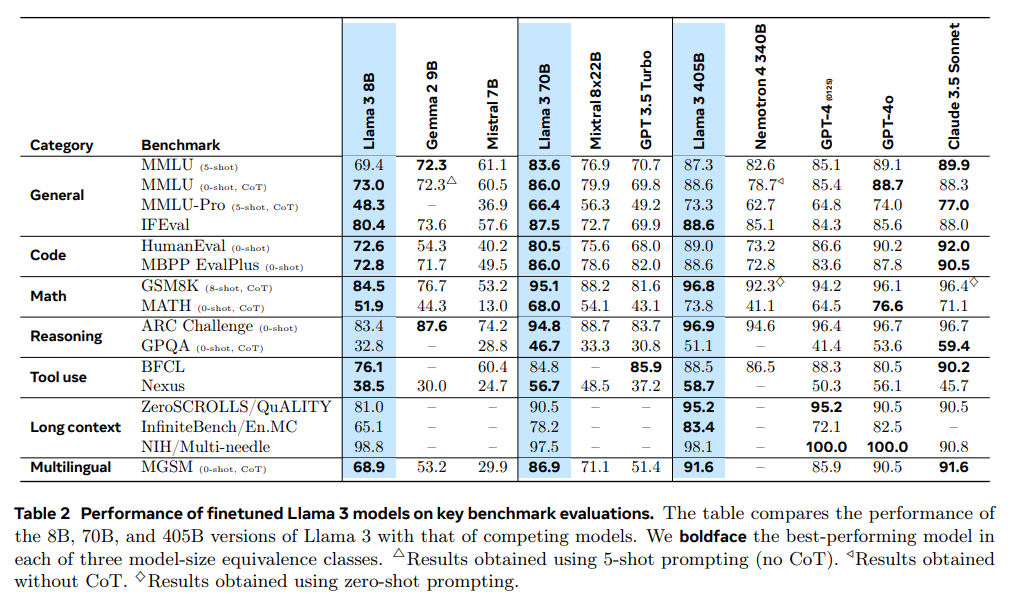
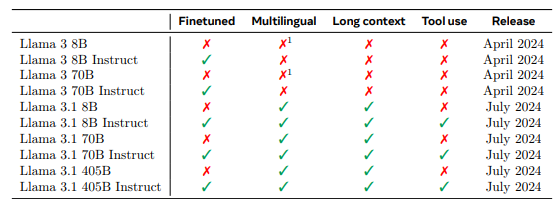
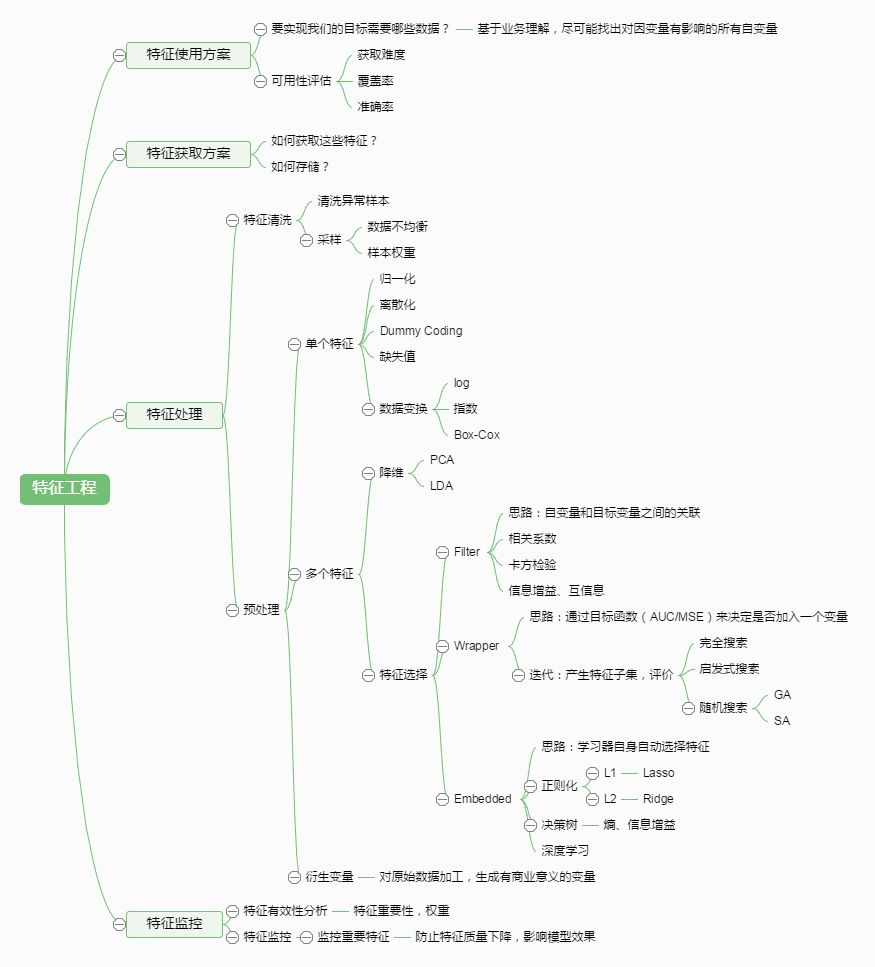
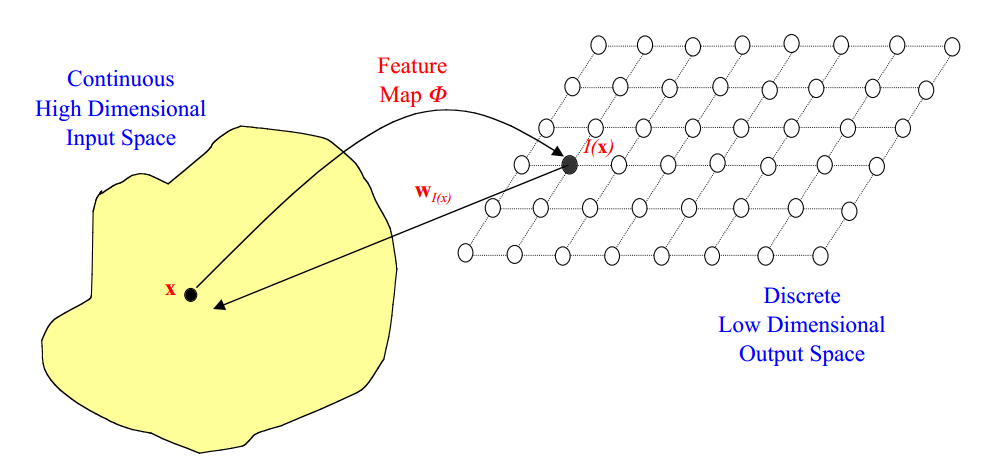
Machine Learning
2026-01-11
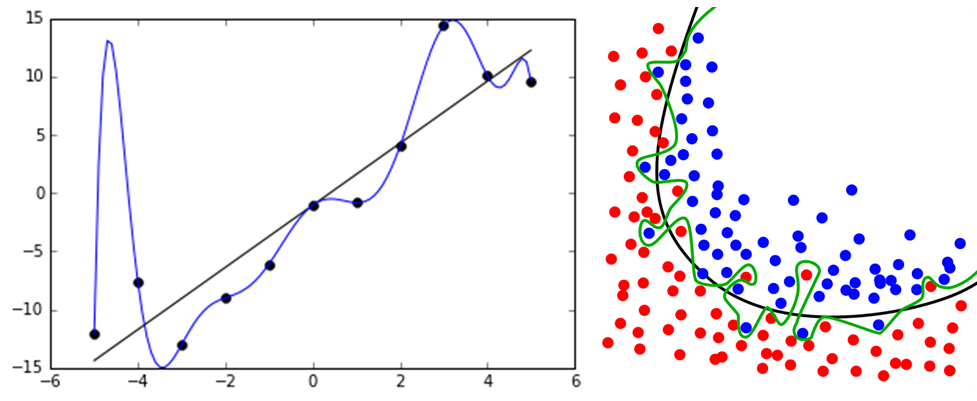
是什么 过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。 具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。 为什么 为什么要解决过拟合现象?这是因为我们拟合的模型一般是用来预测未知的结果(不在训练集内),过拟合虽然在训练集上效果好,但是在实际使用时(测试集)效果差。同时,在很多问题上,我们无法穷尽所有状态,不可能将所有情况都包含在训练集上。所以,必须要解决过拟合问题。 为什么在机器学习中比较常见?这是因为机器学习算法为了满足尽可能复杂的任务,其模型的拟合能力一般远远高于问题复杂度,也就是说,机器学习算法有「拟合出正确规则的前提下,进一步拟合噪声」的能力。 而...