Large Model
2026-03-09
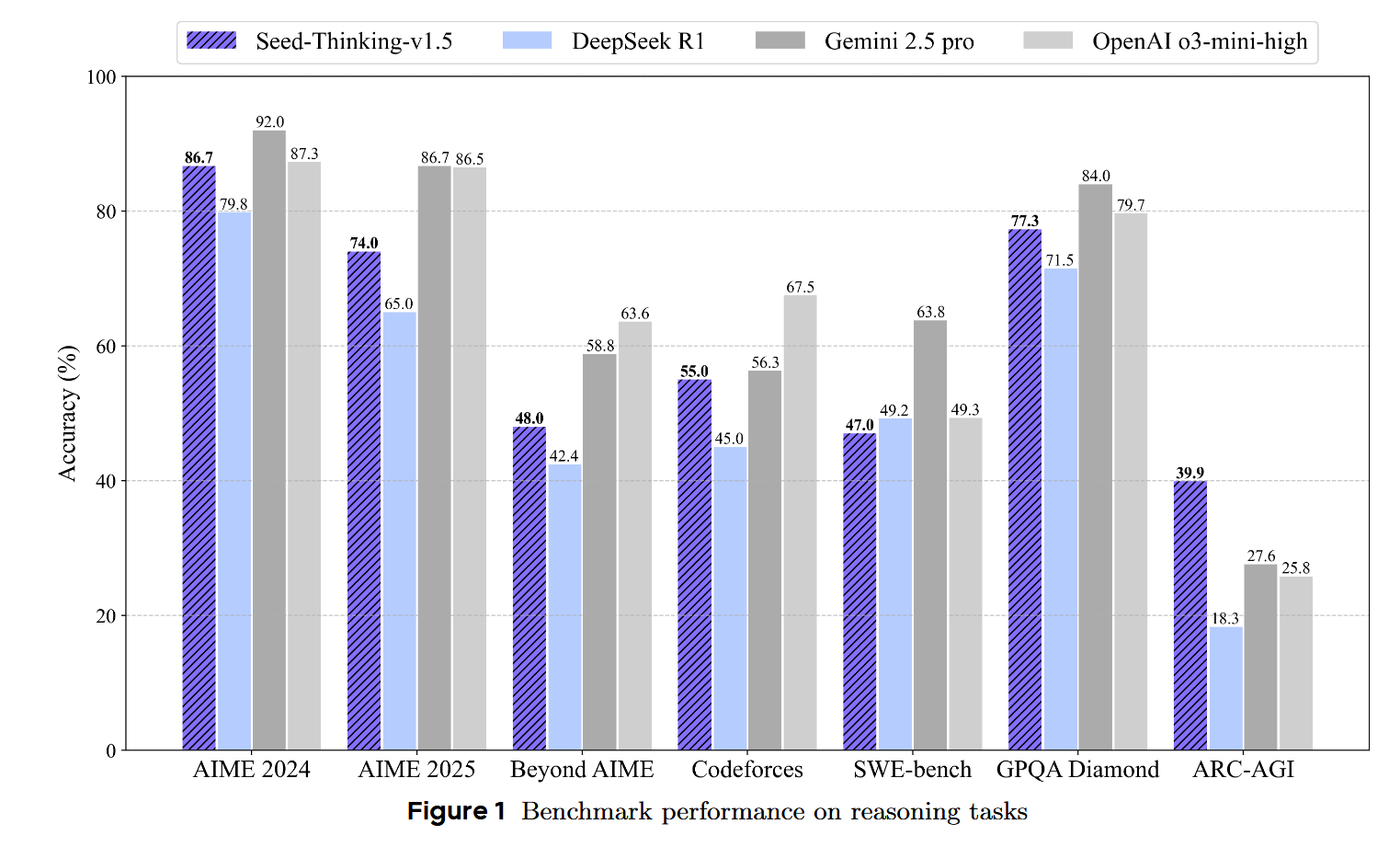
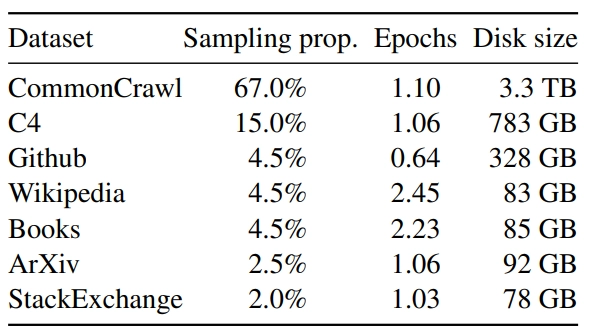
Seed-Thinking-v1.5 https://github.com/ByteDance-Seed/Seed-Thinking-v1.5 Seed-Thinking-v1.5 是 ByteDance Seed 团队开发的一个先进推理模型,采用 Mixture-of-Experts (MoE) 架构,具有 200B 总参数和 20B 激活参数。该模型的核心创新在于其"思考后回答"的机制,在数学、编程、科学推理等任务上取得了卓越的性能。相比DeepSeek R1 ,在很多数据指标上都取得了一定程度的进步。 数据 训练数据分为两大类: 可验证问题 (有明确答案)和 不可验证问题 (无明确答案)。模型的推理能力主要来自第一部分,并能泛化到第二部分。 可验证问题数据 可验证数据主要包含 STEM数据, 编程数据,以及逻辑推理数据 STEM 数据 数据组成:包含数十万道高质量竞赛级别问题, 涵盖数学、物理、化学,其中数学占比超过 80%; 数据清洗:初步删除问题陈述不完整、符号不一致或要求不明确的问题; 进一步过滤过于简单的数据以及有可能答案是错误的数据...