Large Model
2026-01-11
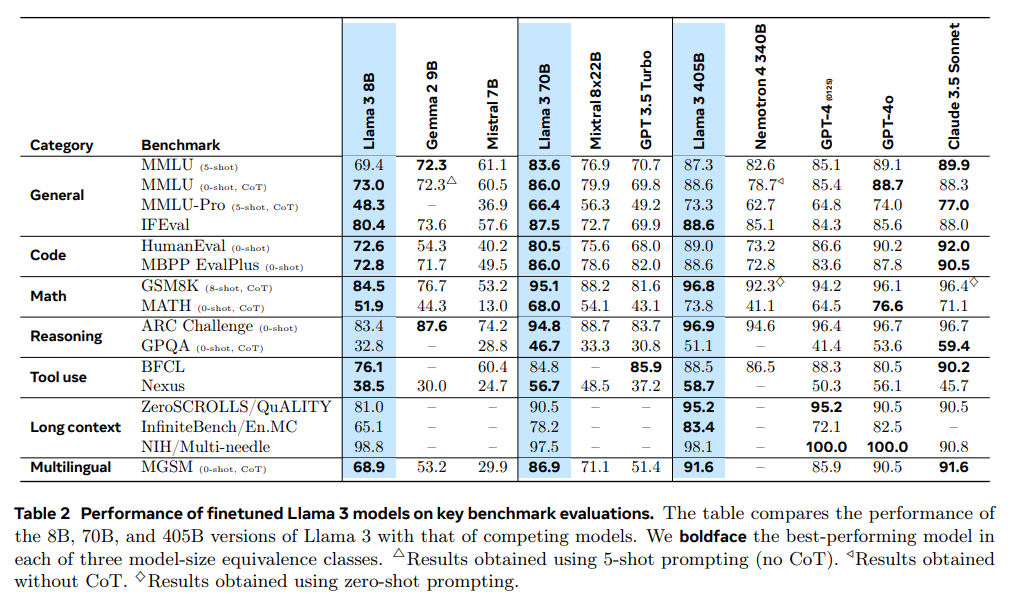
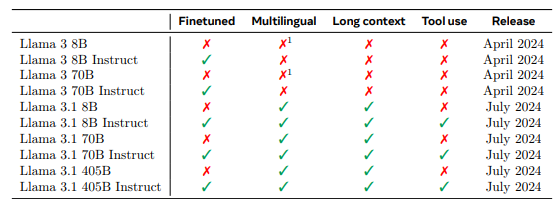
🔖 https://ai.meta.com/research/publications/thellama3herdofmodels/ 简介 本文归纳llm的训练分为两个主要阶段: 预训练阶段 pretraining,模型通过使用简单的任务如预测下一个词或caption进行大规模训练 后训练阶段 posttraining,模型经过调整以遵循指令、与人类偏好保持一致,并提高特定能力, 例如编码和推理。 Llama 3.1 发布,在 15.6T 多语言 tokens 上训练,支持多语言,编程,推理和工具使用。新模型支持 128K tokens 长度的上下文。最大的旗舰模型参数量为 405B,效果达到了闭源模型的 SOTA。 模型结构 Llama 3.1 的模型和 Llama 3 是一样的,只是做了...