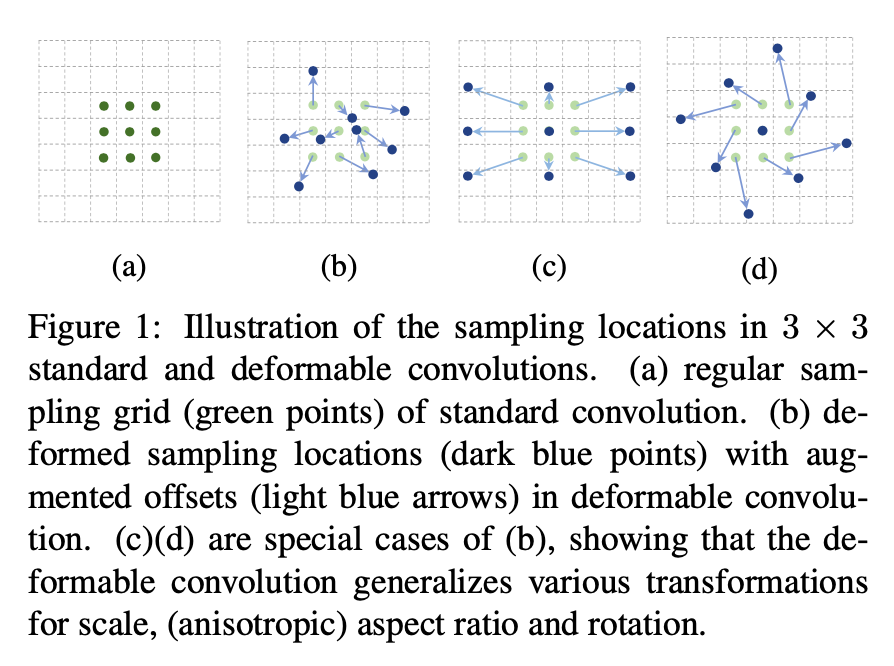
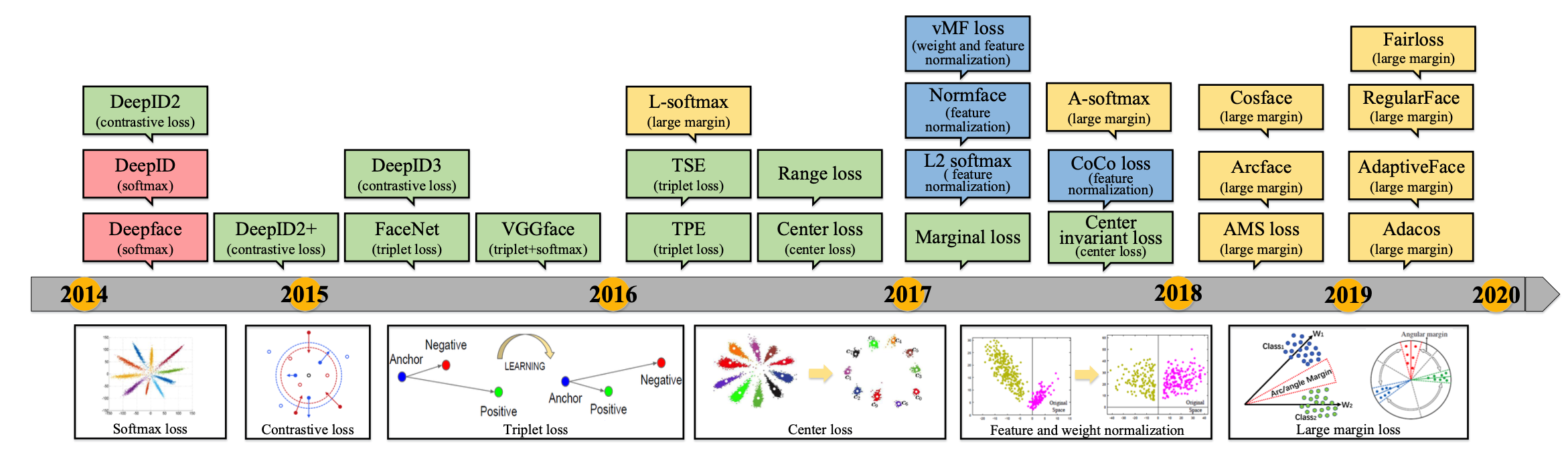
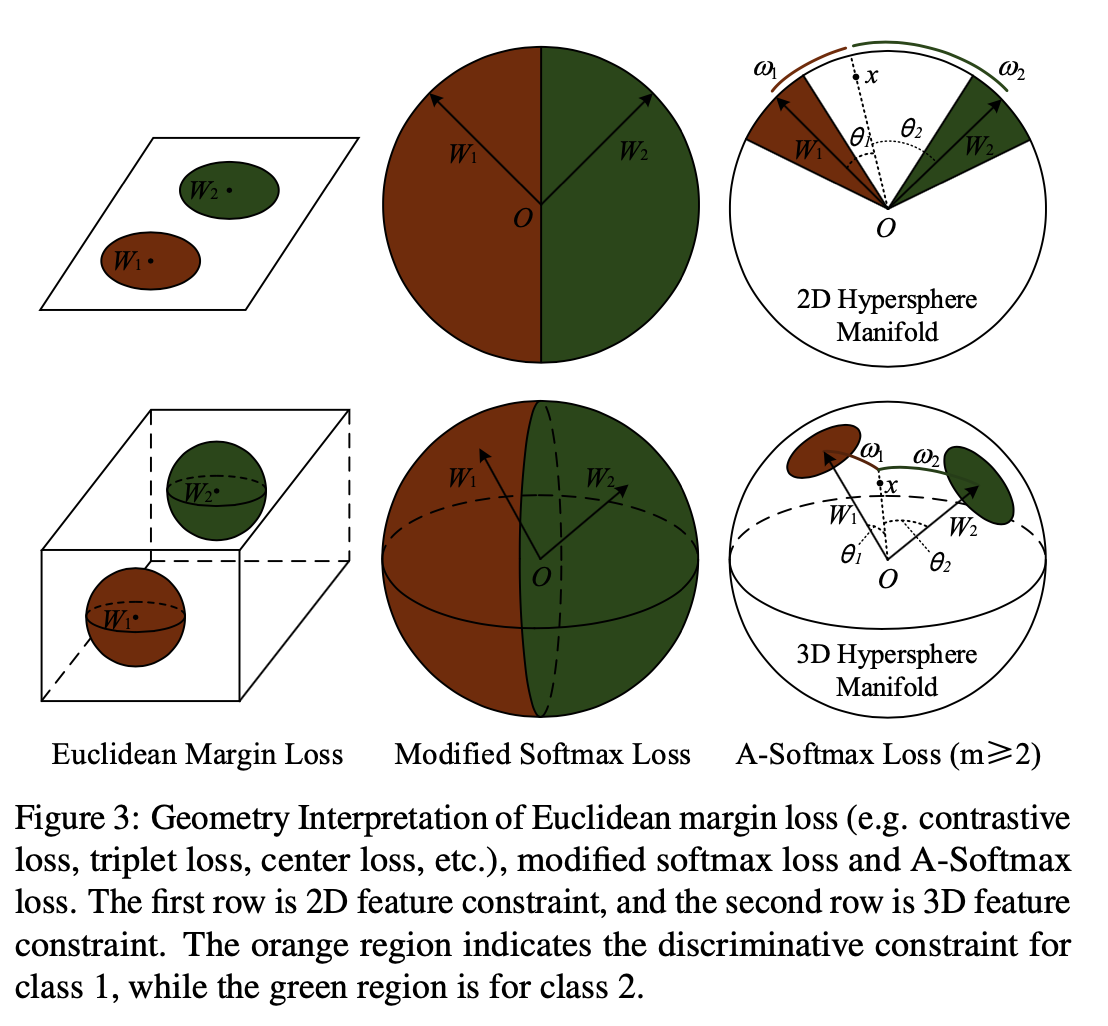
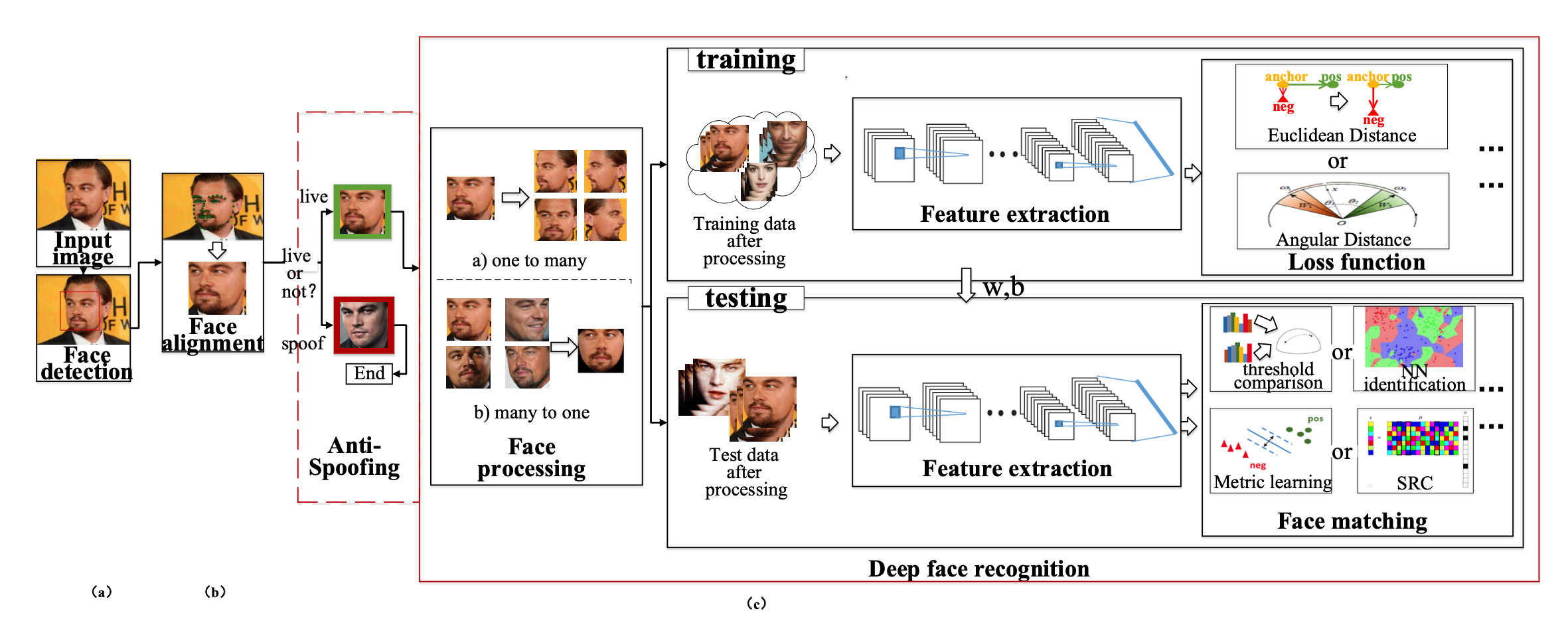
Computer Vision
2026-01-11
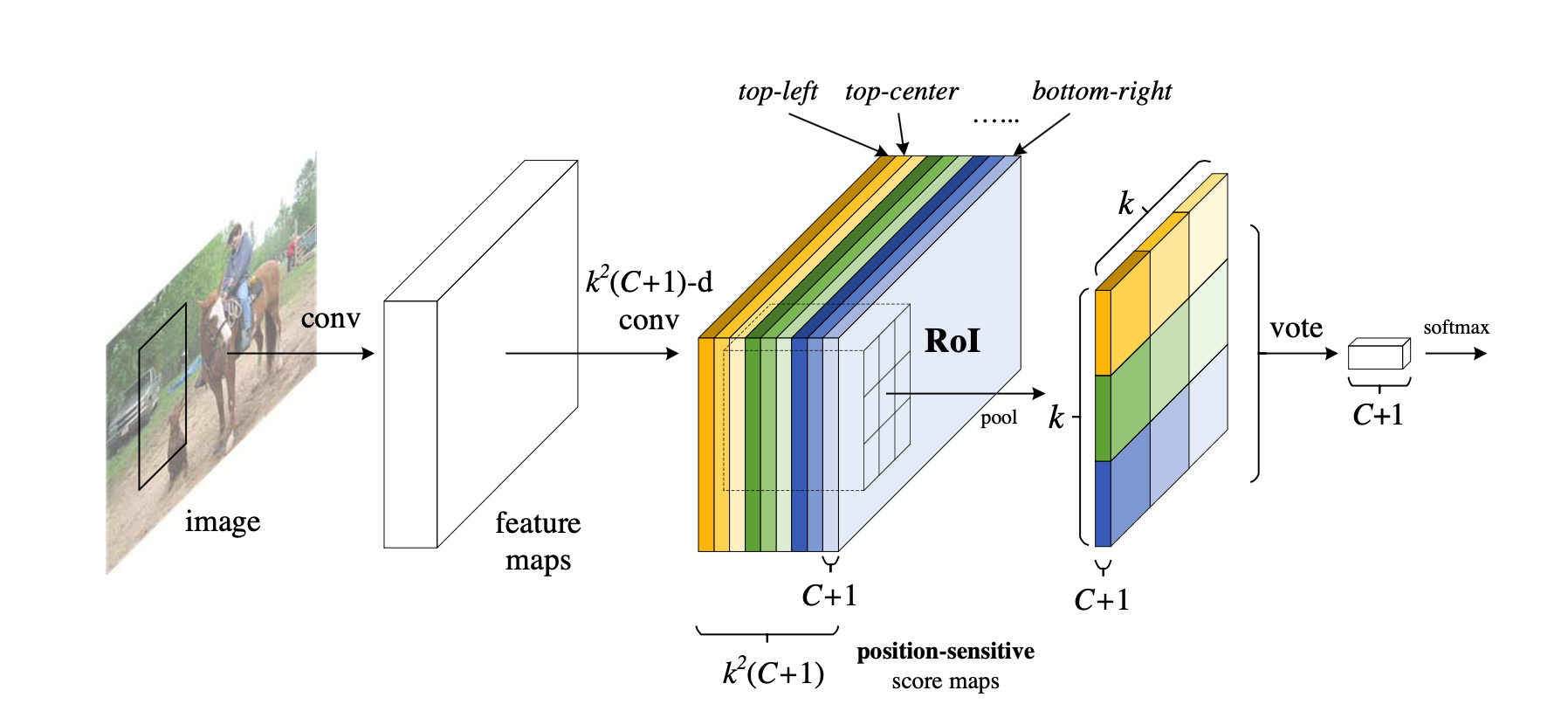
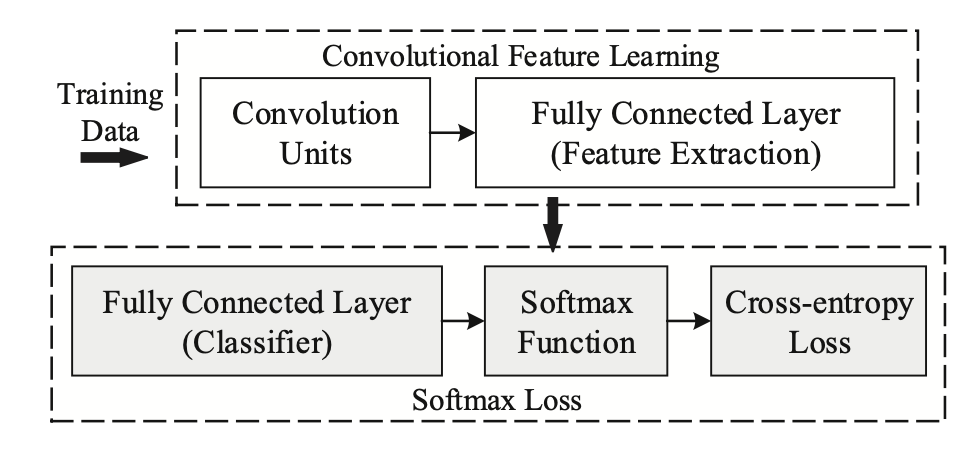
动机 Faster RCNN是首个利用CNN来完成proposals的预测的,之后的很多目标检测网络都是借助了Faster RCNN的思想。而Faster RCNN系列的网络都可以分成2个部分: 1. Fully Convolutional subnetwork before RoI Layer 1. RoIwise subnetwork 第1部分就是直接用普通分类网络的卷积层,用其来提取共享特征,然后一个RoI Pooling Layer在第1部分的最后一张特征图上进行提取针对各个RoIs的特征向量(或者说是特征图,维度变换一下即可),然后将所有RoIs的特征向量都交由第2部分来处理(分类和回归),而第二部分一般都是一些全连接层,在最后有2个并行的loss函数:softmax和smooth...