
236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
Algorithm
2026-02-25
实现 方式一:使用 heapq 标准库 这是 Python 最快、最节省内存的方式,因为 heapq 底层是用 C 语言实现的。 小顶堆 (Min Heap) Python 的 heapq 默认就是小顶堆。 import heapq
# 初始化
min_heap = []
# 添加元素 O(log N)
heapq.heappush(min_heap, 5)
heapq.heappush(min_heap, 2)
heapq.heappush(min_heap, 8)
# 查看堆顶 O(1)
print(min_heap[0]) # 输出: 2
# 弹出堆顶 O(log N)
pop_val = heapq.heappop(min_heap)
print(pop_val) # 输出: 2
print(min_heap) # 输出: [5, 8] (注意:堆内部不一定有序,但堆顶一定是最小的)
# 将已有的列表转化为堆 O(N)
nums = [5, 7, 1, 3]
heapq.heapify(nums)
print(nums) #...
堆和优先队列的关系 这是一个非常经典且核心的计算机科学概念问题。一言以蔽之: 优先队列(Priority Queue)是逻辑接口(ADT),而堆(Heap)是实现这个接口最高效的物理数据结构。 它们的关系可以类比为 “接口(Interface)” 与 “实现类(Implementation)” 的关系,或者 “汽车(功能)”与 “发动机(核心组件)” 的关系。 优先队列 (Priority Queue) —— 逻辑层 (ADT) 定义 :它是一种 抽象数据类型 (Abstract Data Type, ADT) 。它定义了数据的 行为 ,而不是数据的存储方式。 规则 :普通的队列是“先进先出”(FIFO),而优先队列是 “优先级最高的先出” 。 核心操作 : insert(item, priority) : 插入一个带优先级的元素。 deleteMax() 或 deleteMin() : 取出并删除优先级最高(或最低)的元素。 peek() : 查看优先级最高的元素。 堆 (Heap) —— 物理层 (Data Structure) 定义 :它是一种具体的 数据结构 。通常指 二叉堆...
引入 在具体讲何为「背包 dp」前,先来看如下的例题: 题意概要:有 \( 𝑛\) 个物品和一个容量为 \( 𝑊\) 的背包,每个物品有重量 \(𝑤_𝑖\) 和价值 \(𝑣_𝑖\) 两种属性,要求选若干物品放入背包使背包中物品的总价值最大且背包中物品的总重量不超过背包的容量. 在上述例题中,由于每个物体只有两种可能的状态(取与不取),对应二进制中的 0 和 1,这类问题便被称为「0-1 背包问题」. 0-1背包 解释 例题中已知条件有第 \(𝑖\) 个物品的重量 \(𝑤_𝑖\) ,价值 \(𝑣_𝑖\) ,以及背包的总容量 \(𝑊\) . 设 DP 状态 \(𝑓_{𝑖,𝑗} \) 为在只能放前 \(𝑖\) 个物品的情况下,容量为 \(𝑗\) 的背包所能达到的最大总价值. 考虑转移.假设当前已经处理好了前 \(𝑖 −1 \) 个物品的所有状态,那么对于第 \(𝑖\) 个物品,当其不放入背包时,背包的剩余容量不变,背包中物品的总价值也不变,故这种情况的最大价值为 \(𝑓_{𝑖−1,𝑗}\) ;当其放入背包时,背包的剩余容量会减小 \(𝑤_𝑖\) ,背包中物品的总价值会增大 \(𝑣_𝑖\)...

简介 生成树(spanning tree) 在图论中,无向图 \(G=(V,E)\) 的生成树(spanning tree)是具有 \(G\) 的全部顶点,但边数最少的联通子图。假设 \(G\) 中一共有 \(n\) 个顶点,一颗生成树满足下列条件 \(n\) 个顶点; \(n-1\) 条边; \(n\) 个顶点联通; 一个图的生成树可能有多个。 最小生成树(minimum spanning tree, MST)/最小生成森林 :联通加权无向图中边缘权重加和最小的生成树。给定无向图 \(G=(V,E)\) , \((u,v)\) 代表顶点 \(u\) 与顶点 \(v\) 的边, \(w(u,v)\) 代表此边的权重,若存在生成树T使得: \[w(T) = \sum_{(u,v)\in T}w(w,v)\] 最小,则 \(T\) 为 \(G\) 的最小生成树。对于非连通无向图来说,它的每一 连通分量 同样有最小生成树,它们的并被称为 最小生成森林 。最小生成树除了继承生成树的性质之外,还存在下面两个特点: 当图的每一条边的权值都相同时,该图的所有生成树都是最小生成树;...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
Large Model
2026-01-23

SigLIP 概述 CLIP自提出以来在zero-shot分类、跨模态搜索、多模态对齐等多个领域得到广泛应用。得益于其令人惊叹的能力,激起了研究者广泛的关注和优化。 目前对CLIP的优化主要可以分为两大类: 其一是如何降低CLIP的训练成本; 其二是如何提升CLIP的performance。 对于第一类优化任务的常见思路有3种。 优化训练架构,如 LiT 通过freezen image encoder,单独训练text encoder来进行text 和image的对齐来加速训练; 减少训练token,如 FLIP 通过引入视觉mask,通过只计算非mask区域的视觉表征来实现加速(MAE中的思路) 优化目标函数,如 CatLIP 将caption转为class label,用分类任务来代替对比学习任务来实现加速。 对于第二类提升CLIP的performance最常用和有效的手段就是数据治理,即构建高质量、大规模、高多样性的图文数据,典型的工作如:DFN。 SigLIP这篇paper 提出用sigmoid...
Large Model
2026-01-22

BLIP 论文名称 :BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (ICML 2022) 论文地址: https://arxiv.org/pdf/2201.12086.pdf 代码地址: https://github.com/salesforce/BLIP 官方解读博客: https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/ 背景和动机 视觉语言训练 (Vision-Language Pre-training, VLP) 最近在各种多模态下游任务上取得了巨大的成功。然而,现有方法有两个主要限制: 模型层面: 大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。比如,基于编码器的模型,像 CLIP,ALBEF 不能直接转移到文本生成任务...
Large Model
2026-01-22

CLIP算法原理 CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。简单的说,CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。 CLIP(contrastive language-image pre-training)主要的贡献就是 利用无监督的文本信息,作为监督信号来学习视觉特征 。 CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线: 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征; 获取更多的数据(不要求高质量,也不要求full...
Search&Rec
2026-01-11

在电商搜索中,query推荐有很多种产品形态,不同的产品形态也扮演着不同的角色,常见的有query suggestion(SUG)、猜你想搜(搜索发现、大家都在搜)、细选(锦囊)、搜索底纹、搜索PUSH、搜索“风向标”(点击回退query推荐)等。以淘宝当前版本的产品形态为例,有: 上述每个方向都值得单独介绍,而本文则先整体从query推荐角度,放在一起介绍,方便横向对比各个场景的目标和方法上的异同之处。而以经典的分类方式展开,可以将query 推荐策略放在用户搜索前、搜索中、浏览中、搜索后(本章不涉及讨论)等各个状态阶段来进行比较: 目标 以上引出了搜索query推荐的两大目标: 搜索增长,目标提升提升渗透率,将用户引导到成交效率更高的搜索场景,提升搜索活跃度,常见的产品形态有:底纹、qu...
Search&Rec
2026-01-11
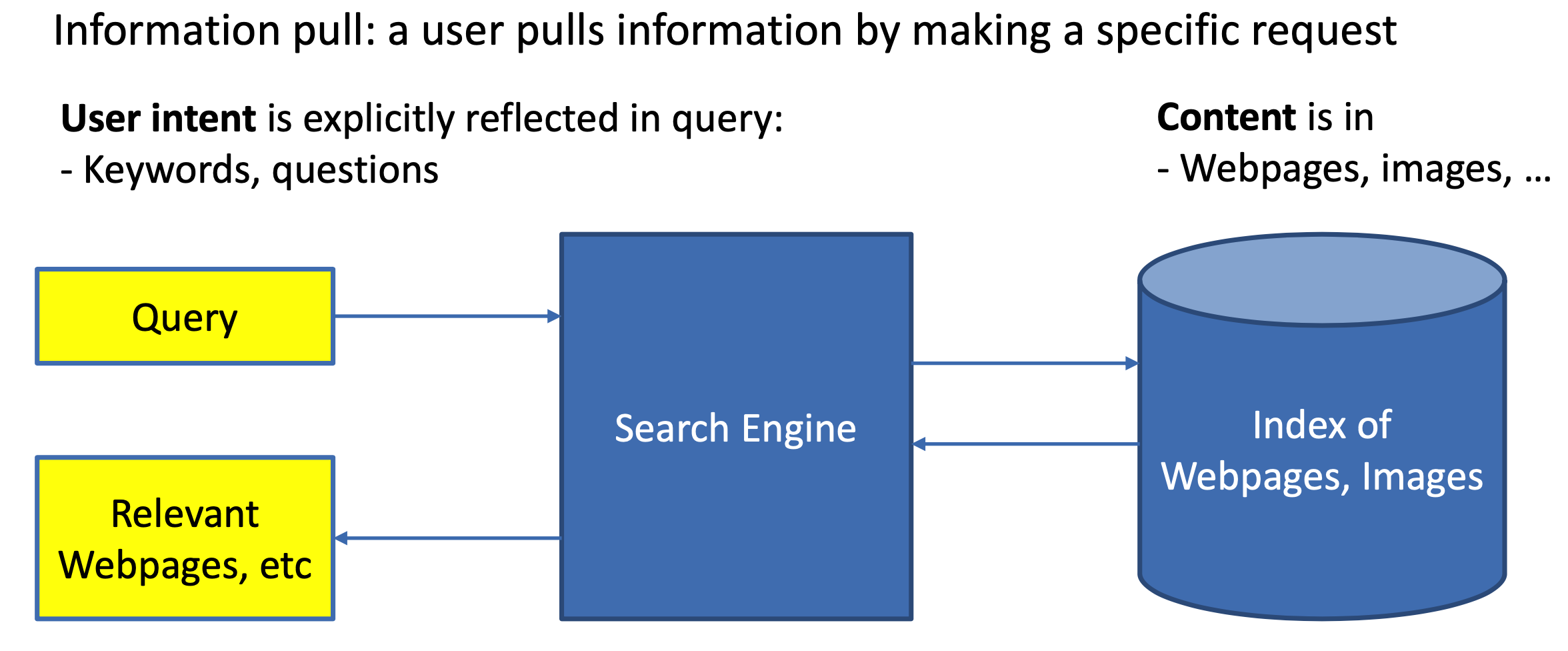
1. 搜索引擎概述 1.1 推荐和搜索比较 推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。 对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过querydoc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。 对于推荐来说,推荐系统就是系统根据用户的属性(如性别、年龄、学历等),用户在系统里过去的行为(例如浏览、点击、搜索、收藏等),以及当前上下文环境(如网络、手机设备等),从而给用户推...
Search&Rec
2026-01-11

精排是用pointwise方式对商品的CTR/CVR进行预估,旨在建模s=f(user, query, item, context) ,对候选商品进行打分。但有些情况下仅有精排还存在不足之处,如: 1、即使对单个商品进行打分,资源效率限制下,上千候选的精排有时也无法落地更加复杂的模型; 2、pointwise模式的打分无法从候选列表整体或上下文实时反馈角度出发进行排序; 3、直接使用精排分排序无法满足特殊整体性排序需求,如常见的搜索结果的多样性(如价格、地域、品牌、风格等属性的打散)、发现性、异质内容的混排调控(如商品、内容、广告等物料的混排)、流量调控等。 相应地,从以上三点出发,本文从“更加精准打分”、“关注序和上下文”、“特殊需求重排”三方面梳理重排的一般方法: 更加精准打分 重排的第...