查找问题...
Search&Rec
2026-01-11
1.倒排索引召回 1)召回模型有三种: 1.基于行为的召回:根据用户的购买行为推荐相关/相似的商品;(长期行为和实时行为) 2.基于用户偏好的召回:用户画像和多屏互通(移动端到PC端); 3.基于地域的召回; 4.基于搜索词的召回(倒排索引); 2)倒排索引 倒排是指由属性值来确定记录的位置。 倒排索引由单词词典和倒排文件组成, 单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。 倒排文件记录所有单词的倒排列表顺序。 好处是在找含有该词的文件时,不需要扫描所有文件,而只需要在单词词典中找到该词,然后找到该词对应的倒排列表即可。 Lucene倒排步骤: 1.取得关键词; 2.建立倒排索引;lucene将上面三列分别作为...
Search&Rec
2026-01-11

一句话总结 正排索引:一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。 倒排索引:Inverted index,指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。 倒排索引创建索引的流程 形成文档列表 首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表。 创建倒排索引列表 对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。保存包含这些词条的文档的编号信息。 搜索的过程 当用户输入任意的词条时,首先对用户输入的数据进行分词,得到用户要搜索的所有词条,然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。 然后根据这些编号去文档列表中找到文档 正排和倒排 正...