3D Model
2026-01-11
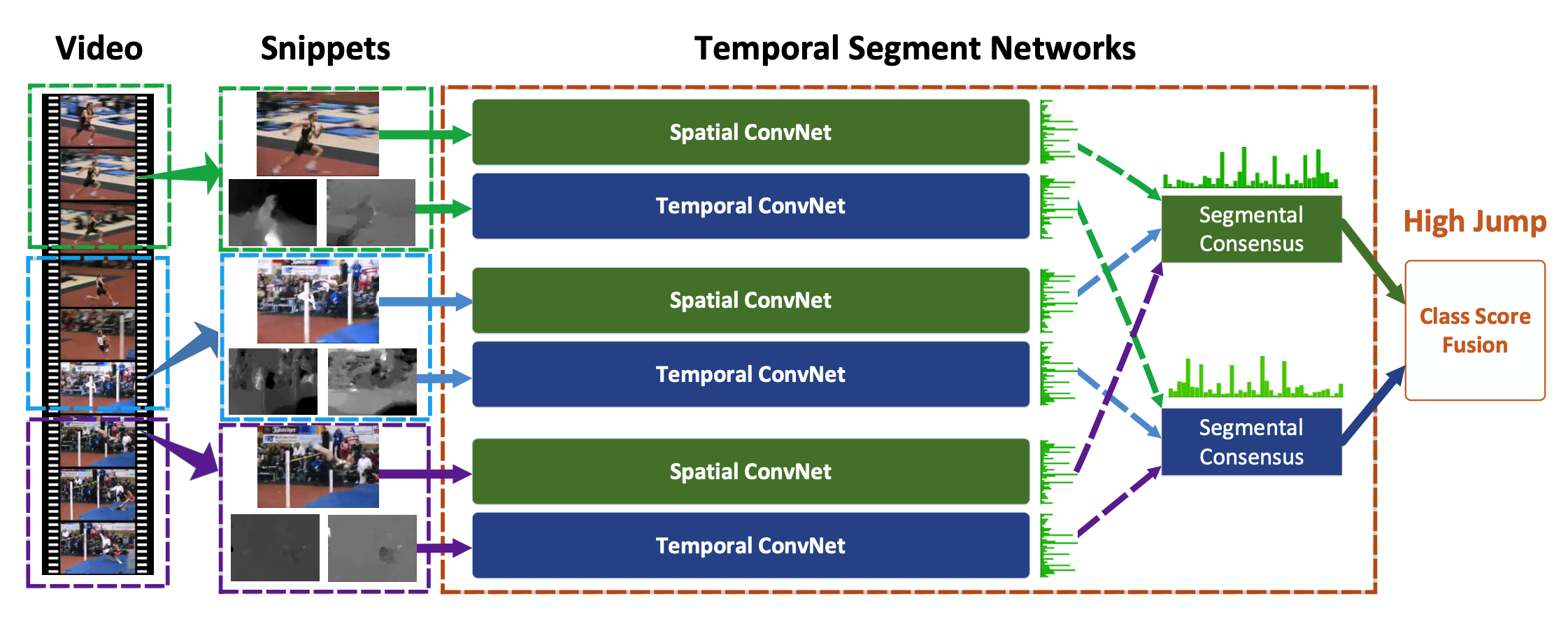
简介 这篇ECCV2016的文章主要提出TSN(temporal segment network)结构用来做视频的动作识别。TSN可以看做是双流(two stream)系列的改进,在此基础上,文章要解决两个问题:1、是longrange视频的行为判断问题(有些视频的动作时间较长)。2、是解决数据少的问题,数据量少会使得一些深层的网络难以应用到视频数据中,因为过拟合会比较严重。 针对第一个问题,首先,为什么目前的双流结构网络难以学习到视频的长时间信息?因为其针对的主要是单帧图像或者短时间内的一堆帧图像数据,但这对于时间跨度较长的视频动作检测而言是不够的。因此采用更加密集的图像帧采样方式来获取视频的长时间信息是比较常用的方法,但是这样做会增加不少时间成本,同时作者发现视频的连续帧之间存在冗余,因...