Self-Supervised
2026-01-22
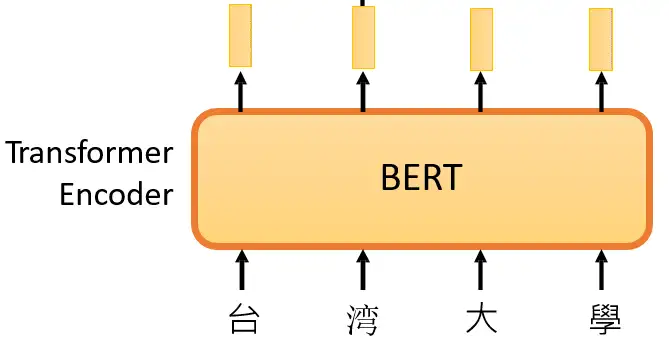
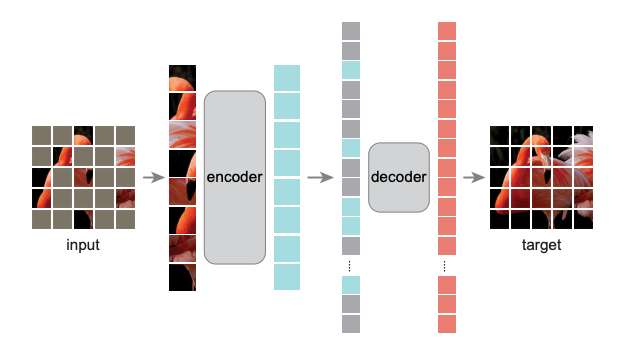
BERT 方法回顾 在 大规模预训练模型BERT 里面我们介绍了 BERT 的自监督预训练的方法,BERT 可以做的事情也就是Transformer 的 Encoder 可以做的事情,就是输入一排向量,输出另外一排向量,输入和输出的维度是一致的。那么不仅仅是一句话可以看做是一个sequence,一段语音也可以看做是一个sequence,甚至一个image也可以看做是一个sequence。所以BERT其实不仅可以用在NLP上,还可以用在CV里面。所以BERT其实输入的是一段文字,如下图所示。 BERT的架构就是Transformer 的 Encoder 接下来要做的事情是把这段输入文字里面的一部分随机盖住。随机盖住有 2 种,一种是直接用一个Mask 把要盖住的token (对中文来说就是一个字)给Mask掉,具体是换成一个 特殊的字符 。另一种做法是把这个token替换成一个随机的token。 把这段输入文字里面的一部分随机盖住 具体BERT详情可以参考: 大规模预训练模型BERT BERT 可以直接用在视觉任务上吗? 上面的 BERT 都是在 NLP 任务上使用,因为 NLP...