
简介 这篇文章的思路就是之前的工作都是在利用历史信息和当前时刻的信息,而这篇文章就是要预测未来的信息来结合历史信息做分类。整体框架采用的lstm。 方法 传统的RNN或者LSTM并不能接收未来的信息,所以作者设计了一个TRN Cell为一个循环单元,TRN Cell 的算法流程如下: 右侧的可以横过来看,输入是大lstm中的隐状态h(文中把大的lstm称作Encoder),以h为输入再经过小的lstm,将输出连接起来构成future信息。 再解释一下就是,endcoder中得到了时间t的信息,那以t的信息为输入,再经过序列lstm,每个输出就可以看作是对未来 t+1...t+l_d 的预测,这些预测再经过一个FC层和 t 时刻的结合起来,作用于encoder的下一时序。 从Loss的角度来说...
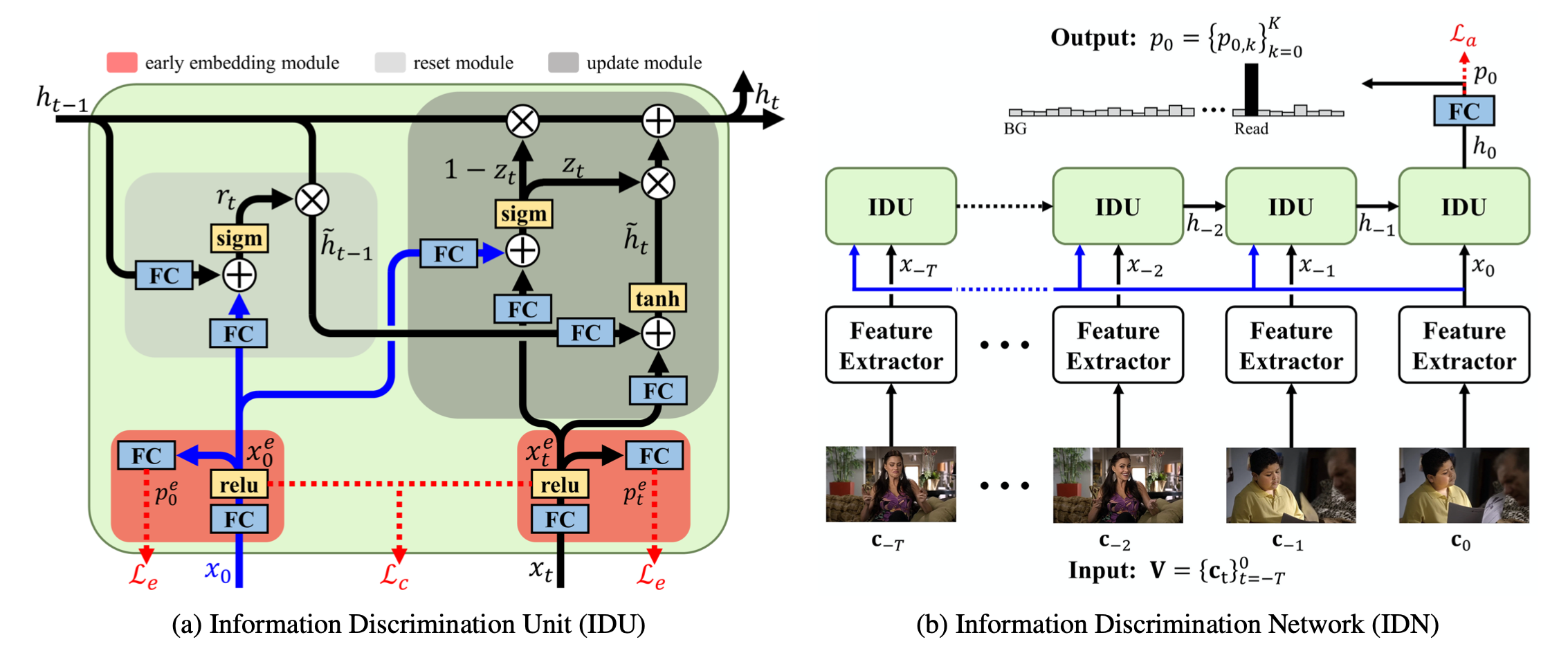
简介 这篇文章主要的动机是,之前的RNN,LSTM,GRU这样的循环结构中,循环单元累计历史输入,但忽视了其与当前动作的联系,所以不能得到一个有效的判别性的表示。 Specifically, the recurrent unit accumulates the input information without explicitly considering its relevance to the current action, and thus the learned representation would be less discriminative. 所以, 这篇文章就是在探索是否可以学习一个判别性较强的表示区分相关和不相关的信息以检测当前要动作。 how RNNs can lear...
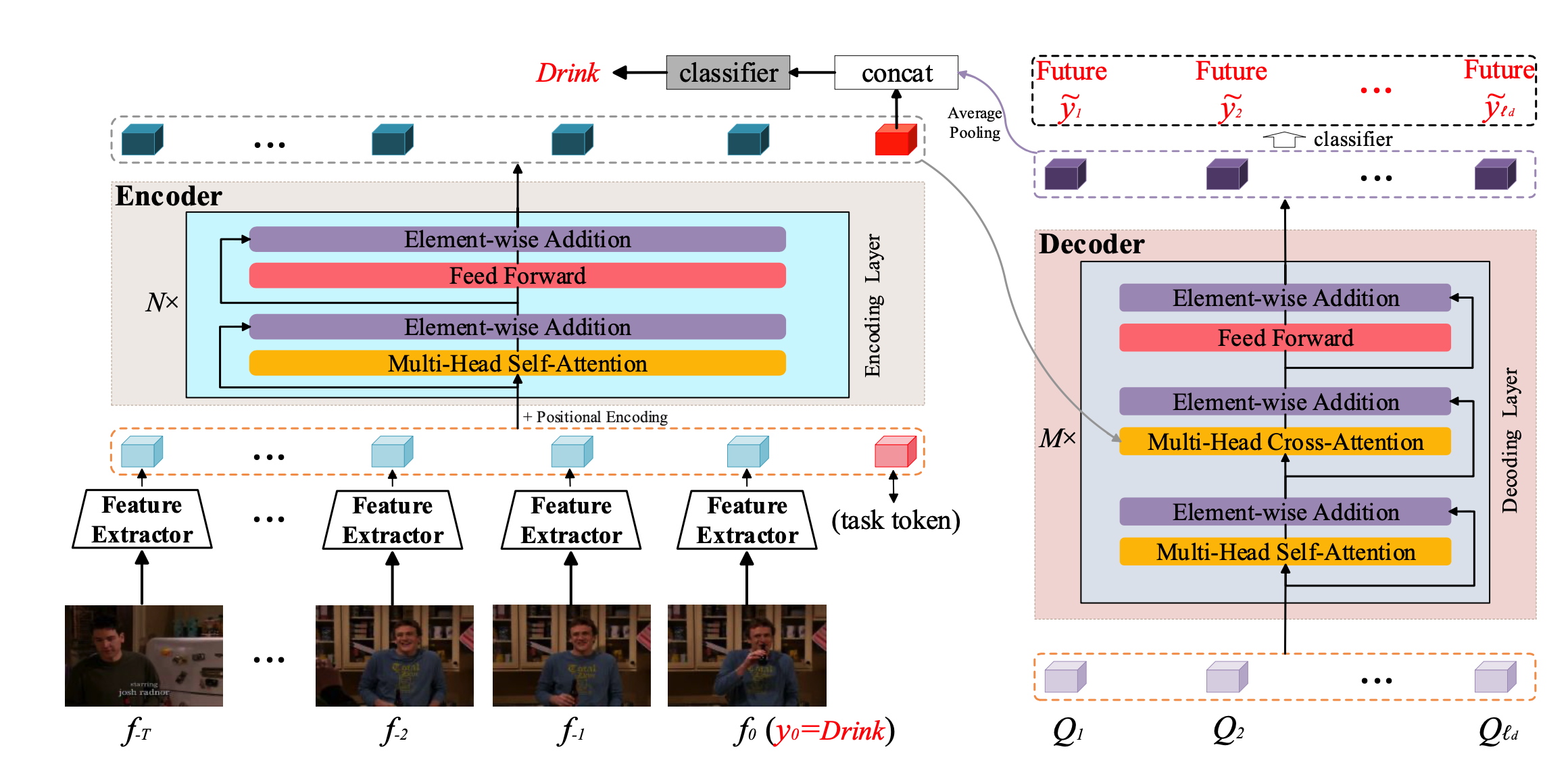
简介 之前的很多方法都是用RNN的结构去构建时序上的依赖关系,但是RNN的结构的缺点是不能并行操作,且存在梯度消失的现象。所以本文就是将之前的RNN的结构改为Transfomer的形式。延续了之前TRN的整个网络的框架,也是结合了对未来帧的预测与历史帧的表示相结合来对当前的动作进行预测。 方法 整个网络框架如上图所示, Encoder就是利用transfomer对longrange的历史和目前帧进行特征表示,其中要说明的一个点就是,这里的特征空间包含T个历史特征,当前窗口的特征以及一个task token,这个task token的作用可以从下图看出来 这幅图对比的是输入进classifier的特征与网络输入的特征的相似性,可以看出w/o task token 对应的是当前t=0时刻的特征,...
3D Model
2026-01-11
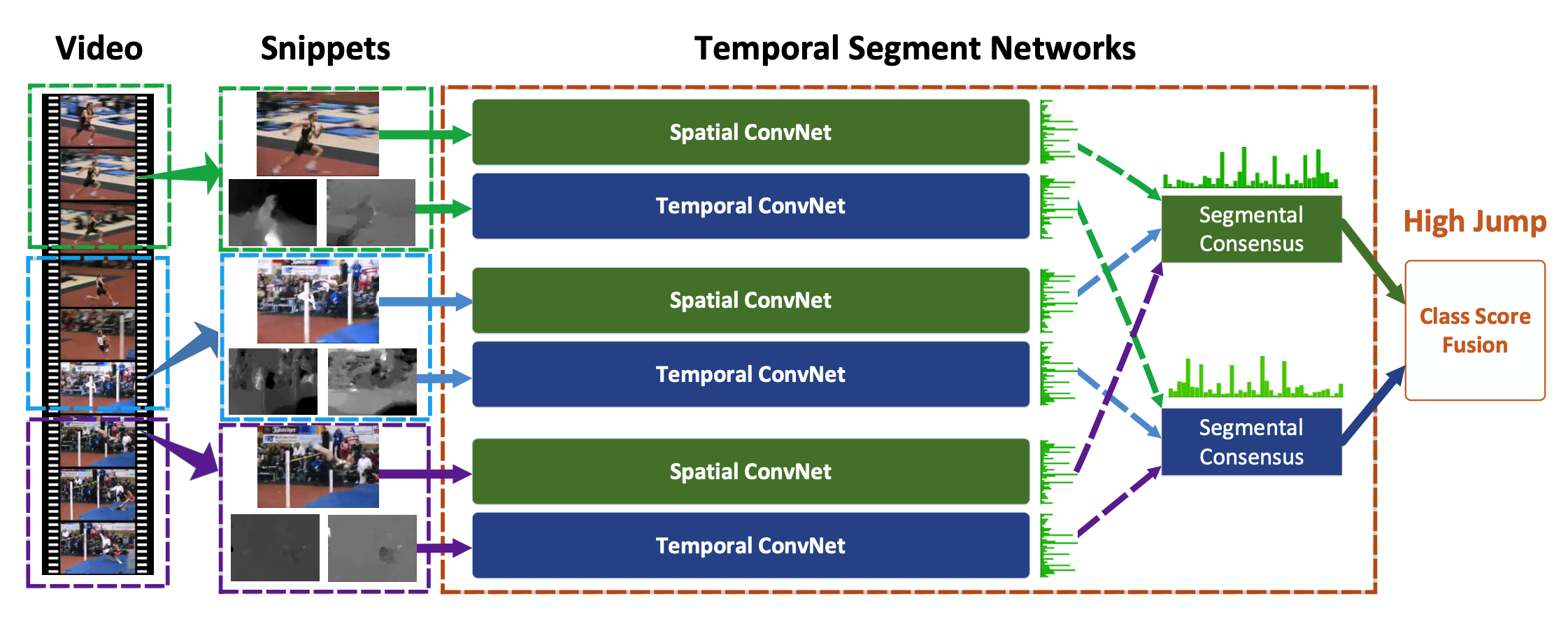
简介 这篇ECCV2016的文章主要提出TSN(temporal segment network)结构用来做视频的动作识别。TSN可以看做是双流(two stream)系列的改进,在此基础上,文章要解决两个问题:1、是longrange视频的行为判断问题(有些视频的动作时间较长)。2、是解决数据少的问题,数据量少会使得一些深层的网络难以应用到视频数据中,因为过拟合会比较严重。 针对第一个问题,首先,为什么目前的双流结构网络难以学习到视频的长时间信息?因为其针对的主要是单帧图像或者短时间内的一堆帧图像数据,但这对于时间跨度较长的视频动作检测而言是不够的。因此采用更加密集的图像帧采样方式来获取视频的长时间信息是比较常用的方法,但是这样做会增加不少时间成本,同时作者发现视频的连续帧之间存在冗余,因...
3D Model
2026-01-11
Related Work: 大概过一下之前的几个重要工作(也是本文性能对比的主要几个stateoftheart): 1. TSN:视频动作/行为识别的基本框架,将视频帧下采样(分成K个Segment,各取一帧)后接2D CNN对各帧进行处理+fusion 1. TRN:对视频下采样出来的 frames 的deep feature,使用 MLP 来融合,建立帧间temporal context 联系。最后将多级(不同采样率)出来的结果进行再一步融合,更好表征shortterm 和 longterm 关系。 1. ECO系列: 1. NL I3D+GCN:使用 nonlocal I3D来捕获longrange时空特征,使用 spacetime region graphs 来获取物体区域间的关联及...
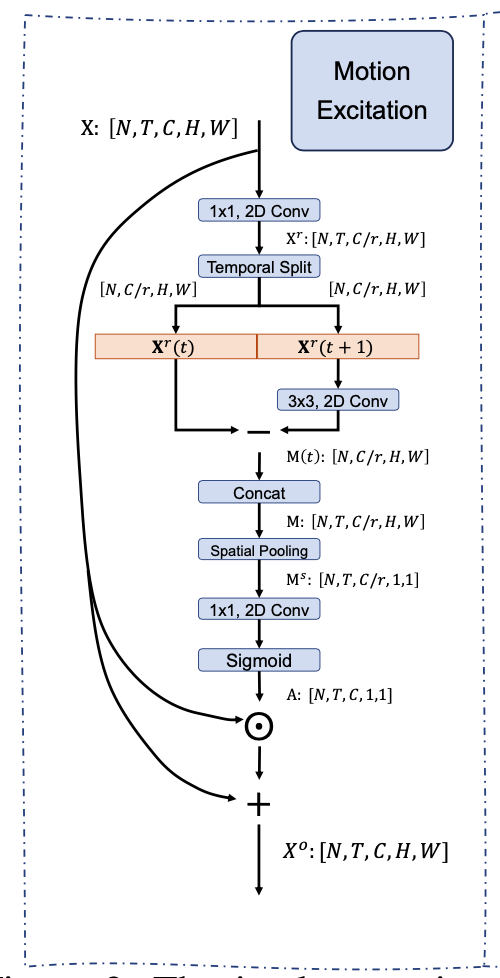
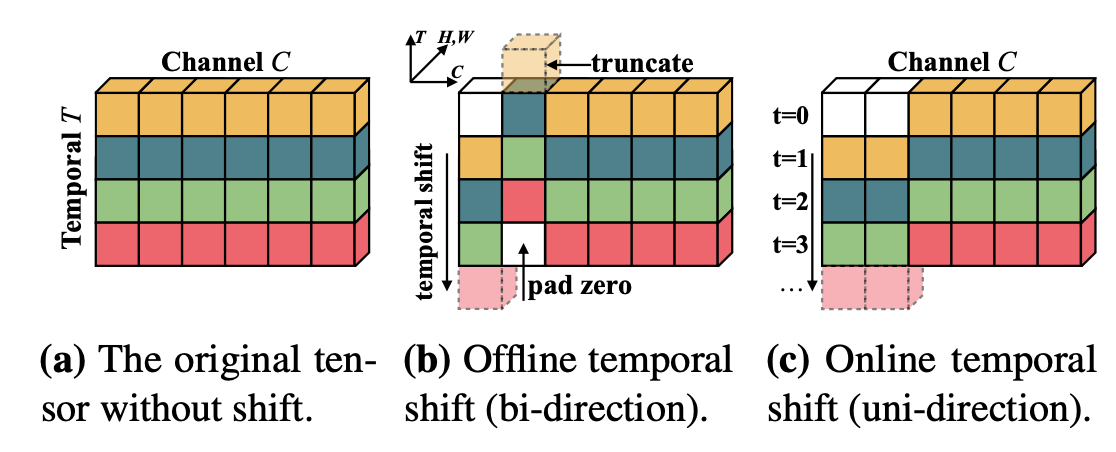
Motivation Motion feature 学习过程中存在的问题: 利用 optical flow 存储和计算的开销太大 现阶段的网络设计,spatiotemporal 建模 和Motion feature 建模分离 比如STM 直接 Add spatio temporal feature 和 motion encoding feature TEA 的 ME 则利用了 Motion feature 做 channeI attention 过去的建模都 focus 在 framelevel motion,更好的建模方式 featurelevel motion 长时建模存在的问题: 单帧过backbone,最后的feature 进行 temporal max/average poolin...
3D Model
2026-01-11

研究动机 目前 3Dbased 的方法在大规模的 scenebased 的数据集(如kinetics)上相对于2D的方法取得了更好的效果,但是3Dbased也存在一些明显的问题: 3Dbased 的网络参数量大,计算开销大,训练的 scheduler 更长,inference latency 明显慢于 2Dbased 的方法。 3D卷积其实并不能很好得学到时序上信息的变化,而且3D卷积学出来的时序Kernel的weight的分布基本一致,更多的还是对时序上的信息做一种 smooth aggregation。这一点在之前的工作TANet 中有比较详细的讨论。也基于此,3Dbased 的网络在SomethingSomething这种对时序信息比较敏感的video数据集上并不能取得很好的效果( 得...
3D Model
2026-01-11

Classification,Detection Classification:给定预先裁剪好的视频片段,预测其所属的行为类别 Detection:视频是未经过裁剪的,需要先进行人的检测where和行为定位(分析行为的始末时间)when,再进行行为的分类what。 通常所说的行为识别更偏向于对时域预先分割好的序列进行行为动作的分类,即 Trimmed Video Action Classification。 TwoStream Twostream convolutional networks 简介 TwoStream CNN网络顾名思义分为两个部分, 1. 空间流处理RGB图像,得到形状信息; 1. 时间流/光流处理光流图像,得到运动信息。 两个流最后经过softmax后,做分类分数的融合,...

进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 [代码] 上述程序输出如下(输出内容可能不同,不用太纠结下面每个线...
Deep Learning
2026-01-11

最近,似乎现在每个大型语言模型(LLM)和新闻中提到的复杂神经网络架构都使用略有不同的激活函数,而就在几年前,最常见的做法只是在神经网络的内部层中使用 ReLU。 曾经优秀的 ReLUs 怎么了,以及是什么促使最新的大型语言模型(LLMs)的创造者们开始使用不同的(更高级的)激活函数? Threshold activation (Perceptron) 1957 年,罗森布拉特建造了“感知机” 最古老的激活函数是基本感知器。它由芝加哥大学精神病学系的爱德华·麦克洛奇和沃尔特·皮茨构思,后来由弗兰克·罗森布拉特在 1957 年于康奈尔航空实验室为美国海军在硬件上更著名地实现了。该算法非常简单,其基本规则是:如果某个值超过某个阈值,则返回 1,否则返回 0。有些变体会返回 1 或1。 由于其二元...
Deep Learning
2026-01-11

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 X ,其取值来自有限集合 [Math] 。我们的目标是估计 E[X] 。假设我们有一个独立同分布的样本序列 \{x_i\}_{i=1}^n ,那么 X 的期望值可以近似为: [公式] 非增量方法与增量方法 非增量方法:先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法:定义 [公式] 可以推导出递归公式: [公式] 这个算法可以增量式地...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...