Generative Model
2026-03-03

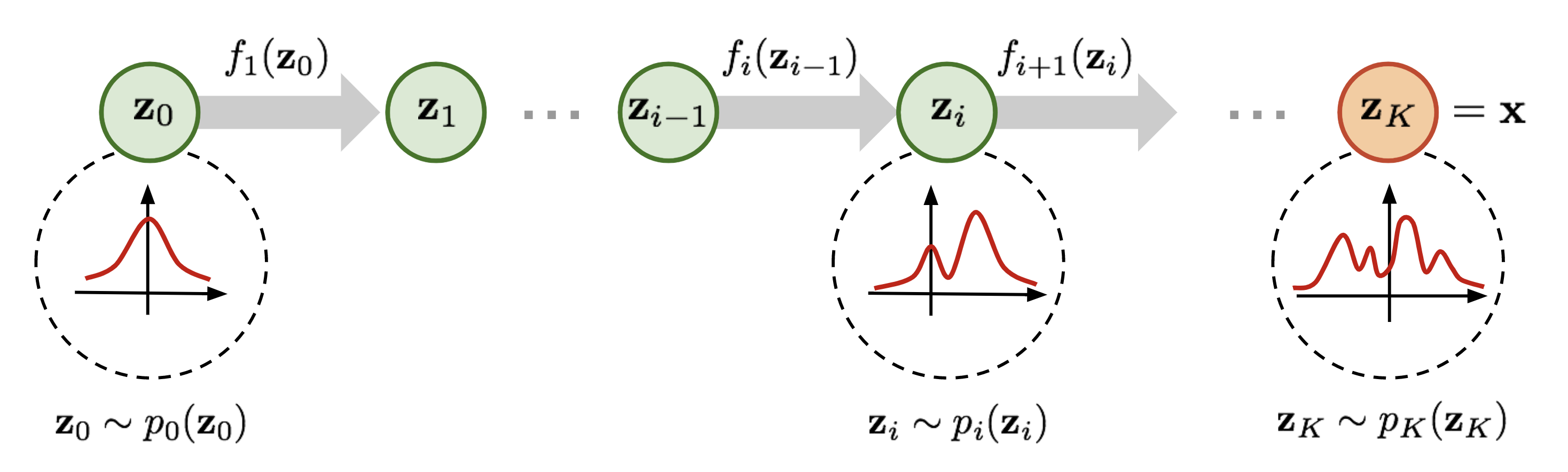
背景 本文主要是 《NICE: Non-linear Independent Components Estimation》 一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。 艰难的分布 众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。 glow模型生成的高清人脸 生成模型的本质,就是希望用一个我们知道的概率模型来拟合所给的数据样本, 也就是说,我们得写出一个带参数 \(𝜃\) 的分布 \(q_{\boldsymbol{\theta}}(\boldsymbol{x})\)...