Computer Vision
2026-01-11
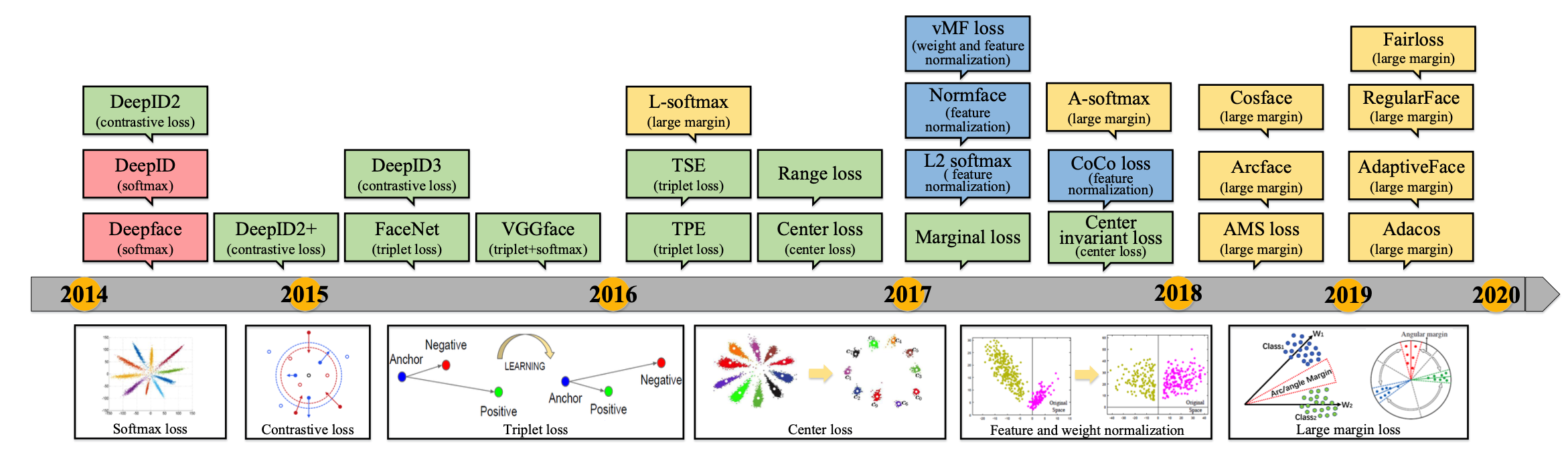
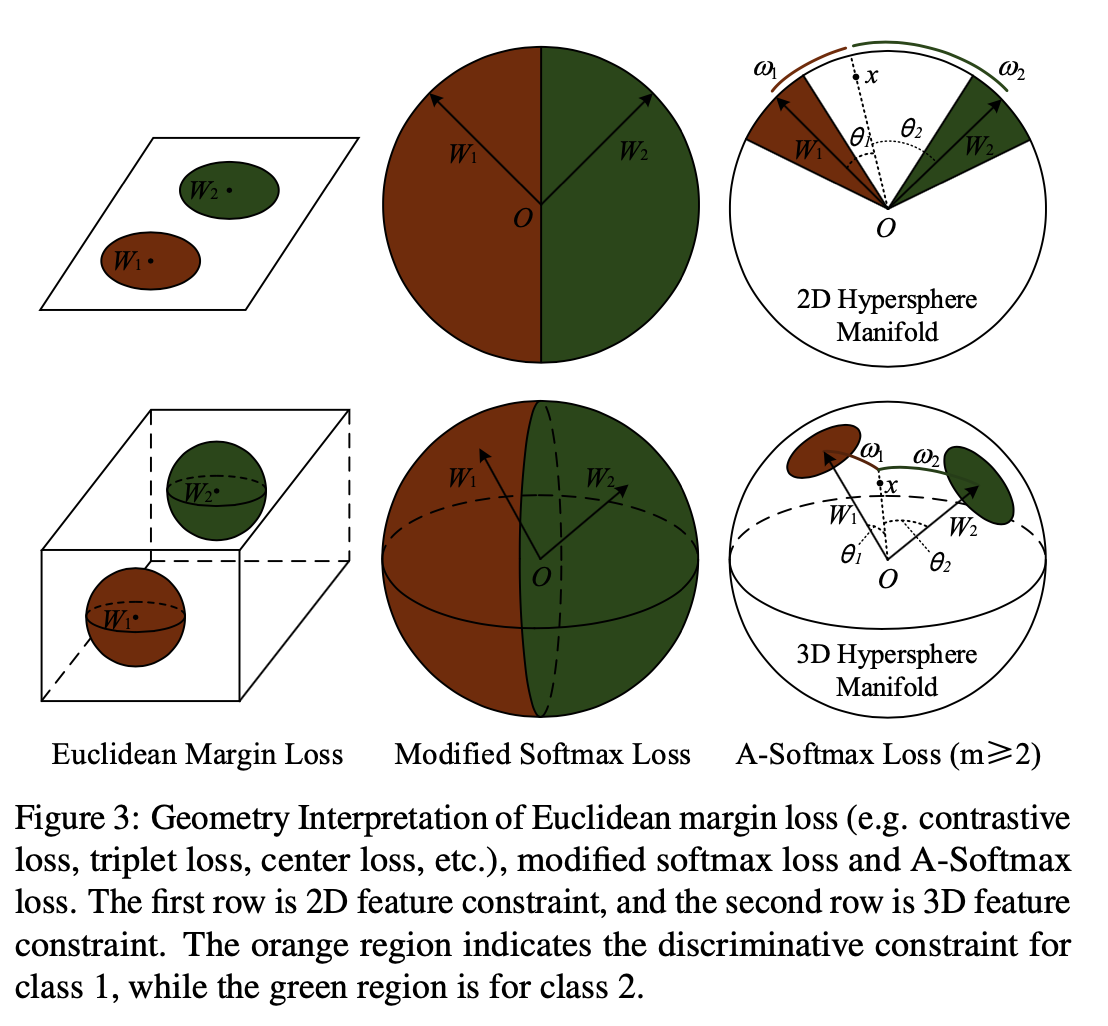
超多分类的Softmax 2014年CVPR两篇超多分类的人脸识别论文:DeepFace和DeepID DeepFace Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to humanlevel performance in face verification [C]// CVPR, 2014. 4.4M训练集,训练6层CNN + 4096特征映射 + 4030类Softmax,综合如3D Aligement, model ensembel等技术,在LFW上达到97.35%。 DeepID Sun Y, Wang X, Tang X. Deep learning face representation fro...