背景 RLHF 通常包括三个阶段: 有监督微调(SFT) 奖励建模阶段 (Reward Model) RL微调阶段 直接偏好优化(DPO) 传统的RLHF方法分两步走: 1. 先训练一个奖励模型来判断哪个回答更好 1. 然后用强化学习让语言模型去最大化这个奖励 这个过程很复杂,就像绕了一大圈:先学习"什么是好的",再学习"如何做好"。 DPO发现了一个数学上的捷径: 1. 关键发现:对于任何奖励函数,都存在一个对应的最优策略(语言模型);反过来说,任何语言模型也隐含着一个它认为最优的奖励函数 1. 直接优化:与其先训练奖励模型再训练语言模型,不如直接训练语言模型,让它自己内化"什么是好的" 1. 数学转换:DPO将"学习判断好坏"和"学习生成好内容"这两个任务合二为一,通过一个简单的数学变换...
Large Model
2026-01-11

UITARS 简介 UITARS(User Interface Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型: 输入方式:仅使用屏幕截图作为视觉输入 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等) 模型特性:端到端的原生智能体模型,无需复杂的中间件或框架 传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: 平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。 模块化...
Large Model
2026-01-11

Stanford Alpaca 结合英文语料通过Self Instruct方式微调LLaMA 7B Stanford Alpaca简介 2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B),具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT3.5(textdavinci003),这便是指令调优LLaMA的意义所在 论文《Alpaca: A Strong OpenSource InstructionFollowing Model》 GitHub地址:https://github.c...
Large Model
2026-01-11
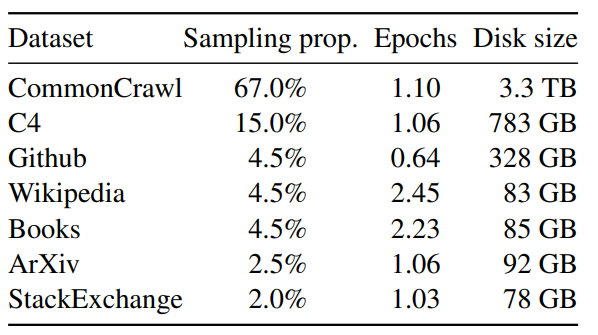
论文名称:LLaMA: Open and Efficient Foundation Language Models 论文地址: https://arxiv.org/pdf/2302.13971.pdf 代码链接: https://github.com/facebookresearch/llama 背景 模型参数量级的积累,或者训练数据的增加,哪个对性能提升帮助更大? 以 GPT3 为代表的大语言模型 (Large language models, LLMs) 在海量文本集合上训练,展示出了惊人的涌现能力以及零样本迁移和少样本学习能力。GPT3 把模型的量级缩放到了 175B,也使得后面的研究工作继续去放大语言模型的量级。大家好像有一个共识,就是:模型参数量级的增加就会带来同样的性能提升。 但...
Large Model
2026-01-11

背景 随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。 例如: 全参微调Qwen1.57BChat预估要2张80GB的A800,160GB显存 全参微调Qwen1.572BChat预估要20张80GB的A800,至少1600GB显存。 而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难 当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数 为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient finetuning, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。 LoRA LoRA(LowRank Adapt...
问题定义 多元二次多项式,维度为 n ,那么可以用以下公式描述该函数: [Formula] 其中 a_{i,j} 为二次项系数,共有 n^2 项, 1≤i,j≤n ,且所有的 a 不全为0,即 ∃a_{i,j}≠0 ; b_k 为一次项系数,共 n 项, 1≤k≤n ; c 为常数项。 记 f(x)=[x_1,x_2,...,x_n]^T ,则上述函数可以写作二次型的形式: 转化过程中A,b满足: A 为n阶对称方阵, A_{i,j}=a_{i,j} 因为 ∃a_{i,j}≠0 ,A不为零矩阵 b_i=b_i 为了后续计算简便,我们将二次型稍作改动: [Formula] 我们的目标就是寻找该函...
Large Model
2026-01-11
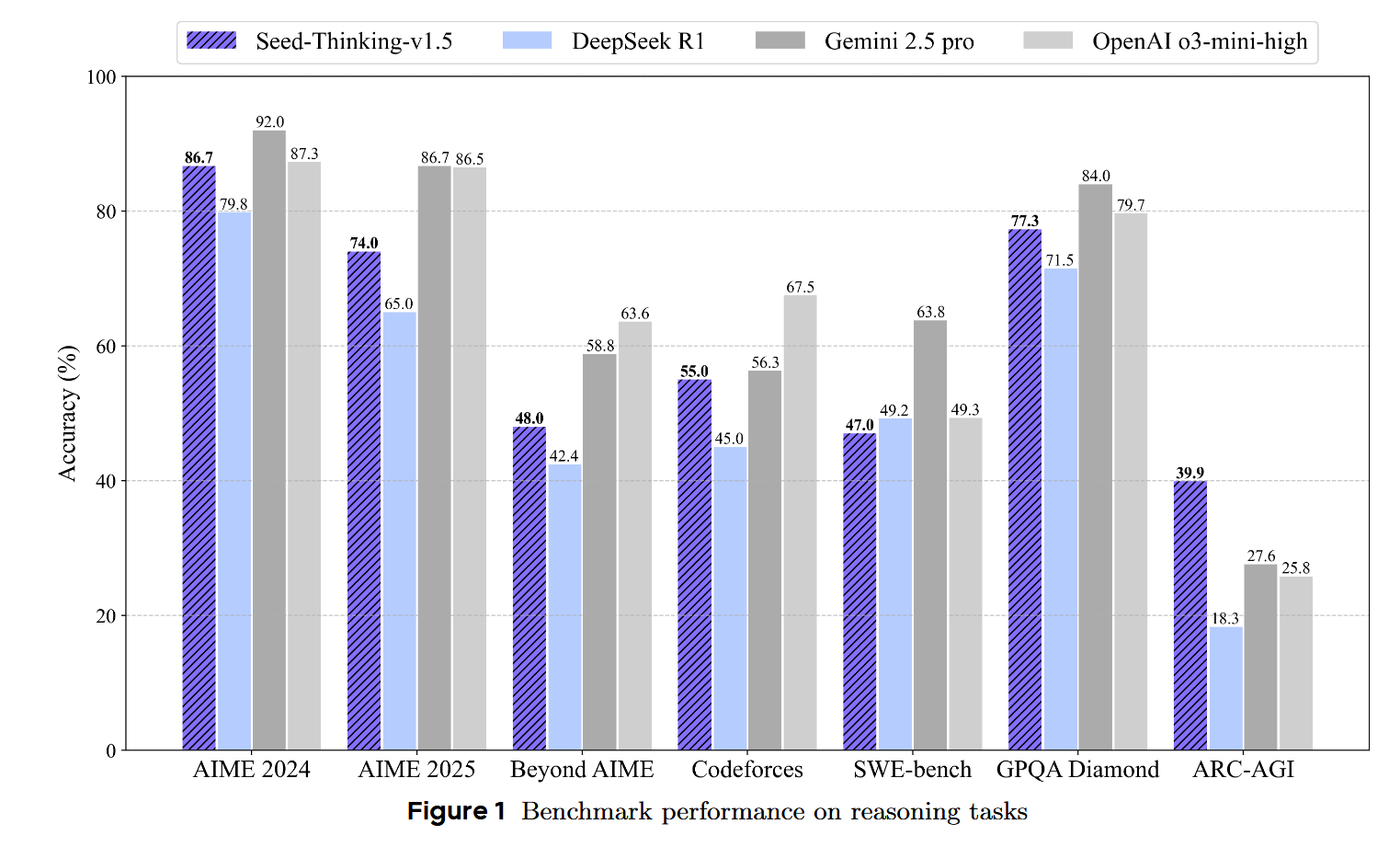
SeedThinkingv1.5 SeedThinkingv1.5 是 ByteDance Seed 团队开发的一个先进推理模型,采用 MixtureofExperts (MoE) 架构,具有 200B 总参数和 20B 激活参数。该模型的核心创新在于其"思考后回答"的机制,在数学、编程、科学推理等任务上取得了卓越的性能。相比DeepSeek R1 ,在很多数据指标上都取得了一定程度的进步。 数据 训练数据分为两大类:可验证问题(有明确答案)和不可验证问题(无明确答案)。模型的推理能力主要来自第一部分,并能泛化到第二部分。 可验证问题数据 可验证数据主要包含 STEM数据, 编程数据,以及逻辑推理数据 STEM 数据 编程数据 逻辑推理数据 不可验证问题数据 这其中的数据主要包含需要基于人类...
Large Model
2026-01-11

Chameleon:生成理解统一模型的开山之作 🔖 https://arxiv.org/pdf/2405.09818 Chameleon 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。完整记录了为实现 mixedmodal 模型的架构设计,稳定训练方法,对齐的配方。并在一系列全面的任务上进行评估:有纯文本任务,也有图像文本任务 (视觉问答、图像字幕),也有图像生成任务,还有混合模态的生产任务。 如下图所示,Chameleon 将所有模态数据 (图像、文本和代码) 都表示为离散 token,并使用统一的 Transformer 架构。训练数据是交错混合模态数据 ∼10T token,以端到端的方式从头开始训练。文本 token 用绿色表示,图像...
基本概念 方向导数:是一个数;反映的是 f(x,y) 在 P_0 点沿方向 v 的变化率。 偏导数:是多个数(每元有一个);是指多元函数沿坐标轴方向的方向导数,因此二元函数就有两个偏导数。 偏导函数:是一个函数;是一个关于点的偏导数的函数。 梯度:是一个向量;每个元素为函数对一元变量的偏导数;它既有大小(其大小为最大方向导数),也有方向。 方向导数 反映的是 f(x,y) 在 P_0 点沿方向 v 的变化率。 例子如下: 题目 设二元函数 f(x, y) = x^2 + y^2 ,分别计算此函数在点 (1, 2) 沿方向 w=\{3, 4\} 与方向 u=\{1, 0\} 的方向导数。 解: ...
Large Model
2026-01-11
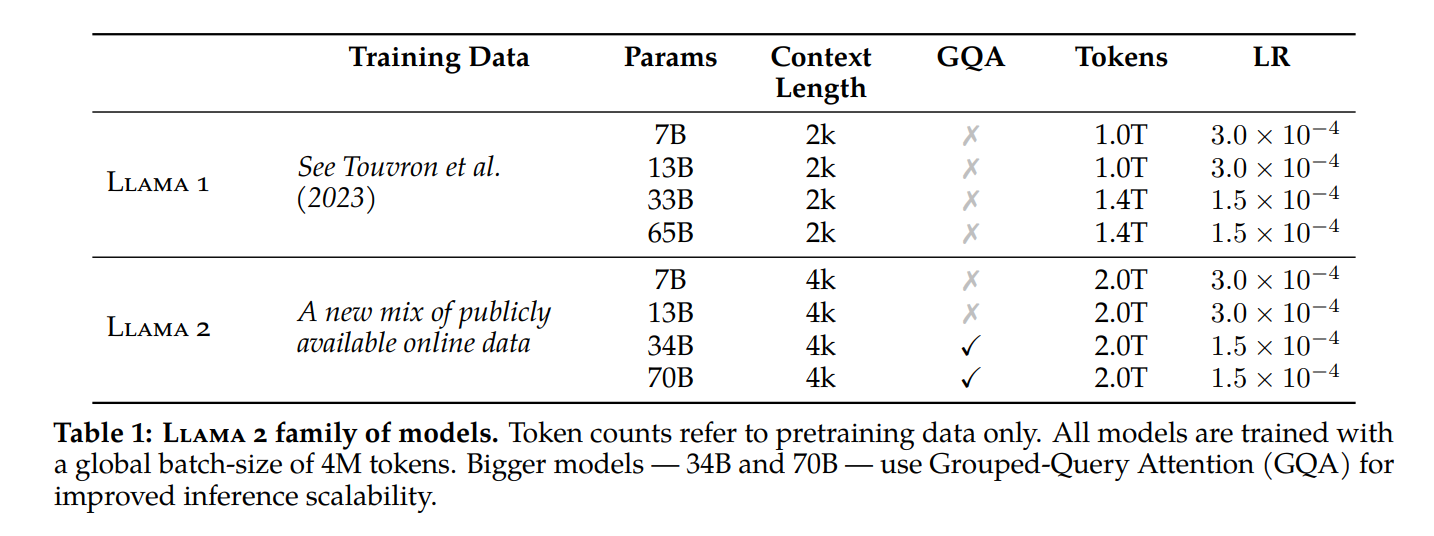
简介 模型结构 32K词表大小 2T训练数据 4K上下文长度 模型种类:7B、13B、70B(用了GQA) LLaMA 2Chat:三个版本——7B 13B 70B 同时 Meta 还发布了 LLaMA 2CHAT,其是基于 LLAMA 2 针对对话场景微调的版本,同样 7B、13B 和 70B 参数三个版本,具体的训练方法与ChatGPT类似 1. 先是监督微调LLaMA2得到SFT版本 (接受了成千上万个人类标注数据的训练,本质是问题答案对 ) 1. 然后使用人类反馈强化学习(RLHF)进行迭代优化 先训练一个奖励模型 然后在奖励模型/优势函数的指引下,通过拒绝抽样(rejection sampling)和近端策略优化(PPO)的方法迭代模型的生成策略 LLAMA 2 的性能表现更加接近...
Large Model
2026-01-11

概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 D = \{(x_i, y^_i)\}_{i=1}^n ,其中包含问题 x_i 和对应的真实答案 y^_i ,目标是训练一个策略模型 [Math] 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 z = (z_1, z_2, ..., z_m) 来连接问题 x 和答案 y ,每个 z_i 是解决问题的重要中间步骤。 当解决问题 x 时,思维 [Math] 被自回归采样,最终答案 [Math] 。 强化学习目标 基于真实答案 y^ ,分配一个值 [Math] , Ki...
Large Model
2026-01-11

引言 Structured Generation with LLM,是指让LLM按照预先定义的schema,输出符合schema的结构化结果。 常见的应用场景有: 1. 数据处理。主要功能为a b,即从源文本中抽取/生成符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; 1. Agent。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor,一个基于prompt的技术方案;Kor比较适合数据处理场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行...