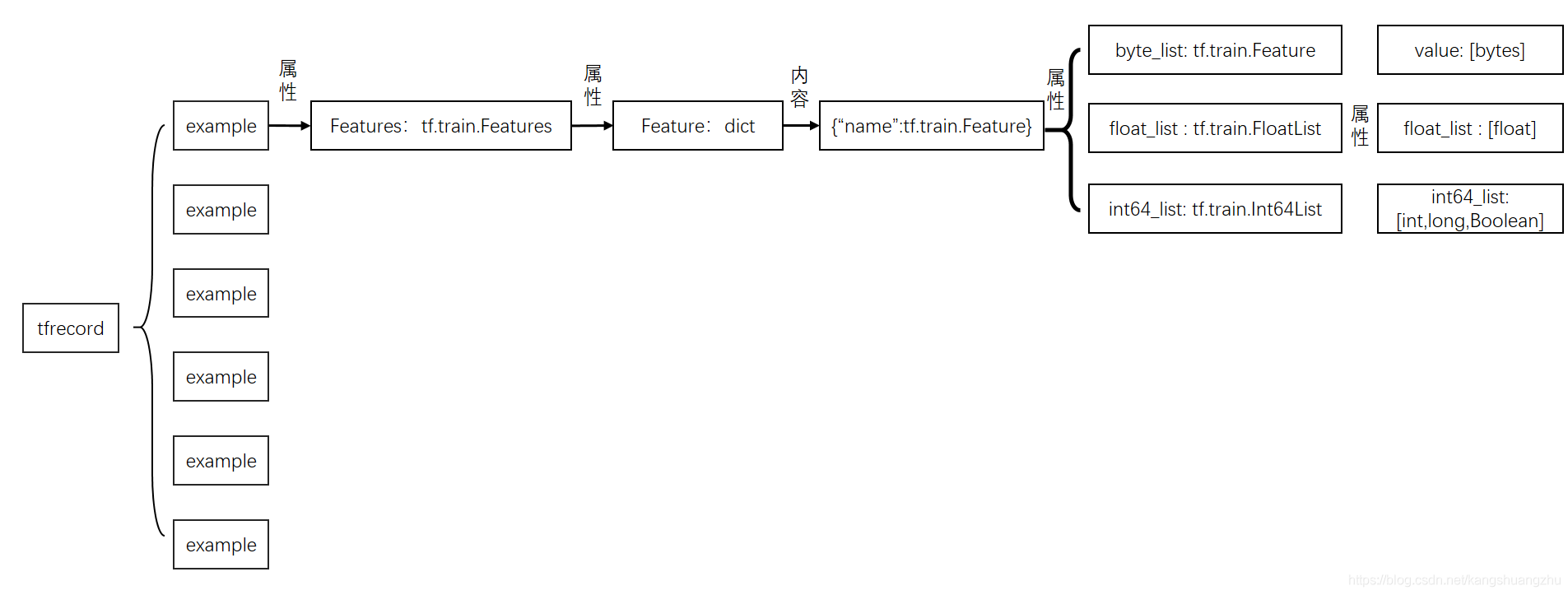
杂七杂八
2026-01-11
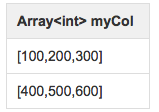
1. explode hive wiki对于expolde的解释如下: explode() takes in an array (or a map) as an input and outputs the elements of the array (map) as separate rows. UDTFs can be used in the SELECT expression list and as a part of LATERAL VIEW. As an example of using explode() in the SELECT expression list, consider a table named myTable that has a single column (m...