
Pycharm 的图形化界面虽然好用,但是在某些场景中,是无法使用的。而 Python 本身已经给我们提供了一个调试神器 pdb. 准备文件 在调试之前先将这两个文件准备好(做为演示用),并放在同级目录中。 utils.py [代码] pdb_demo.py [代码] 进入调试模式 主要有两种方法 做为脚本调用,方法很简单,就像正常执行python脚本一样,只是多加了m pdb [代码] 使用这个方式进入调试模式,会在脚本的第一行开始单步调试。 对于单文件的脚本并没有什么问题,如果是一个大型的项目,项目里有很多的文件,使用这种方式只能大大降低我们的效率。 一般情况下,都会直接在你需要的地方打一个断点,那如何打呢? 只需在你想要打断点的地方加上这两行。 [代码] 然后执行时,也不需要再指定m ...
Python
2026-01-11
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程。在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现 python2中经典类和新式类的继承方式不同,经典类采用深度优先搜索的继承,新式类采用的是广度优先搜索的继承方式 python3中经典类和新式类的继承方式都采用的是都采用广度优先搜索的继承方式 [代码] [代码] 举个例子来说明:现有4个类,A,B,C,D类,D类继承于B类和C类,B类与C类继承于A类。class D(B,C) 实例化D类 深度优先 现在构造函数的继承情况为: 若D类有构造函数,则重写所有父类的继承 若D类没有构造函数,B类有...
Python
2026-01-11
Python程序中存储的所有数据都是对象,每一个对象有一个身份,一个类型和一个值。 看变量的实际作用,执行a = 8 这行代码时,就会创建一个值为8的int对象。 变量名是对这个"一个值为8的int对象"的引用。(也可以简称a绑定到8这个对象) 1、可以通过id()来取得对象的身份 这个内置函数,它的参数是a这个变量名,这个函数返回的值 是这个变量a引用的那个"一个值为8的int对象"的内存地址。 [代码] 2、可以通过type()来取得a引用对象的数据类型 [代码] 3、对象的值 当变量出现在表达式中,它会被它引用的对象的值替代。 总结:类型是属于对象,而不是变量。变量只是对对象的一个引用。 对象有可变对象和不可变对象之分。 Python函数传递参数到底是传值还是引用? 传值、引用这个是c...
Search&Rec
2026-01-11
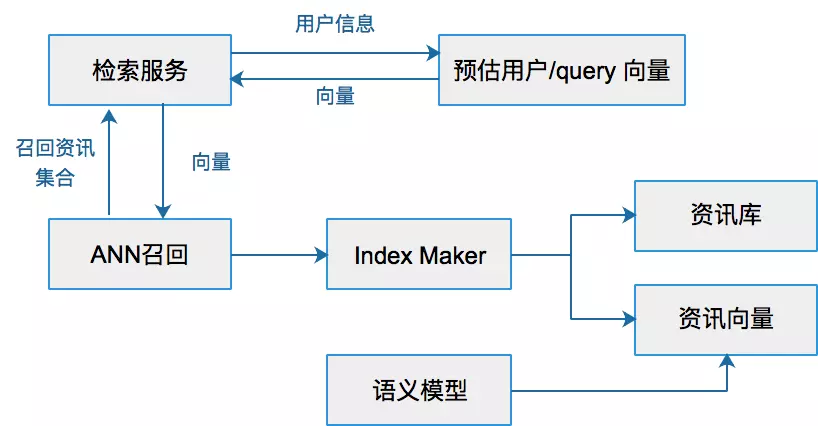
1. 概述 新闻推荐系统从海量新闻中推荐出你感兴趣的新闻,百度从海量的搜索结果中找到最优的结果,短视频推荐出你每天都停不下来的视频流,这些里面都包含ANN方法。当然,在现在的检索系统中,往往是多分支并行触发的效果,虽然DNN 大行其道,但是 ANN 一直不可或缺。 通用理解上,ANN(Approximate Nearest Neighbor)是在向量空间中搜索向量最近邻的优化问题。目前业界常用nmslib、Annoy算法作为实现。在实际的工程应用中,ANN是作为一种向量检索技术应用,用于解决长尾Query召回问题。将一个资讯的ANN 召回系统抽象出来大概是下面的样子。 Ann(approximate nearest neighbor)是指一系列用于解决最近邻查找问题的近似算法。最近邻查找问题...
Search&Rec
2026-01-11
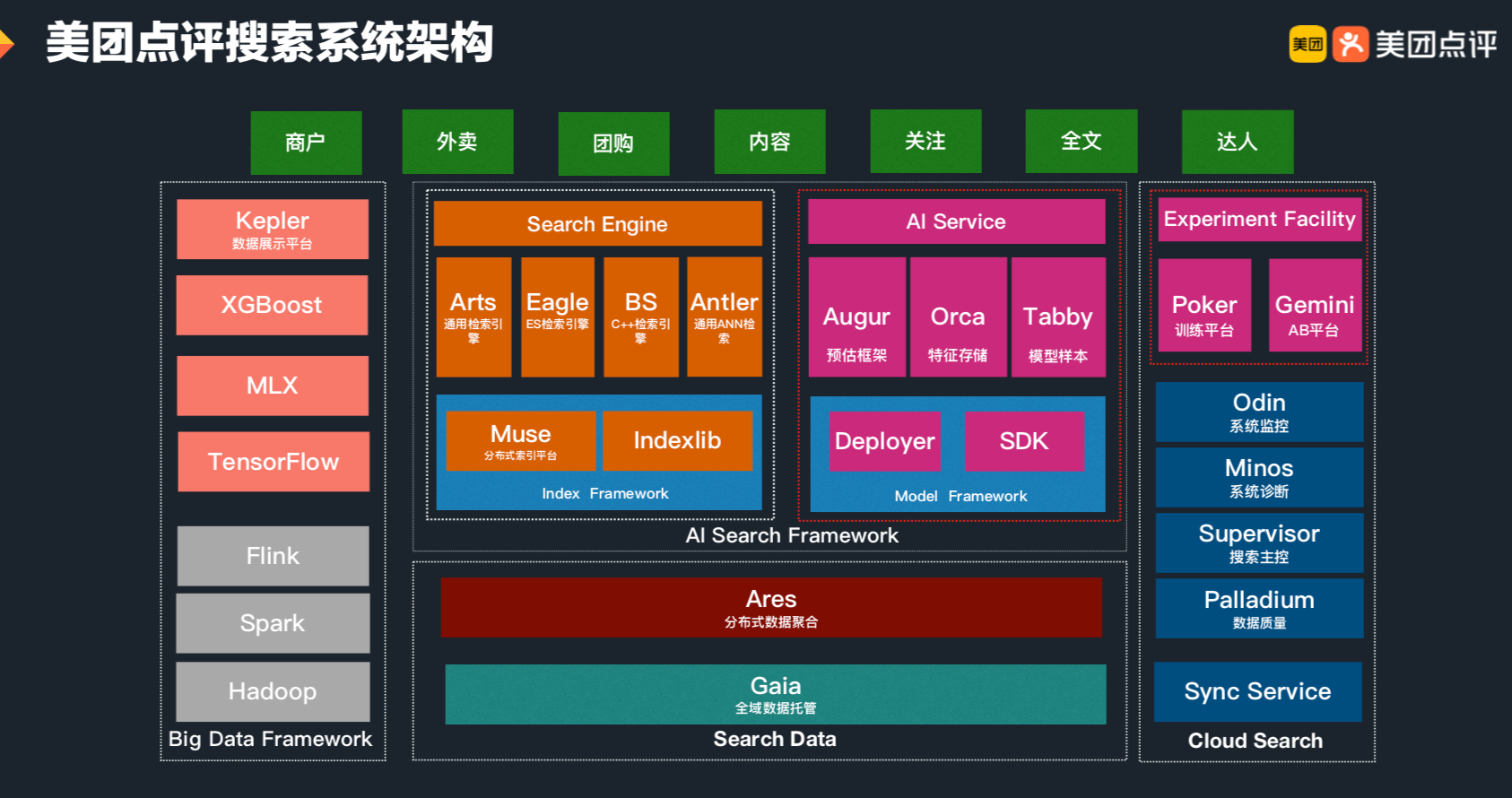
当前,美团搜索整体架构主要由搜索数据平台、在线检索框架及云搜平台、在线AI服务及实验平台三大体系构成。在AI服务及实验平台中,模型训练平台Poker和在线预估框架Augur是搜索AI化的核心组件,解决了模型从离线训练到在线服务的一系列系统问题,极大地提升了整个搜索策略迭代效率、在线模型预估的性能以及排序稳定性,并助力商户、外卖、内容等核心搜索场景业务指标的飞速提升。 首先,美团App内的一次完整的搜索行为主要涉的技术模块。如下图所示,从点击输入框到最终的结果展示,从热门推荐,到动态补全、最终的商户列表展示、推荐理由的展示等,每一个模块都要经过若干层的模型处理或者规则干预,才会将最适合用户(指标)的结果展示在大家的眼前。 为了保证良好的用户体验,技术团队对模型预估能力的要求变得越来越高,同时模...
Search&Rec
2026-01-11
1.倒排索引召回 1)召回模型有三种: 1.基于行为的召回:根据用户的购买行为推荐相关/相似的商品;(长期行为和实时行为) 2.基于用户偏好的召回:用户画像和多屏互通(移动端到PC端); 3.基于地域的召回; 4.基于搜索词的召回(倒排索引); 2)倒排索引 倒排是指由属性值来确定记录的位置。 倒排索引由单词词典和倒排文件组成, 单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。 倒排文件记录所有单词的倒排列表顺序。 好处是在找含有该词的文件时,不需要扫描所有文件,而只需要在单词词典中找到该词,然后找到该词对应的倒排列表即可。 Lucene倒排步骤: 1.取得关键词; 2.建立倒排索引;lucene将上面三列分别作为...
Search&Rec
2026-01-11

一句话总结 正排索引:一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。 倒排索引:Inverted index,指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。 倒排索引创建索引的流程 形成文档列表 首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表。 创建倒排索引列表 对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。保存包含这些词条的文档的编号信息。 搜索的过程 当用户输入任意的词条时,首先对用户输入的数据进行分词,得到用户要搜索的所有词条,然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。 然后根据这些编号去文档列表中找到文档 正排和倒排 正...
Computer Vision
2026-01-11

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zeroshot 和 fewshot能力,结合prompt engineering和fine ...
Computer Vision
2026-01-11
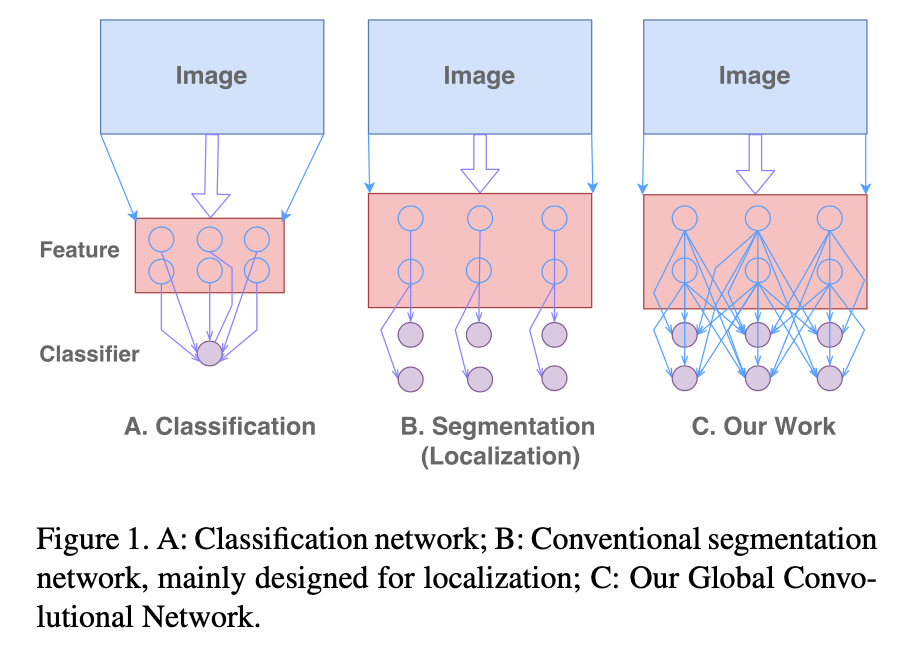
CVPR2017 算法 Global Convolutional Network(GCN),江湖人送外号“Large Kernel”。 Motivation GCN 主要将 Semantic Segmentation分解为:Classification 和 Localization两个问题。但是,这两个任务本质对特征的需求是矛盾的,Classification需要特征对多种Transformation具有不变性,而 Localization需要对 Transformation比较敏感。但是,普通的 Segmentation Model大多针对 Localization Issue设计,正如图(b)所示,而这不利于 Classification。 所以,为了兼顾这两个 Task,本文提出了两个...
Search&Rec
2026-01-11
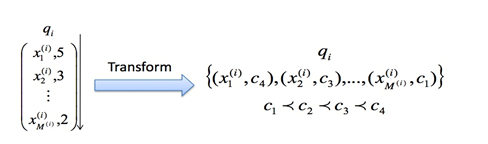
Learning to rank 排序学习是推荐、搜索、广告的核心方法。排序结果的好坏很大程度影响用户体验、广告收入等。排序学习可以理解为机器学习中用户排序的方法,这里首先推荐一本微软亚洲研究院刘铁岩老师关于LTR的著作,Learning to Rank for Information Retrieval,书中对排序学习的各种方法做了很好的阐述和总结。我这里是一个超级精简版。 排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。常用的排序学习分为三种类型:PointWise,PairWise和ListWise。 PointWise 单文档方法的处理对象是单独的一篇文档,将文档...