128. 最长连续序列 题目 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例 1: 输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。 示例 2: 输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9 示例 3: 输入:nums = [1,0,1,2]
输出:3 提示: 0 <= nums.length <= 10 5 -10 9 <= nums[i] <= 10 9 题解 我们需要在 \(O(1)\) 的时间内查找某个数是否存在。因此,首先将数组中的所有元素放入一个 HashSet 中。这不仅能去重,还能支持快速查找。 避免冗余计算 (关键优化) 如果我们对集合中的每一个数都尝试去向后计数(例如,对于 x ,尝试找 x+1 , x+2 ...),最坏情况下的时间复杂度会退化到 \(O(n^2)\) 。 优化策略 : 我们 只从序列的起点开始计数 。...
76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...
Deep Learning
2026-01-11
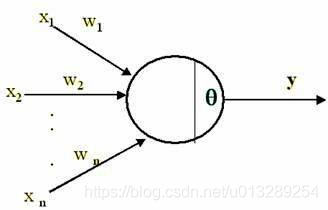
1.深度学习偏置的作用? 我们在学深度学习的时候,最早接触到的神经网络应该属于感知器(感知器本身就是一个很简单的神经网络,也许有人认为它不属于神经网络,当然认为它和神经网络长得像也行) 要想激活这个感知器,使得 y=1 ,就必须使 x_1w_1 + x_2w_2 +....+x_nw_n T ( T 为一个阈值),而 T 越大,想激活这个感知器的难度越大,人工选择一个阈值并不是一个好的方法,因为样本那么多,我不可能手动选择一个阈值,使得模型整体表现最佳,那么我们可以使得T变成可学习的,这样一来, T 会自动学习到一个数,使得模型的整体表现最佳。当把T移动到左边,它就成了偏置, x_1w_1 + x_2w_2 +....+x_nw_n T 0 xw +b 0 ,总之,偏置的大小控制着激活这个感...
Deep Learning
2026-01-11
一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。 还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到 [Math] 等操作),所以没法直接用。 这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀...
Deep Learning
2026-01-11
如何计算RF 公式一:这个算法从top往下层层迭代直到追溯回input image,从而计算出RF。 [公式] 其中,RF是感受野。RF和RF有点像,N代表 neighbour,指的是第n层的 a feature在n1层的RF,记住N_RF只是一个中间变量,不要和RF混淆。 stride是步长,ksize是卷积核大小。
Large Model
2026-01-11

这是OpenCompass的offitial ranking 榜单 🔖 https://rank.opencompass.org.cn/home MMBench 鉴于现行评测方式所存在的问题,我们重新定义了一套针对当前多模态大模型的评测流程——MMBench。其主要包含两个方面: 自上而下的能力维度设计,根据定义的能力维度构造了一个评测数据集 引入 ChatGPT,以及提出了 CircularEval 的评测方式,使得评测的结果更加稳定 Paper 链接: 🔖 https://arxiv.org/pdf/2307.06281 github: 数据集 数据集构造 主要目的是对模型的各种能力进行全方位的考察,所以我们自上而下定义了三级能力维度 (L1L3), 第一级维度(L1)包含感知与推理两项...
Deep Learning
2026-01-11

最近,似乎现在每个大型语言模型(LLM)和新闻中提到的复杂神经网络架构都使用略有不同的激活函数,而就在几年前,最常见的做法只是在神经网络的内部层中使用 ReLU。 曾经优秀的 ReLUs 怎么了,以及是什么促使最新的大型语言模型(LLMs)的创造者们开始使用不同的(更高级的)激活函数? Threshold activation (Perceptron) 1957 年,罗森布拉特建造了“感知机” 最古老的激活函数是基本感知器。它由芝加哥大学精神病学系的爱德华·麦克洛奇和沃尔特·皮茨构思,后来由弗兰克·罗森布拉特在 1957 年于康奈尔航空实验室为美国海军在硬件上更著名地实现了。该算法非常简单,其基本规则是:如果某个值超过某个阈值,则返回 1,否则返回 0。有些变体会返回 1 或1。 由于其二元...
Deep Learning
2026-01-11

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 X ,其取值来自有限集合 [Math] 。我们的目标是估计 E[X] 。假设我们有一个独立同分布的样本序列 \{x_i\}_{i=1}^n ,那么 X 的期望值可以近似为: [公式] 非增量方法与增量方法 非增量方法:先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法:定义 [公式] 可以推导出递归公式: [公式] 这个算法可以增量式地...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...
Large Model
2026-01-11

模型概述 KimiVL 是一个高效的开源混合专家视觉语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(KimiVLA3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等. 模型架构 KimiVL 的架构由三个主要部分组成: MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters 视觉模型 400M nativeresolution MoonViT vision encoder. MLP Projector MoonViT: 原生...
Large Model
2026-01-11

UITARS 简介 UITARS(User Interface Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型: 输入方式:仅使用屏幕截图作为视觉输入 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等) 模型特性:端到端的原生智能体模型,无需复杂的中间件或框架 传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: 平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。 模块化...
Deep Learning
2026-01-11

AdamW目前是大语言模型训练的默认优化器,而大部分资料对Adam跟AdamW区别的介绍都不是很明确,在此梳理一下Adam与AdamW的计算流程,明确一下二者的区别。 TLDR:AdamW将优化过程中使用的针对网络权重的衰减项(或者叫正则项)从loss中单独拿了出来,不参与Adam中一二阶动量的计算。 下面是二者的详细对比: Adam 首先是Adam,给定在迭代步数 t 时模型的参数 [Math] 与梯度 g_t ,Adam的计算公式如下: [公式] 式(1)用于计算梯度的一阶指数滑动平均 式(2)用于计算梯度的二阶项的指数滑动平均 式(3)与(4)对计算得到的指数滑动平均值进行消偏 式(5)为Adam的更新公式,其可以拆成两部分理解:动量更新与自适应学习率。 AdamW AdamW 相对与...