129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...
Generative Model
2026-01-18

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Generative Model
2026-01-18

2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVAE把图像压缩成离散编码的思想,推广了「先压缩,再生成」的两阶段图像生成思路,启发了无数后续工作。 VQGAN 核心思想 VQGAN的论文名为 Taming Transformers for High-Resolution Image Synthesis,直译过来是「驯服Transformer模型以实现高清图像合成」。可以看出,该方法是在用Transformer生成图像。可是,为什么这个模型叫做VQGAN,是一个GAN呢?这是因为,VQGAN使用了两阶段的图像生成方法: 训练时,先训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。 生成时, 先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像 。 其中,第一个图像压缩模型叫做VQGAN,第二个压缩图像生成模型是一个基于Transformer的模型。...
Generative Model
2026-01-18

分布变换 通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量 \(Z\) 生成目标数据 \(X\) 的模型,但是实现上有所不同。更准确地讲,它们是假设了 \(Z\) 服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型 \(X=g(Z)\) ,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。 生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式 那现在假设 \(Z\) 服从标准的正态分布,那么我就可以从中采样得到若干个 \(Z_1, Z_2, \dots, Z_n\) ,然后对它做变换得到 \(\hat{X}_1 = g(Z_1),\hat{X}_2 = g(Z_2),\dots,\hat{X}_n = g(Z_n)\) ,我们怎么判断这个通过 \(g\)...
Deep Learning
2026-01-11
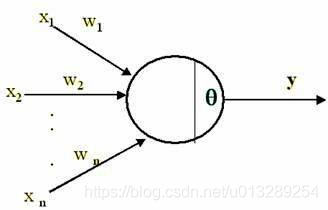
1.深度学习偏置的作用? 我们在学深度学习的时候,最早接触到的神经网络应该属于感知器(感知器本身就是一个很简单的神经网络,也许有人认为它不属于神经网络,当然认为它和神经网络长得像也行) 要想激活这个感知器,使得 y=1 ,就必须使 x_1w_1 + x_2w_2 +....+x_nw_n T ( T 为一个阈值),而 T 越大,想激活这个感知器的难度越大,人工选择一个阈值并不是一个好的方法,因为样本那么多,我不可能手动选择一个阈值,使得模型整体表现最佳,那么我们可以使得T变成可学习的,这样一来, T 会自动学习到一个数,使得模型的整体表现最佳。当把T移动到左边,它就成了偏置, x_1w_1 + x_2w_2 +....+x_nw_n T 0 xw +b 0 ,总之,偏置的大小控制着激活这个感...
Deep Learning
2026-01-11
如何计算RF 公式一:这个算法从top往下层层迭代直到追溯回input image,从而计算出RF。 [公式] 其中,RF是感受野。RF和RF有点像,N代表 neighbour,指的是第n层的 a feature在n1层的RF,记住N_RF只是一个中间变量,不要和RF混淆。 stride是步长,ksize是卷积核大小。
Large Model
2026-01-11

这是OpenCompass的offitial ranking 榜单 🔖 https://rank.opencompass.org.cn/home MMBench 鉴于现行评测方式所存在的问题,我们重新定义了一套针对当前多模态大模型的评测流程——MMBench。其主要包含两个方面: 自上而下的能力维度设计,根据定义的能力维度构造了一个评测数据集 引入 ChatGPT,以及提出了 CircularEval 的评测方式,使得评测的结果更加稳定 Paper 链接: 🔖 https://arxiv.org/pdf/2307.06281 github: 数据集 数据集构造 主要目的是对模型的各种能力进行全方位的考察,所以我们自上而下定义了三级能力维度 (L1L3), 第一级维度(L1)包含感知与推理两项...
Generative Model
2026-01-11
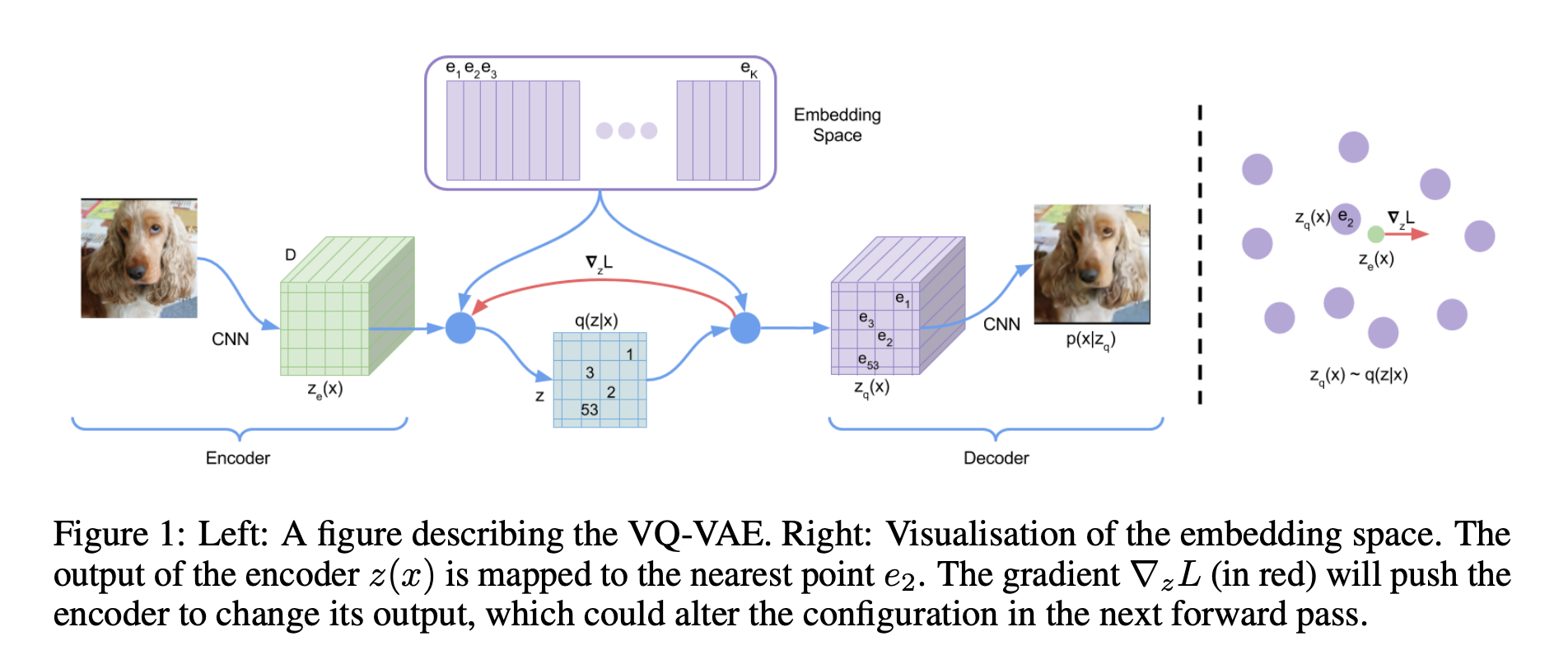
简介 作为一个自编码器,VQVAE的一个明显特征是它编码出的编码向量是离散的,换句话说,它最后得到的编码向量的每个元素都是一个整数,这也就是“Quantised”的含义,我们可以称之为“量子化”(跟量子力学的“量子”一样,都包含离散化的意思)。 明明整个模型都是连续的、可导的,但最终得到的编码向量却是离散的,并且重构效果看起来还很清晰(如文章开头的图),这至少意味着VQVAE会包含一些有意思、有价值的技巧,值得我们学习一番。 首先,VQVAE其实就是一个AE(自编码器)而不是VAE(变分自编码器),我不知道作者出于什么目的非得用概率的语言来沾VAE的边,这明显加大了读懂这篇论文的难度。其次,VQVAE的核心步骤之一是StraightThrough Estimator,这是将引变量离散化后的优...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...
Large Model
2026-01-11

模型概述 KimiVL 是一个高效的开源混合专家视觉语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(KimiVLA3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等. 模型架构 KimiVL 的架构由三个主要部分组成: MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters 视觉模型 400M nativeresolution MoonViT vision encoder. MLP Projector MoonViT: 原生...
Large Model
2026-01-11

UITARS 简介 UITARS(User Interface Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型: 输入方式:仅使用屏幕截图作为视觉输入 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等) 模型特性:端到端的原生智能体模型,无需复杂的中间件或框架 传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: 平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。 模块化...
Large Model
2026-01-11

Chameleon:生成理解统一模型的开山之作 🔖 https://arxiv.org/pdf/2405.09818 Chameleon 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。完整记录了为实现 mixedmodal 模型的架构设计,稳定训练方法,对齐的配方。并在一系列全面的任务上进行评估:有纯文本任务,也有图像文本任务 (视觉问答、图像字幕),也有图像生成任务,还有混合模态的生产任务。 如下图所示,Chameleon 将所有模态数据 (图像、文本和代码) 都表示为离散 token,并使用统一的 Transformer 架构。训练数据是交错混合模态数据 ∼10T token,以端到端的方式从头开始训练。文本 token 用绿色表示,图像...