Generative Model
2026-01-11
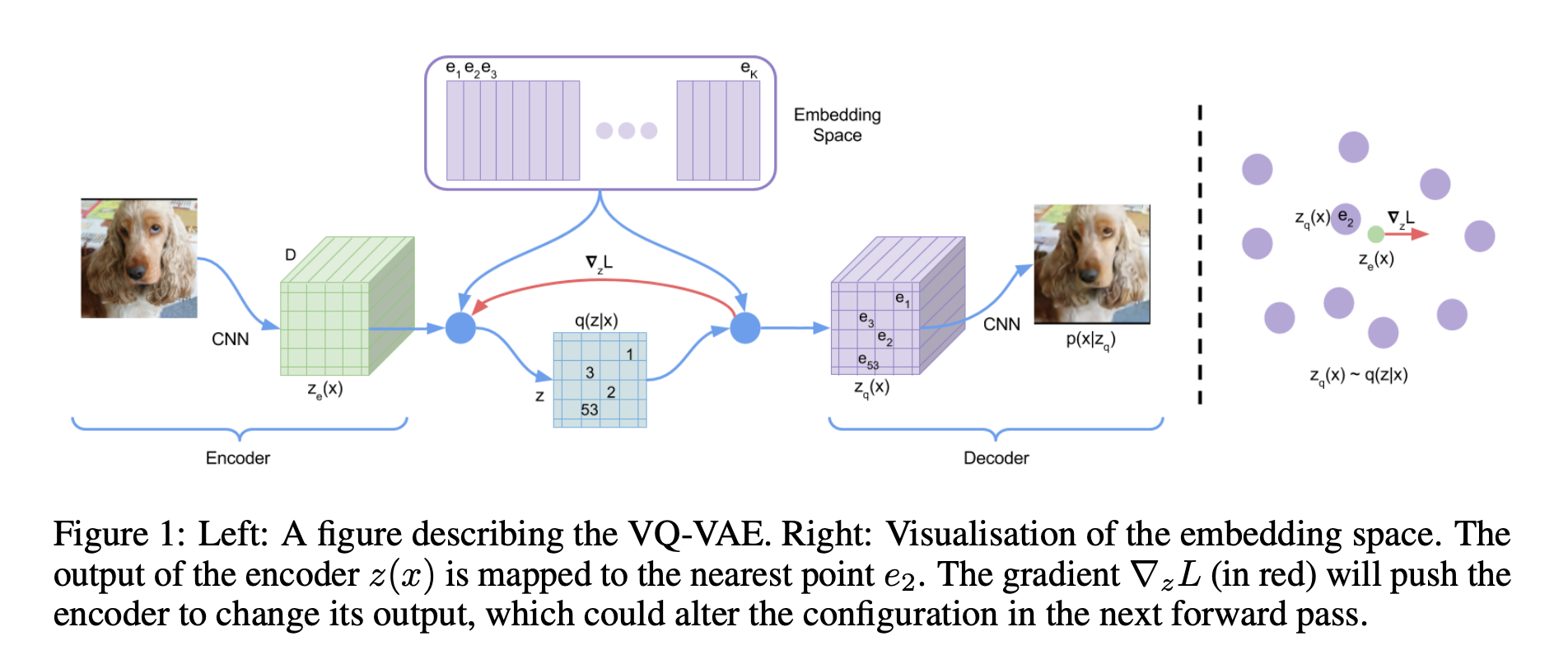
简介 作为一个自编码器,VQVAE的一个明显特征是它编码出的编码向量是离散的,换句话说,它最后得到的编码向量的每个元素都是一个整数,这也就是“Quantised”的含义,我们可以称之为“量子化”(跟量子力学的“量子”一样,都包含离散化的意思)。 明明整个模型都是连续的、可导的,但最终得到的编码向量却是离散的,并且重构效果看起来还很清晰(如文章开头的图),这至少意味着VQVAE会包含一些有意思、有价值的技巧,值得我们学习一番。 首先,VQVAE其实就是一个AE(自编码器)而不是VAE(变分自编码器),我不知道作者出于什么目的非得用概率的语言来沾VAE的边,这明显加大了读懂这篇论文的难度。其次,VQVAE的核心步骤之一是StraightThrough Estimator,这是将引变量离散化后的优...


