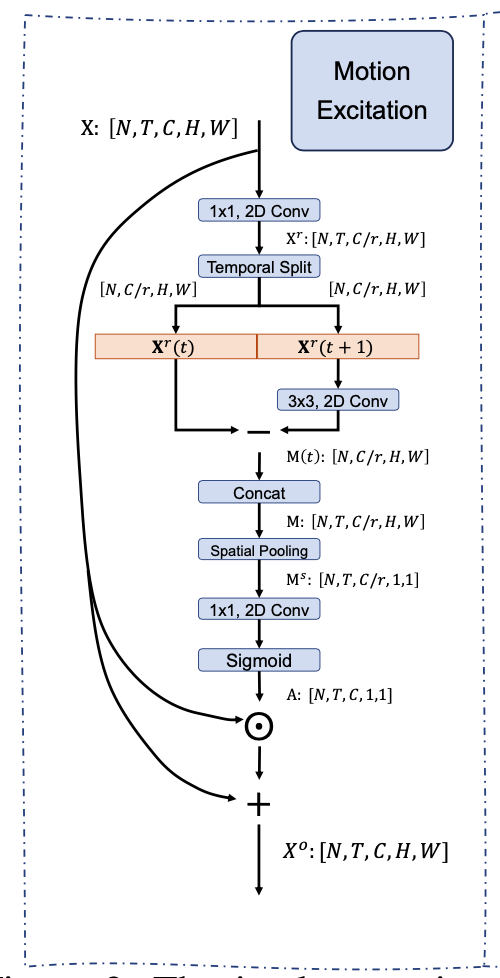
Motivation Motion feature 学习过程中存在的问题: 利用 optical flow 存储和计算的开销太大 现阶段的网络设计,spatiotemporal 建模 和Motion feature 建模分离 比如STM 直接 Add spatio temporal feature 和 motion encoding feature TEA 的 ME 则利用了 Motion feature 做 channeI attention 过去的建模都 focus 在 framelevel motion,更好的建模方式 featurelevel motion 长时建模存在的问题: 单帧过backbone,最后的feature 进行 temporal max/average poolin...
3D Model
2026-01-11

研究动机 目前 3Dbased 的方法在大规模的 scenebased 的数据集(如kinetics)上相对于2D的方法取得了更好的效果,但是3Dbased也存在一些明显的问题: 3Dbased 的网络参数量大,计算开销大,训练的 scheduler 更长,inference latency 明显慢于 2Dbased 的方法。 3D卷积其实并不能很好得学到时序上信息的变化,而且3D卷积学出来的时序Kernel的weight的分布基本一致,更多的还是对时序上的信息做一种 smooth aggregation。这一点在之前的工作TANet 中有比较详细的讨论。也基于此,3Dbased 的网络在SomethingSomething这种对时序信息比较敏感的video数据集上并不能取得很好的效果( 得...
Computer Vision
2026-01-11

空洞卷积 Dilated/Atrous Convolution 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyperparameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。 一个简单的例子 一维情况下空洞卷积的公式如下 [Formula] 不过光理解他的工作原理还是...
3D Model
2026-01-11

Classification,Detection Classification:给定预先裁剪好的视频片段,预测其所属的行为类别 Detection:视频是未经过裁剪的,需要先进行人的检测where和行为定位(分析行为的始末时间)when,再进行行为的分类what。 通常所说的行为识别更偏向于对时域预先分割好的序列进行行为动作的分类,即 Trimmed Video Action Classification。 TwoStream Twostream convolutional networks 简介 TwoStream CNN网络顾名思义分为两个部分, 1. 空间流处理RGB图像,得到形状信息; 1. 时间流/光流处理光流图像,得到运动信息。 两个流最后经过softmax后,做分类分数的融合,...
Computer Vision
2026-01-11
PA Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。 [公式] 图像中共有k+1(包含背景)类, p_{ii} 表示将第i类分成第 i 类的像素数量(正确分类的像素数量), p_{ij} 表示将第 i 类分成第 j 类的像素数量(所有像素数量) 因此该比值表示正确分类的像素数量占总像素数量的比例。 优点:简单 缺点:如果图像中大面积是背景,而目标较小,即使将整个图片预测为背景,也会有很高的PA得分,因此该指标不适用于评价以小目标为主的图像分割效果。 MPA Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。 [公式] MIoU Mean Interse...
Generative Model
2026-01-11

给定一个包含 n 维数据 x 的数据集 D , 简单起见,假设数据 [Math] . 由于真正对联合分布建模的时候, x,y 都是随机变量,故而只需讨论 p(X)=p(x_1,...,x_n) 即可,毕竟只需要令 x_n=y 即可。 给定一个具体的任务,如MNIST中的手写数字二值图分类,从Generative的角度进行Represent,并在Inference中Learning. 下面先介绍: 描述如何对这个MINST任务建模 p(X,Y) (Representation) 对MNIST任务建模 对于一张pixel为 [Math] 大小的图片,令 x_1 表示第一个pixel的随机变量, [Math] ,需明确: 任务目标:学习一个模型分布 [Math] ,使采样时 [Math] , x ...
Computer Vision
2026-01-11

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zeroshot 和 fewshot能力,结合prompt engineering和fine ...
Computer Vision
2026-01-11
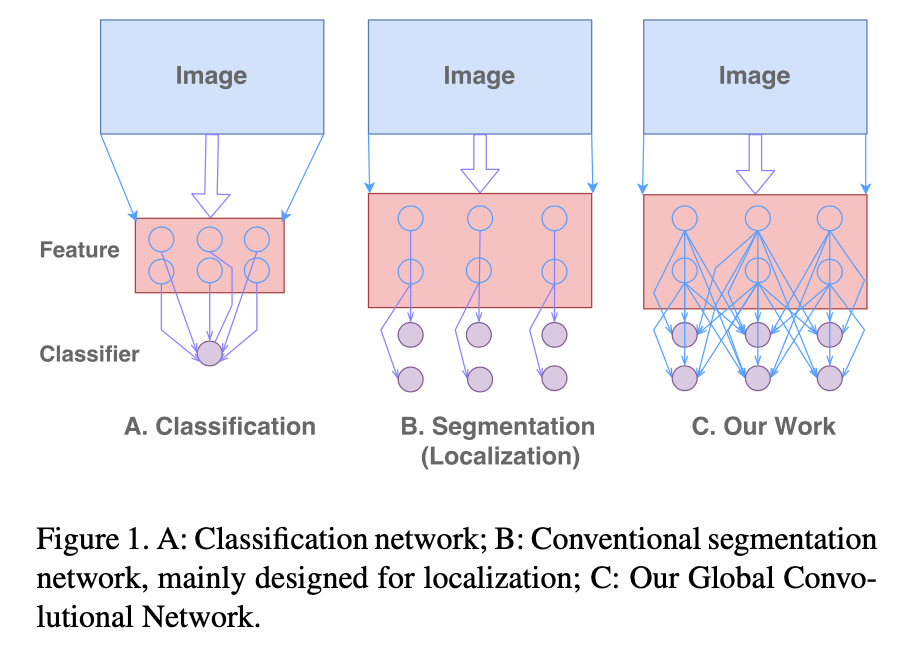
CVPR2017 算法 Global Convolutional Network(GCN),江湖人送外号“Large Kernel”。 Motivation GCN 主要将 Semantic Segmentation分解为:Classification 和 Localization两个问题。但是,这两个任务本质对特征的需求是矛盾的,Classification需要特征对多种Transformation具有不变性,而 Localization需要对 Transformation比较敏感。但是,普通的 Segmentation Model大多针对 Localization Issue设计,正如图(b)所示,而这不利于 Classification。 所以,为了兼顾这两个 Task,本文提出了两个...