Large Model
2026-03-09
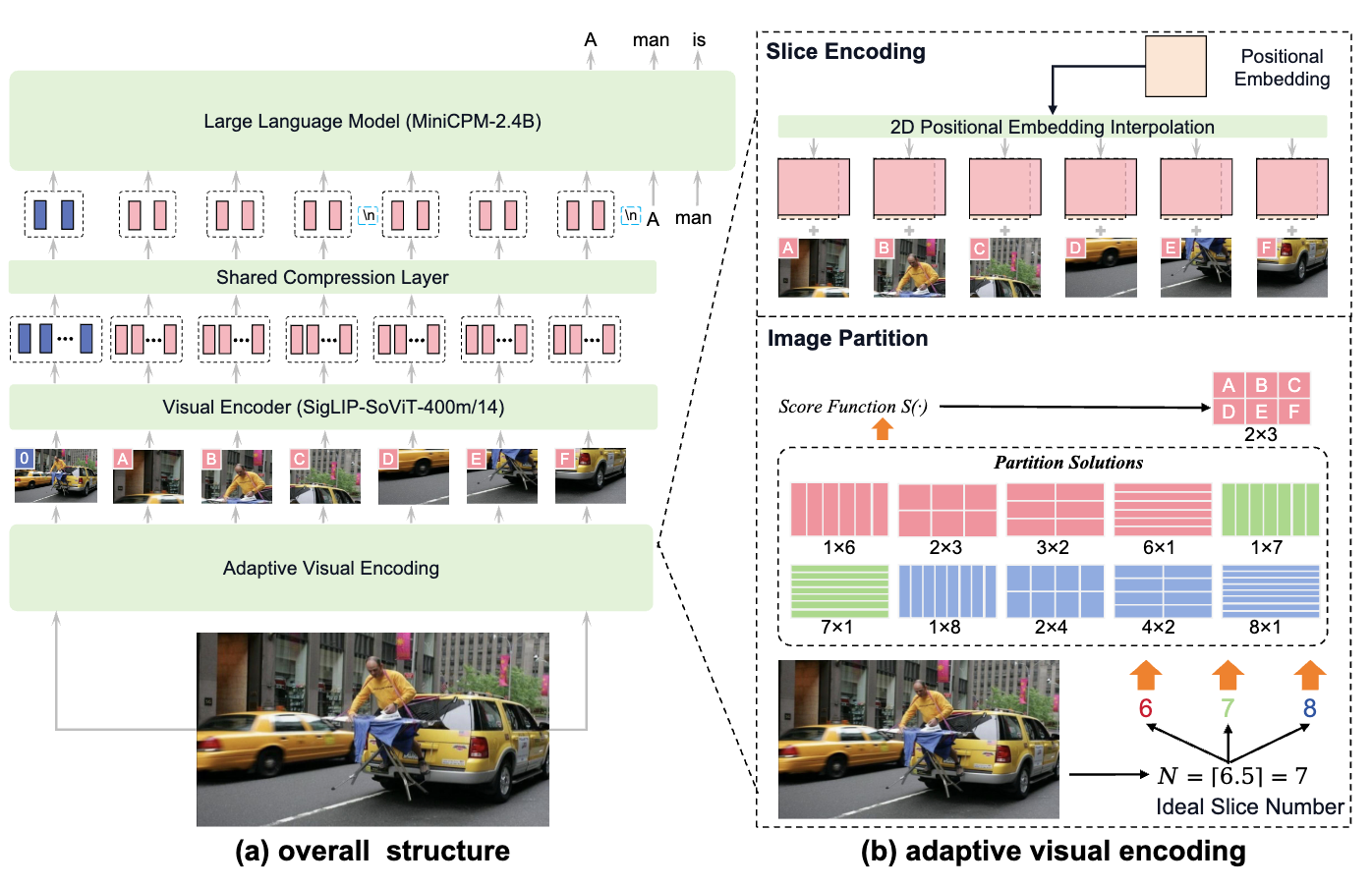
简介 在深度学习模型(尤其是 Transformer 架构)的训练中,输入数据的长度通常需要保持一致。如果直接输入大量短文本,就需要用大量无意义的占位符(Padding)来补齐长度,这会极大地浪费 GPU 的计算资源。为了最大化计算效率,目前基本主流的训练框架里都会加入 数据打包(Data Packing) 的逻辑,本文以 lmms-engine 中的操作为例,具体查看实际训练时对数据packing操作以及 use_rmpad 消除所有padding计算的逻辑 Packing Dataset 如下 Dataset 代码所示,这段代码核心目标是: 在不超过预设最大长度( packing_length )的前提下,尽可能多地将短样本塞进同一个批次(Batch)中。 这种做法带来了两个显著的好处: 提升计算效率 :减少了 Padding Token 的数量,让 GPU 的每一次矩阵乘法都作用在真实有效的数据上。 稳定训练过程 :每个 Batch 的有效 Token 数量更加一致,有助于梯度的稳定 if self.config.packing:
# Reset index at...